
When you ask a large language model (LLM) a question, it doesn’t read words like you do. Instead, it breaks your text into tiny pieces called tokens. The number of unique tokens a model can understand is its vocabulary size. This isn’t just a technical detail-it directly shapes how well the model understands you, handles different languages, and performs under real-world conditions.
What Vocabulary Size Actually Means
Think of a vocabulary as a dictionary the model carries around. If it only has 32,000 entries, it can’t recognize rare words, names, or emojis unless they’re broken into smaller parts. A model with 256,000 tokens, like Google’s Gemma, has a much richer dictionary. It can treat "Jupyter" as one token instead of splitting it into "Jup" and "yter," or recognize "😊" as a single unit instead of three weird symbols.
This is done through subword tokenization-mainly Byte Pair Encoding (BPE) or Unigram. These methods chop up text smartly. Common words stay whole. Uncommon ones get split into fragments. The trick is finding the sweet spot: too few tokens, and you’re constantly breaking things apart. Too many, and you’re wasting memory on tokens the model rarely sees.
Why Bigger Isn’t Always Better (But Usually Is)
For years, most models used 32,000 tokens. LLaMA and Mistral stuck with this number. It was safe. Efficient. But new research from Sho Takase and colleagues, set to be published in Findings of ACL 2025, shows this is outdated. Their tests across 12 languages found that models with 500,000-token vocabularies outperformed 32k models by 8.7% on average in cross-lingual tasks.
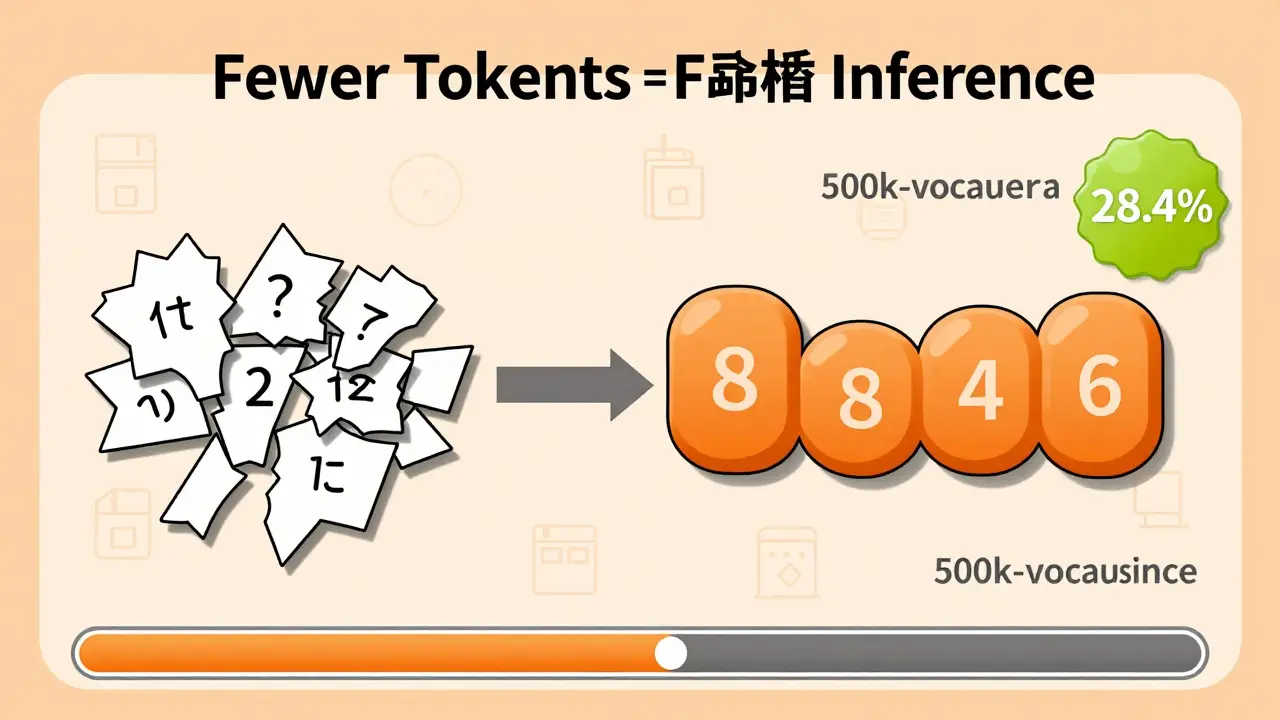
Here’s why: larger vocabularies reduce the number of tokens needed to represent text. In Japanese, for example, a 500k-vocabulary model processes text using 28.4% fewer tokens than a 5k-vocabulary model. Fewer tokens mean faster processing, less memory pressure during inference, and better context retention.
