
When you ask an LLM a question like "What’s my last billing address?", the system doesn’t just process the words. It breaks them down into tiny pieces called tokens-individual words, punctuation, even parts of words. And if you’re not careful, every single one of those tokens gets logged. That means your name, email, phone number, or even your doctor’s notes might end up stored in plain text in a log file somewhere. It’s not a hypothetical risk. In 2025, the European Data Protection Board found that 78% of enterprise LLM systems were logging sensitive data at the token level, putting them in direct violation of GDPR.
Why Token-Level Logging Is a Hidden Privacy Disaster
Most companies think they’re safe if they don’t log entire user inputs. But that’s like thinking your house is secure because you locked the front door-while leaving all the windows wide open. In multi-turn conversations, a user might say "My name is Sarah Johnson, and I live at 123 Maple Street" in turn one. Then in turn five, they ask: "What’s my payment history?". The model doesn’t remember Sarah’s name verbatim-but it remembers the structure of the data. If the system logs tokens like "Sarah", "Johnson", "123", and "Maple" separately, a clever attacker can stitch them back together. This is called contextual re-identification, and it’s happening in real systems right now.Protecto AI’s 2024 study showed that without token-level minimization, 92% of privacy incidents in enterprise LLMs stemmed from logged tokens-not full prompts. The problem isn’t just legal risk. It’s reputational. One healthcare provider in Germany was fined €4.2 million in Q2 2025 after patient names and treatment codes were recovered from log files by a third-party auditor.
How Token-Level Logging Minimization Works
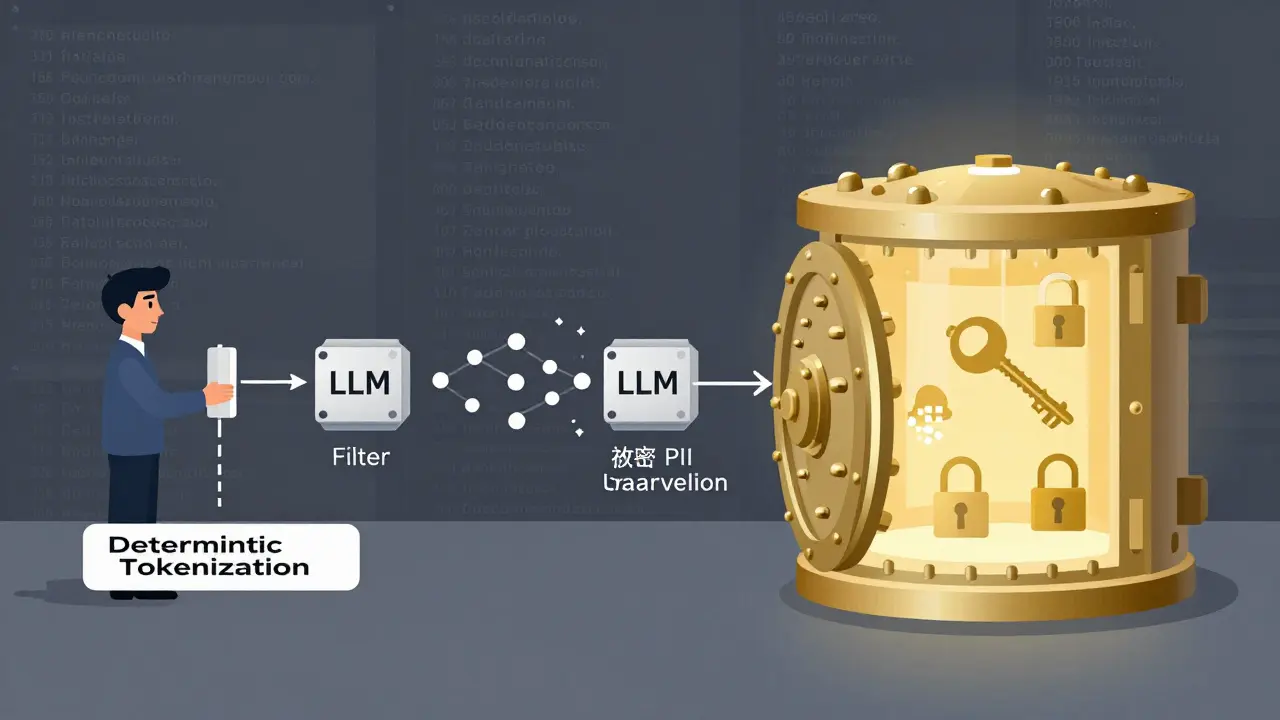
Token-level logging minimization doesn’t stop logging. It stops logging personal data. The goal is simple: replace anything that can identify a person with a harmless placeholder, before the data ever reaches the model. This is called deterministic tokenization.Here’s how it works in practice:
- Identify fields to tokenize: This includes direct identifiers (names, emails, SSNs, phone numbers) and quasi-identifiers (zip codes, dates of birth, job titles) that can be combined to reveal identity.
