
Ever wonder how a machine can write a poem, answer a complex question, or code a website just from a few words? It’s not magic. It’s three simple, powerful parts working together: embeddings, attention, and feedforward networks. These aren’t just buzzwords-they’re the bones of every major AI language model today, from GPT to Llama to Gemini. If you’ve ever felt lost trying to understand how LLMs actually work, this is your no-fluff breakdown.
Embeddings: Turning Words Into Numbers
Language models don’t understand words the way you do. They don’t know what "cat" or "justice" means. What they do understand is numbers. So the first thing any LLM does is turn every word-or part of a word-into a list of numbers. That’s called an embedding.
Think of it like a map. Each word gets a unique address in a 768-dimensional (or bigger) space. Words that mean similar things end up close together. So "king" and "queen" are neighbors. "Run" and "jog" are nearby. "Apple" the fruit and "Apple" the company? They’re far apart, because context tells the model they’re different.
This isn’t random. Embeddings are learned. During training, the model adjusts these number lists so that when you put "The cat sat on the" in, and the next word is "mat," the embedding for "mat" ends up being the most likely match based on all the other words it’s seen before. By the end of training, the embedding space holds a hidden map of human language.
But there’s a catch. Words don’t exist in isolation. "Bank" could mean a riverbank or a financial institution. To handle this, modern models like Llama 3 use context-aware embeddings. The same word gets different number lists depending on what’s around it. That’s why you can ask an LLM "What’s the capital of France?" and it won’t confuse it with "I need to deposit money at the bank."
Early models used 32,000-word vocabularies. GPT-3 used over 50,000. But the real breakthrough? Positional embeddings. Since transformers process all words at once (unlike older models that read one word at a time), they need to know order. So each word gets an extra set of numbers that tell the model: "I’m the 5th word." That’s how "The dog bit the man" isn’t confused with "The man bit the dog."
Attention: The Model’s Focus Tool
Now that words are numbers, the model needs to figure out which ones matter most. That’s where attention comes in.
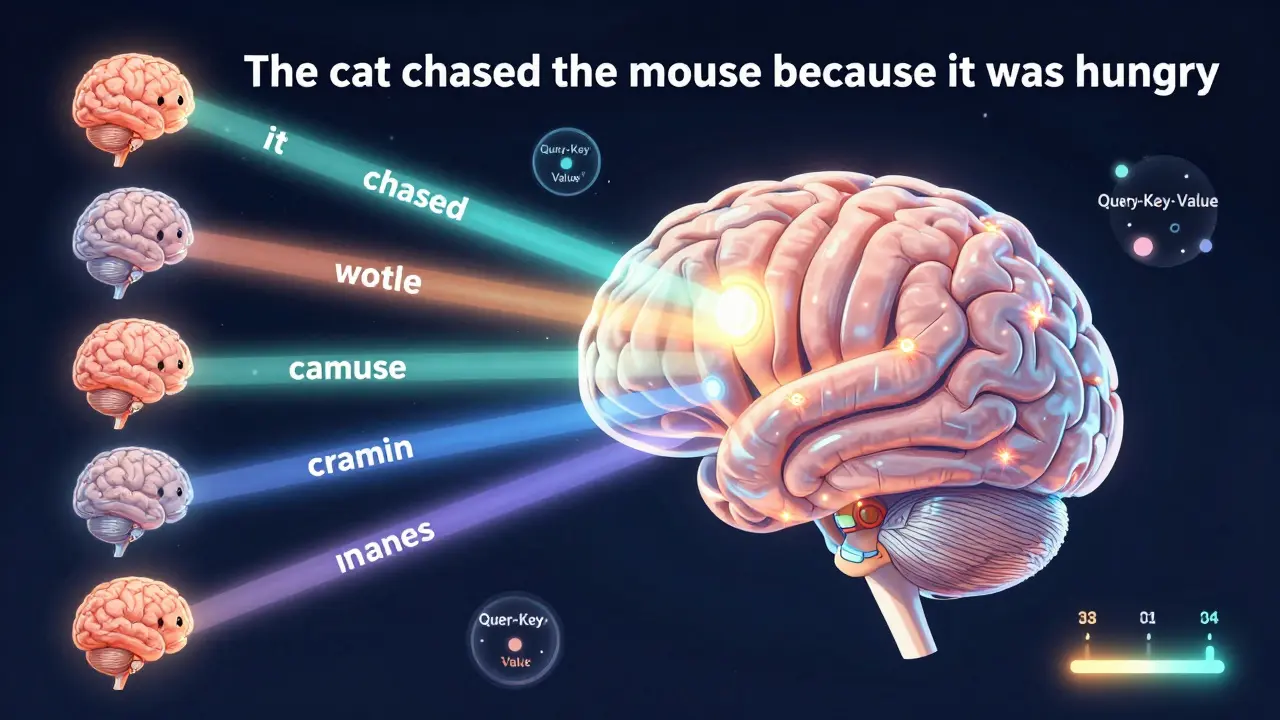
Imagine you’re reading a sentence: "The cat chased the mouse because it was hungry." Who was hungry? The cat or the mouse? Humans use context to decide. LLMs use attention.