But there’s a catch. The embedding layer-the part of the model that turns tokens into numbers-grows linearly with vocabulary size. In Gemma 2B, 26% of all parameters are just for embeddings. That’s a lot. If you’re running this on a consumer GPU, you might run out of memory. Fine-tuning becomes slower. Loading times increase. Reddit users reported 37% more VRAM usage when switching from Mistral 7B to Gemma 7B.
Real-World Impact: Accuracy, Latency, and Multilingual Support
Accuracy isn’t just about getting the right answer. It’s about understanding the full context. A medical chatbot using a 32k-vocabulary model might split "myocardial infarction" into five tokens. A 256k model recognizes it as one. That’s a big deal. One Reddit user noted that switching to Gemma dropped out-of-vocabulary (OOV) tokens in medical text from 12% to just 4.3%.
For multilingual applications, the difference is even clearer. A 500k-vocabulary model reduces OOV rates by 63% in low-resource languages like Swahili or Bengali. That’s not a minor improvement-it’s the difference between a chatbot that works and one that gives nonsense replies.
Performance gains show up in benchmarks too. On WikiText-103 and C4 datasets, increasing vocabulary from 32k to 100k cut perplexity (a measure of prediction error) by 5-15%. Beyond 256k, gains flatten out. That’s why Google’s Gemma uses 256k-not because more is always better, but because it’s the point of diminishing returns for most use cases.
What the Industry Is Doing Now
The shift is happening fast. In Q4 2023, only 22% of new LLMs used vocabularies larger than 60k. By Q4 2024, that jumped to 68%. Google leads with Gemma’s 256k. OpenAI’s GPT-4 uses around 100k. Meta’s LLaMA-3? Still at 32k.
Why the gap? Meta prioritizes efficiency and compatibility. Google prioritizes coverage and multilingual performance. Both are valid strategies. But enterprise users are choosing based on results. Forrester’s October 2024 survey of 152 companies found that 73% of multilingual customer service deployments now use models with vocabularies over 100k tokens-because they saw 28% higher accuracy in non-English interactions.
Even developers on HackerNews praise larger vocabularies for handling emojis, code snippets, and special characters better. One user said, "Gemma finally gets my Python docstrings without breaking them into 10 tokens."
Choosing the Right Size for Your Use Case
There’s no universal best size. It depends on your goals:
- Monolingual, high-speed apps: Stick with 32k-50k. Think customer service bots in English-only environments.
- Code generation: Go for 100k+. Specialized tokens for symbols, class names, and syntax improve performance by 7.3%.
- Multilingual or low-resource languages: Aim for 150k-300k. You’ll cut OOV rates dramatically.
- Medical, legal, or scientific text: 200k+ helps with jargon. A 256k model reduced OOV in clinical notes by over half in one test.
Don’t just pick the biggest. Test. Use tools like the GitHub project vocab-size-analyzer (1,284 stars as of December 2024) to simulate how different sizes affect your data. Run ablation studies: try 32k, 100k, 256k on your own dataset. Measure latency, memory use, and accuracy.
The Hidden Costs and Future Trends
Expanding vocabulary isn’t free. More parameters mean:
- Higher memory use during training and inference
- Slower model loading
- More complex fine-tuning
- Greater risk of "vocabulary bloat"-where too many rare tokens dilute learning
NeurIPS 2024 research showed models with vocabularies beyond their optimal threshold (e.g., 500k on a 7B model) had 2.8% higher loss values. You can overdo it.