- Apply consistent token formats: Replace "[email protected]" with "EMAIL_7821" or "ID_93f4". The format stays the same every time, so the model still understands the structure.
- Store the mapping securely: The real values aren’t deleted-they’re encrypted and stored in a separate, access-controlled vault. Only authorized systems can reverse the tokens, and only after the LLM response is generated.
- Integrate into the pipeline: Tokenization happens before the LLM processes the input. The reverse mapping happens after the output is generated, so logs never contain real PII.
This isn’t just theory. Companies using this method cut privacy incidents by 92% in Q3 2024, according to Protecto AI’s internal benchmarks. And the performance hit? Just 12-18 milliseconds per request-less than 1.3% overhead. That’s barely noticeable to users.
Why Token-Level Beats Other Privacy Methods
You might wonder: Why not just encrypt everything? Or delete logs after 24 hours? Or filter at the input/output level?Let’s compare:
| Method | Privacy Effectiveness | Latency Impact | Model Accuracy Loss | Regulatory Alignment |
|---|---|---|---|---|
| Token-Level Minimization | High (removes PII at source) | 12-18 ms | <2% | GDPR, EU AI Act compliant |
| Full Data Encryption | Very High | 45-60 ms | Up to 15% | Compliant but overkill |
| Sample-Level Filtering | Low-Medium (misses partial PII) | 5-10 ms | 5-10% | Not sufficient for GDPR |
| Log Deletion After 24h | Low (data exposed during processing) | None | 0% | Non-compliant |
The numbers speak for themselves. Full encryption adds too much delay and breaks model performance. Sample-level filtering misses half the risks-like when a tokenized name is paired with a zip code and birthdate. Token-level minimization hits the sweet spot: it’s precise, fast, and meets strict regulatory standards.
The Real Challenge: Multi-Turn Conversations
The biggest mistake companies make? Thinking tokenization is a one-time fix. In real-world use, users don’t ask one question and leave. They have conversations. And the risk isn’t just in one message-it’s in the combination of messages across turns.Imagine this:
- Turn 1: "I’m Alex Rivera. My SSN is 123-45-6789."
- Turn 3: "I want to know who accessed my account."
- Turn 5: "Can you email me the report?"
If you tokenize "Alex Rivera" and "123-45-6789" in turn 1, but don’t track that those tokens were used in turn 3 and 5, you’re still leaking context. The model might respond with: "The last access was by USER_ID_93f4 on 2025-01-10." Now someone can link "USER_ID_93f4" back to Alex Rivera.
This is why session-level monitoring is non-negotiable. You need systems that track the full conversation history and flag when new tokens combine with old ones to recreate PII. Galileo AI’s case study of 47 enterprise deployments found that 73% of initial implementations failed because they didn’t account for this. The fix? Build logging workflows that scan for "multi-turn drift"-patterns where context shifts in ways that expose hidden links.
What Happens When You Don’t Do This?
The consequences aren’t theoretical. In March 2025, a major U.S. bank faced a class-action lawsuit after an internal audit found 14,000 logged PII entries in their LLM logs-names, account numbers, even voice recordings transcribed into tokens. The bank had assumed their "data masking" system was enough. It wasn’t.Regulators are catching up. The EU AI Act now requires "data minimization by design" for all high-risk AI systems. GDPR Article 32 demands that organizations implement "appropriate technical measures" to protect personal data. Token-level logging minimization isn’t optional anymore-it’s the baseline expectation.
By 2026, Gartner predicts that 75% of enterprise LLM deployments will require certified token-level privacy controls. Companies that delay are already behind.
Implementation Tips: What Works in the Real World
If you’re starting now, here’s what actually works:- Start with a pilot: Pick one high-risk use case-like customer support for healthcare or finance-and test tokenization there first.
- Use deterministic tokenization, not rules: Naive keyword replacement (like "replace all emails with [EMAIL]") is easy to bypass. Use structured formats like "EMAIL_####" with cryptographic salt.
- Train your team: IBM’s certification program shows that engineers who complete a 40-hour course on token optimization have an 82% success rate in deployment.
- Test against OWASP LLM Top 10: Build reusable test sets that simulate known leakage patterns. Companies that do this reduce false negatives by 41%.
- Don’t trust vendor claims: Protecto AI’s documentation scored 4.7/5 on G2. Open-source tools average 3.2/5. Good documentation saves weeks of debugging.
What’s Next? The Future of Token-Level Privacy
The field is evolving fast. In January 2026, Protecto AI released "Multi-Turn Memory Scanning 2.0," which cuts false positives by 34%. The TOSS-Pro framework now identifies unsafe tokens with 91.7% precision. And IBM is working on integrating homomorphic encryption-so even the token vaults could be processed without decryption.But the biggest shift? Token-level minimization is becoming a requirement, not a feature. In regulated industries like finance and healthcare, adoption is already at 87%. Retail and manufacturing are catching up. By 2027, if your LLM system doesn’t have token-level logging controls, you won’t be able to deploy it legally in the EU-or in many U.S. states with similar laws.