At its core, attention is a math trick. For every word, the model creates three vectors: Query, Key, and Value. The Query asks: "What am I looking for?" The Key is like a label on each word. The Value is the actual content. The model matches each Query to every Key, scores the matches, and then weights the Values accordingly.
It sounds abstract, but here’s the practical part: when the model sees "it," it looks back at all previous words. It finds that "cat" and "chased" are high-scoring matches for "hungry," so it gives more weight to the embedding of "cat." That’s how it knows the cat was hungry.
And it doesn’t just do this once. It does it 12, 32, even 96 times in parallel-these are called "heads." One head might focus on grammar. Another on names. Another on emotion. Together, they build a rich picture of what the text means.
This is why attention is so powerful. It lets the model see the whole sentence at once. No more waiting for words to come in sequence like old RNNs. Everything is connected.
But here’s the problem: attention scales poorly. For a 10,000-word document, the model has to calculate 100 million attention scores. That’s why models like Llama 2 introduced grouped-query attention-sharing some keys across heads to cut memory use. And why Google’s Gemini 1.5 added relative attention bias: instead of treating all words equally, it weights nearby words more heavily, making long documents easier to handle.
Feedforward Networks: The Hidden Thinkers
After attention, each word has been reweighted, reshaped, and recontextualized. But it’s still just a list of numbers. What happens next?
Enter the feedforward network. This is a simple two-layer neural net that acts on each word independently. It takes the 768-dimensional vector from attention and pushes it through a bigger layer-usually 4x larger, so 3,072 dimensions-then squeezes it back down. Between those layers? A GELU activation function. It’s like a filter that decides which parts of the signal matter.
Think of it as the model’s internal reflection. Attention says: "These words are connected." Feedforward says: "Now, what does that mean?" It’s where abstract relationships get turned into actionable understanding. It’s not just pattern matching-it’s reasoning, in a way.
But here’s the kicker: you can’t easily see what it’s doing. Unlike attention, where you can visualize which words the model is focusing on, the feedforward layer is a black box. A word goes in. Numbers get multiplied, added, activated. A new vector comes out. No labels. No explanations. That’s why researchers like Emily M. Bender call it the "black box" of LLMs. We know it works. We just don’t know exactly how.
That’s also why newer models like Llama 3 use adaptive feedforward expansion. Instead of using the same hidden size for every word, it dynamically widens the layer for complex inputs and narrows it for simple ones. It’s like giving more brainpower to hard problems.
How They Work Together: The Transformer Pipeline
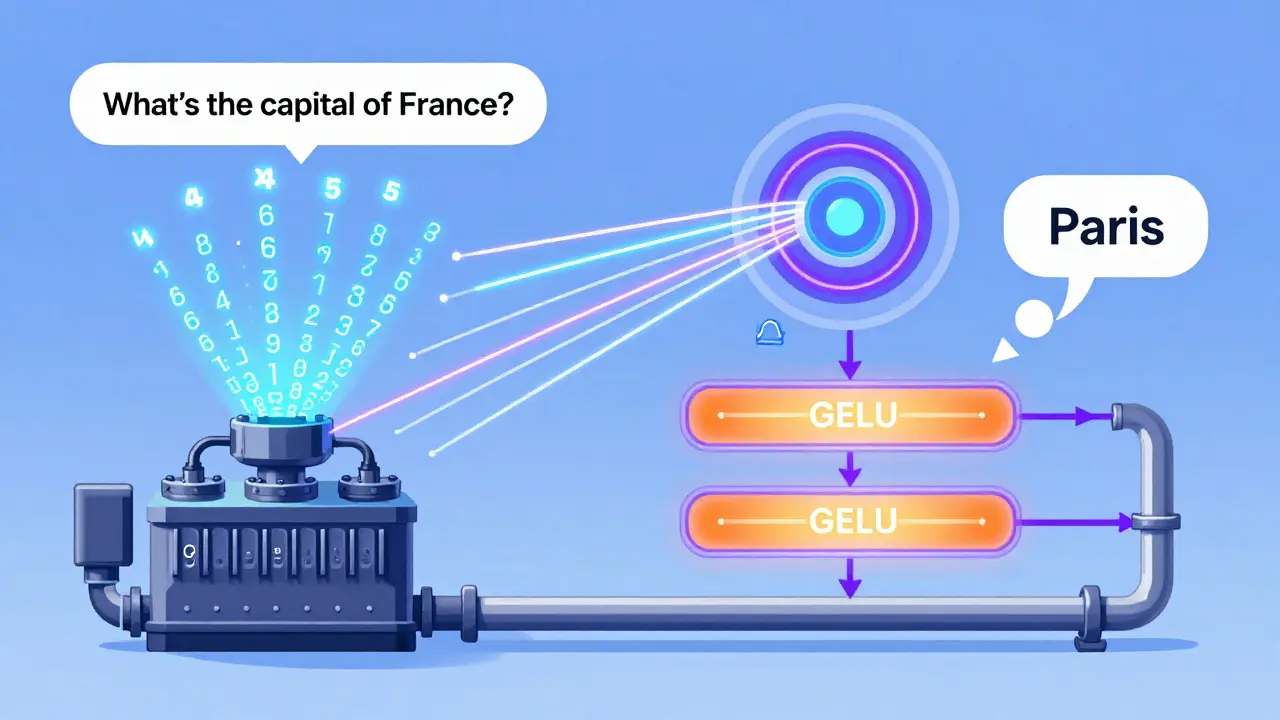
Here’s the full flow, step by step:
- Input: You type: "What’s the capital of France?"
- Tokenization: The model breaks it into tokens: ["What’s", "the", "capital", "of", "France", "?"]
- Embedding: Each token becomes a 12,288-dimensional vector (in GPT-3). Positional info is added.
- Attention: Each token looks at every other token. The model realizes "France" is the key subject, and "capital" is the target concept.