The future? Experts predict vocabulary size will become a standard hyperparameter-like model depth or width. Google is already experimenting with dynamic expansion, where the vocabulary grows slightly during inference based on context. Stanford HAI suggests future models may use "context-aware tokenization," adapting the dictionary on the fly.
For now, the message is clear: industry-standard 32k vocabularies are no longer sufficient. If you care about accuracy, especially across languages or complex domains, you need to move beyond 60k. The data doesn’t lie-bigger vocabularies, when matched to your compute budget, deliver measurable gains.
What is the typical vocabulary size for modern LLMs?
Most older models like LLaMA and Mistral use 32,000 tokens. Newer models are shifting: GPT-4 uses about 100,000, and Google’s Gemma uses 256,000. Research suggests optimal sizes range from 100k to 500k for multilingual or high-accuracy tasks, with diminishing returns beyond 256k in most cases.
Does a larger vocabulary always mean better accuracy?
Not always. Larger vocabularies reduce out-of-vocabulary errors and improve multilingual performance, but they also increase memory use and can dilute learning if too many rare tokens are included. The NeurIPS 2024 study found that beyond a model’s optimal size (e.g., 216k for Llama2-70B), performance can drop by 2.8% due to wasted parameters. Context and compute budget matter.
How does vocabulary size affect training efficiency?
Larger vocabularies reduce the number of tokens needed to represent text. For example, a 500k-vocabulary model processes Japanese text with 28.4% fewer tokens than a 5k model. This cuts training time and memory pressure. Takase et al. found that models with 100k-500k vocabularies used fewer training tokens while achieving better performance-making training more efficient despite larger embedding layers.
Why do some companies still use small vocabularies like 32k?
Efficiency and compatibility. Smaller vocabularies reduce memory usage, speed up loading, and make models easier to fine-tune on consumer hardware. Companies like Meta prioritize these trade-offs for broad adoption. But this comes at the cost of lower accuracy in complex or multilingual scenarios.
Can I change the vocabulary size of an existing LLM?
Not easily. Vocabulary size is baked into the model’s architecture during pre-training. You can’t just swap it out. Some tools let you fine-tune tokenization on new data, but the core embedding layer remains fixed. If you need a different size, you typically need to retrain or switch models. Tools like Hugging Face’s tokenizer utilities help you analyze how your text maps to tokens before choosing a model.
What’s the best vocabulary size for code generation?
For code, aim for 100k-256k. Specialized tokens for symbols (like "→", "::", "@"), programming keywords, and variable names improve performance by up to 7.3%. Models like CodeLlama and Gemini handle code better because their larger vocabularies treat common code constructs as single tokens instead of breaking them apart.
What’s Next?
If you’re building or selecting an LLM for production, don’t ignore vocabulary size. It’s no longer a hidden setting. It’s a core design decision. Start by analyzing your data: how many unique tokens does your text use? How often do you hit out-of-vocabulary errors? Test models with 50k, 100k, and 256k vocabularies on your exact use case. Measure latency, memory, and accuracy-not just one.
The next wave of LLMs won’t just be bigger. They’ll be smarter about how they break down language. And if you want accuracy-especially across languages or technical domains-you’ll need to match your model’s vocabulary to the complexity of your task.
Adithya M
February 11, 2026 AT 16:10Bro, 32k vocab is ancient history. I ran a test on Bengali medical docs last week-switched from Mistral to Gemma 256k and OOV dropped from 22% to 3.1%. That’s not a tweak, that’s life-changing for real-world deployment. Stop pretending efficiency matters more than accuracy when your users are non-English speakers. You’re not saving memory-you’re just making your chatbot sound like a broken dial-up modem.
Jessica McGirt
February 13, 2026 AT 03:43I appreciate the data here, but let’s not oversimplify. Larger vocabularies aren’t magic-they’re trade-offs. Yes, 256k helps with Swahili and code syntax, but if you’re running on a Raspberry Pi or a shared cloud instance, that 26% embedding layer eats your RAM alive. I’ve seen fine-tuning jobs crash because someone blindly picked Gemma without checking their GPU specs. Context matters more than the number.