The bottom line: You can’t afford to ignore this. The technology works. The regulations demand it. And the cost of doing nothing is far higher than the cost of implementing it.
What exactly is token-level logging minimization?
Token-level logging minimization is the process of replacing personally identifiable information (PII) with anonymous placeholders-like "NAME_7821" or "EMAIL_93f4"-at the individual token level before data enters an LLM. This ensures logs contain no real names, emails, or numbers, while preserving the structure needed for the model to function properly.
Is this the same as data encryption?
No. Encryption scrambles entire inputs or outputs and adds significant latency (45-60ms per request). Token-level minimization only replaces specific sensitive tokens, keeping performance overhead low (under 20ms) and model accuracy nearly untouched. It’s more surgical and efficient.
Can attackers reverse tokenized data?
Simple token replacement (like "NAME_1") can be reversed if attackers know patterns. But deterministic tokenization with salted, randomized formats like "ID_93f4" makes this extremely difficult. For high-risk systems, combine it with contextual monitoring and secure mapping vaults to eliminate reverse-engineering risks.
Why do multi-turn conversations make this harder?
A single token might be harmless alone, but when combined with others across multiple turns, they can reconstruct PII. For example, "USER_ID_93f4" + "2025-01-10" + "[email protected]" might reveal a person’s identity. Session-level monitoring is required to detect these hidden links.
Do I need to use a vendor like Protecto AI?
No. Open-source tools like TOSS exist, but they often lack documentation and multi-turn handling. Enterprise deployments benefit from vendor tools with proven testing frameworks, compliance reporting, and ongoing updates-especially if you’re in finance, healthcare, or government.
How long does implementation take?
A full deployment, including testing, training, and session monitoring setup, typically takes 6-8 weeks. Start with a pilot use case to validate your approach before scaling.
Is this required by law?
Yes. The EU AI Act and GDPR Article 32 require data minimization by design. The European Data Protection Board explicitly recommends token-level filtering as a minimum standard for LLM systems. Failure to implement it can result in fines up to 4% of global revenue.
Next Steps: What to Do Today
If you’re using LLMs in production, here’s your action plan:- Review your current logging system. Are names, emails, or IDs appearing anywhere in logs?
- Run a test: Feed a sample prompt with PII into your system and check the raw logs. If you see real data, you’re at risk.
- Start a pilot project using deterministic tokenization on one high-risk workflow.
- Train your team on tokenization best practices-IBM’s 40-hour certification is a solid starting point.
- Build a testing suite based on OWASP LLM Top 10 to catch leakage patterns early.
- Plan for session-level monitoring. This isn’t optional-it’s the next layer of defense.
Token-level logging minimization isn’t a buzzword. It’s the difference between compliance and a €4 million fine. Between trust and a public breach. Between building secure AI-and just building AI that’s lucky.
Vimal Kumar
January 31, 2026 AT 14:15Man, I just implemented this at my fintech startup last month. We were logging everything raw because "it helps debugging"-turns out we were logging full SSNs and names in plain text. After switching to deterministic tokenization, our logs are clean and our devs actually stopped panicking every time a GDPR audit came up. The 18ms delay? Barely noticeable. Users didn’t even notice the change. Worth every second.
Diwakar Pandey
January 31, 2026 AT 23:07Token-level minimization is smart, but honestly? Most teams don’t even know what a token is. I’ve seen engineers replace "email" with [EMAIL] and call it a day. No salt. No mapping vault. No session tracking. It’s not privacy-it’s theater. Real minimization needs structure, not buzzwords.
Geet Ramchandani
February 2, 2026 AT 16:36Oh wow. Another over-engineered solution for a problem that doesn’t exist unless you’re stupid enough to log PII in the first place. Why not just not log sensitive data? Why invent a whole new system with vaults and salted tokens and session-level monitoring? Just delete the damn logs after processing. Or better yet-don’t collect it. Stop pretending complexity equals compliance. You’re not protecting privacy-you’re just making your stack harder to debug. And no, 12ms isn’t "negligible" when you’re scaling to millions of requests. This feels like vendor FUD dressed up as engineering.
Pooja Kalra
February 3, 2026 AT 15:44There’s a deeper truth here, beneath the technical jargon. We’ve built systems that treat human identity as data to be optimized, not as dignity to be protected. Tokenization masks the symptom-but the disease is our addiction to surveillance capitalism disguised as "AI innovation." We tokenize names, but we still track behavior. We sanitize logs, but we still monetize patterns. Is this really privacy? Or just a more elegant form of control? The real question isn’t how to log less-it’s why we log at all.
Sumit SM
February 3, 2026 AT 15:46