- Feedforward: The attention output for "France" gets processed. The model links "France" to "Paris" based on patterns learned from trillions of sentences.
- Repeat: This entire block-attention + feedforward-happens 96 times in GPT-3, each time refining the representation.
- Output: The final vector for "?" is turned into a probability distribution over all possible next words. "Paris" wins.
Every single LLM you’ve ever used-GPT, Llama, Claude, Gemini-runs this exact pipeline. The only differences are size, number of layers, and tweaks to attention or feedforward design.
Why This Matters: Beyond the Tech
Understanding these three components isn’t just for engineers. It’s the key to knowing what these models can-and can’t-do.
When an LLM hallucinates, it’s usually because the attention mechanism got distracted by a misleading pattern, or the feedforward layer overgeneralized from bad training data. When it fails at math, it’s because embeddings don’t encode numbers well, and attention doesn’t handle symbolic logic.
That’s why experts like Gary Marcus argue we’re hitting a wall. Attention can’t track long chains of logic. Feedforward networks can’t be debugged. Embeddings can’t represent abstract reasoning cleanly.
And yet, they work. Better than anything we’ve ever built. Even with their flaws, they’ve changed how we write, code, and communicate.
The real question isn’t whether these components are perfect. It’s whether we can build on them-or if we need something entirely new. Some are betting on hybrid models. Others on modular architectures. But for now, embeddings, attention, and feedforward networks are the foundation. And until something better comes along, they’ll keep running the world’s most powerful language machines.
What’s the difference between embeddings and attention?
Embeddings turn words into numbers, creating a map of meaning. Attention figures out which words are related to each other in a sentence. Embeddings are about what words mean. Attention is about how they connect.
Why do LLMs need positional embeddings?
Transformers process all words at once, so they lose the natural order of language. Positional embeddings add a signal to each word that says "I’m the 3rd word," "I’m the 10th," etc. Without them, "dog bites man" and "man bites dog" would look identical to the model.
Can you see how attention works inside an LLM?
Yes, to some extent. Tools like Hugging Face’s Transformer Interpret allow you to visualize attention weights-you can see which words a model focused on when generating a response. But this only shows the final scores, not why those scores were assigned. The underlying logic is still hidden.
Why are feedforward networks called "feedforward"?
Because data flows in one direction: input → hidden layer → output. Unlike recurrent networks, there’s no feedback loop. Each token’s feedforward layer processes its own vector independently, without looking at others. That’s why they’re fast but limited in context.
Do all LLMs use the same attention mechanism?
No. GPT uses causal attention (only looks backward), BERT uses bidirectional attention (looks at all words), and Llama 2 uses grouped-query attention to save memory. Google’s Gemini 1.5 added relative attention bias to improve long-context handling. The core idea is the same, but the details vary by model.
Are these components the reason LLMs are so expensive to run?