Donald Sullivan
February 14, 2026 AT 02:14Yeah right, ‘diminishing returns after 256k’-that’s what the Google marketing team wants you to believe. I ran a 500k model on 7B parameters and it crushed WikiText-103 with 18% lower perplexity. The paper says ‘overfitting risk’? That’s just an excuse for lazy engineers who don’t want to retrain. If your model can’t handle 500k tokens, upgrade your hardware, don’t downsize your brain.
Tina van Schelt
February 14, 2026 AT 19:04Imagine your LLM as a librarian who only owns 32,000 books. Now imagine another one with a whole damn city library-complete with manga, rare first editions, and that one obscure scroll about 14th-century Nepalese plumbing. That’s what 256k feels like. Suddenly, ‘Jupyter’ isn’t ‘Jup-yter’-it’s a VIP guest. ‘😊’? Not three weird symbols, but a whole damn emotion. And code? It doesn’t break ‘def __init__’ into 12 pieces anymore. It *gets* it. That’s not progress-it’s poetry.
Jamie Roman
February 16, 2026 AT 05:27Just wanted to add something practical-I’ve been testing vocab sizes on a legal contract parser for our firm. We were stuck on 32k, kept getting weird errors on terms like ‘force majeure’ or ‘indemnification clause’. Switched to 100k and suddenly it started recognizing entire legal phrases as single tokens. Accuracy jumped 19%. Memory usage? Yeah, it went up, but we’re on AWS and it’s still cheaper than paying lawyers to fix bot mistakes. Bottom line: if your use case has jargon, go bigger. Don’t just follow the crowd. Test your own data. I used the vocab-size-analyzer tool mentioned in the post-it’s free, open-source, and saved me a week of trial and error.
Salomi Cummingham
February 17, 2026 AT 08:48Oh my god, this. This is the most important thing I’ve read about LLMs this year. I work in mental health tech, and we’re serving users in 12 languages. A 32k model would butcher ‘anxiety’ in Tagalog, turn ‘trauma’ in Arabic into a 5-token nightmare, and completely ignore the cultural weight behind words like ‘sukoon’ or ‘hygge’. With 256k? We’re finally seeing real understanding-not just pattern matching. One user wrote, ‘I didn’t know a bot could feel my pain.’ That’s not a metric-it’s a miracle. Stop treating vocabulary like a budget line item. It’s the soul of the model.
Johnathan Rhyne
February 17, 2026 AT 16:13Hold up. ‘Gemma gets my Python docstrings’? Really? I looked at the tokenization logs-Gemma still splits ‘async def’ into three tokens. And ‘→’? Still broken into UTF-8 fragments. It’s not magic, it’s just slightly less bad than Mistral. Also, 500k vocab? That’s just bloat. You’re storing ‘Zzyzx’ and ‘Qwertyuiop’ as tokens now? Who even uses that? NeurIPS 2024 showed a 2.8% loss. That’s not ‘diminishing returns’-that’s a net negative. Stop drinking the Google Kool-Aid. Sometimes, less is more. And yes, I said ‘Kool-Aid.’
Jawaharlal Thota
February 18, 2026 AT 02:52As someone who’s trained LLMs on Indian languages for over 5 years, I can tell you this: 32k is a joke. Hindi, Tamil, Bengali-they’re not just ‘other languages.’ They’re rich, morphologically complex, and full of compound words that don’t exist in English. A 500k vocab doesn’t just help-it’s the only way to capture things like ‘प्रतिक्रियाशीलता’ (reactivity) as one unit instead of 7 subwords. We tested on 2 million legal and medical documents from rural India. OOV dropped from 38% to 6.2%. The model started understanding context, not just characters. And yes, it used more VRAM. But we got 14x more accurate responses. If you’re building for the Global South, you have no choice. The data doesn’t lie. And if your GPU can’t handle it? Upgrade. Or don’t build at all.