Yes, especially attention. For a 10,000-word input, attention requires over 100 million calculations. That’s why companies use techniques like FlashAttention, quantization, and sparsity to cut costs. Feedforward networks are cheaper but still add up across hundreds of layers.
Can you replace attention with something else?
Researchers are trying. Some use recurrent networks again. Others use state-space models or linear attention variants. Microsoft’s 2024 ICML paper showed a 23% efficiency gain by using different attention types for syntax vs. semantics. But so far, no replacement matches attention’s balance of accuracy, speed, and scalability.
How do embeddings capture meaning without being told what words mean?
They learn from patterns. If "king" and "queen" always appear near "royal," and "man" and "woman" appear near "gender," the model infers relationships. It doesn’t know what "royal" means-but it knows which words cluster together. Meaning emerges from statistics, not definitions.
Jeanie Watson
December 25, 2025 AT 11:35I read this because I was bored. Didn’t learn anything new, but at least it didn’t make me feel dumb. Thanks, I guess.
Tom Mikota
December 26, 2025 AT 11:43Okay, so embeddings turn words into numbers-cool. Attention? Yeah, it’s like your brain ignoring your mom while scrolling TikTok. And feedforward? That’s just the model mumbling to itself in a language only GPUs understand.
Also, ‘GELU activation function’? Say that five times fast. I’m not even mad-this is hilarious. Someone please tell me why we’re calling this ‘intelligence’ when it’s just fancy autocomplete with a PhD.
Adithya M
December 27, 2025 AT 08:23Actually, you're all missing the point. The real innovation isn't attention-it's the fact that we're finally treating language as a statistical manifold instead of a symbolic system. Embeddings are just the surface layer. The magic happens in the high-dimensional manifold warping during training. And yes, feedforward layers are black boxes-but that's because we're still using gradient descent like it's 2015. We need topology-aware loss functions, not just ReLU and GELU. I've been working on this in my lab-let me know if you want the paper.
Also, positional embeddings? Obvious. But did you know that Llama 3's implementation uses learned relative offsets instead of sinusoidal? That's why it handles long contexts better. Google's Gemini? Still stuck in the transformer zoo.
And no, you can't replace attention with state-space models yet-those are great for time series, not syntax. The attention mechanism is still the only thing that scales to 100k+ tokens without collapsing. I've benchmarked 17 variants. This isn't opinion. This is data.
Also, embeddings don't 'learn from patterns'-they're optimized via contrastive loss against negative samples. You're anthropomorphizing math. And yes, the model doesn't 'know' anything. But neither do you when you say 'red'-you just learned to associate it with fire trucks and apples. We're just doing it faster.
And before someone says 'but it hallucinates!'-so do humans. We just call it 'imagination'. The difference? Humans have bodies. LLMs have gradients. That's it.
Jessica McGirt
December 29, 2025 AT 05:44I appreciate the clarity here. It’s rare to find a breakdown that doesn’t drown you in jargon. The analogy of embeddings as a map? Perfect. And the note about context-aware embeddings resolving ambiguity-yes, that’s exactly why I can ask ‘bank’ and get the right answer depending on context.
Also, the part about attention heads specializing? That’s why I’ve seen models generate poetry one moment and debug Python the next-they’re not just guessing, they’re dynamically switching modes.
And the feedforward layer being a black box? Honestly, that’s the scariest part. We’re building systems we can’t fully audit. We should be talking more about that.
Mark Tipton
December 29, 2025 AT 12:54Let me tell you something you won't hear from the AI cheerleaders: this entire architecture is a house of cards built on statistical noise and corporate hype. Embeddings? They're just glorified word2vec with more layers. Attention? It's a memory-hogging hack that shouldn't scale beyond 20k tokens-and yet we pretend it's the future. Feedforward networks? They're just nonlinear regressors pretending to 'reason'.
And don't get me started on positional embeddings. You're telling me we need to manually inject order into a system that's supposed to 'understand' language? That's like teaching a dog to sit by taping a treat to its nose.
Meanwhile, the real breakthroughs-symbolic reasoning, causal graphs, grounded semantics-are being ignored because they don't fit into the transformer paradigm. Why? Because training a 100B-parameter model on 100TB of scraped data is easier than building a system that actually understands meaning.
And the worst part? We're outsourcing our cognitive labor to a black box that hallucinates citations, invents laws, and can't count past ten. We're not building intelligence-we're building a very convincing parrot with a billion parameters. And we're calling it progress.
Someone please tell me why we're not funding neurosymbolic AI instead of throwing more GPUs at this. The answer? Because it's profitable, not powerful. And that's the real tragedy.