
Running large language models in production is expensive. You pay for every token processed, every second of latency, and every compute cycle burned on safety checks. When you compress those models to save money, you often break the safety nets that keep your application from generating harmful content. The industry has been stuck in a false dichotomy: either run heavy, accurate guardrails that cost a fortune, or use lightweight filters that miss subtle jailbreak attempts. But recent advances in Defensive M2S (Multi-turn to Single-turn) compression and confidence-based abstention are changing that equation.
This isn't just about making models smaller. It's about building intelligent systems that know when they are confident enough to make a quick decision and when they need to pause, think harder, or pass the buck. If you are deploying compressed LLMs today, you need to understand how to balance speed, cost, and safety without choosing between them.
The Cost of Safety in Production
Guardrails are the external control mechanisms that monitor inputs and outputs in real-time. They enforce policies, filter toxic content, and prevent data leaks. In a naive setup, you might send every user prompt through a massive 70-billion-parameter model just to check if it’s safe. That works for accuracy, but it destroys your margins. Latency spikes, costs soar, and users get frustrated waiting for a simple "yes" or "no" on their request.
The core problem with traditional guardrails is that they treat all inputs equally. A harmless query like "What is the weather?" gets the same computational treatment as a complex, multi-turn jailbreak attempt. This inefficiency becomes critical at scale. Research shows that processing multi-turn conversations creates quadratic complexity-O(n²)-meaning the cost grows exponentially with conversation length. For high-volume applications, this is unsustainable.
Enter compression. By reducing the input size before the guardrail even sees it, we can slash costs. But here is the catch: standard compression techniques often strip away the semantic nuance needed to detect sophisticated attacks. If you summarize a jailbreak attempt too aggressively, the guardrail might see only innocent text. The solution lies not in generic summarization, but in specialized compression templates designed specifically for safety detection.
Defensive M2S: Compressing Without Losing Signal
Defensive M2S is a methodology that transforms multi-turn conversation histories into compact single-turn representations. Instead of feeding the entire chat history into the guardrail, M2S distills it into a format that preserves adversarial signals while drastically reducing token count. The approach uses three primary compression templates:
- Hyphenize: Converts conversation turns into a hyphen-separated string, preserving turn order and context concisely.
- Numberize: Assigns numerical indices to turns, creating a structured, machine-readable summary.
- Pythonize: Formats the conversation as Python-like code structures, leveraging syntax for clear separation of roles and messages.
Why does this work? Because multi-turn jailbreak attacks often rely on cumulative context. By compressing these interactions into a single, dense representation, we force the guardrail to focus on the essential semantic relationships rather than getting lost in verbose dialogue. Empirical studies show that M2S-trained guardrails achieve up to 94.6% token reduction while maintaining competitive detection accuracy. In some cases, like using Qwen3Guard with the hyphenize template, recall actually improved from 54.9% to 93.8%. Compression didn’t hurt performance; it enhanced it by removing noise.
The efficiency gains are mathematically significant. Training cost drops from O(n²) to O(n), validated by a 93× token reduction on evaluation datasets. This means you can process hundreds of times more requests with the same compute budget, provided you train your guardrails on compressed data from the start. Don’t try to apply M2S at inference time alone; the model must learn to recognize safety features within the compressed structure during training.
Confidence Scores and the Art of Abstention
Even the best compressed guardrail won’t be perfect. Some inputs will sit in the gray area-neither clearly safe nor obviously malicious. This is where confidence mechanisms come in. Instead of forcing a binary accept/reject decision, modern guardrails output a confidence score alongside their classification.
Abstention is the practice of declining to make a final decision when confidence falls below a certain threshold. Think of it like a doctor who says, "I’m not sure what this rash is; let me refer you to a specialist." In AI terms, if the lightweight guardrail is unsure, it abstains and triggers a deeper, more expensive analysis layer. This tiered approach prevents false positives (blocking safe content) while maintaining protection against genuine threats.
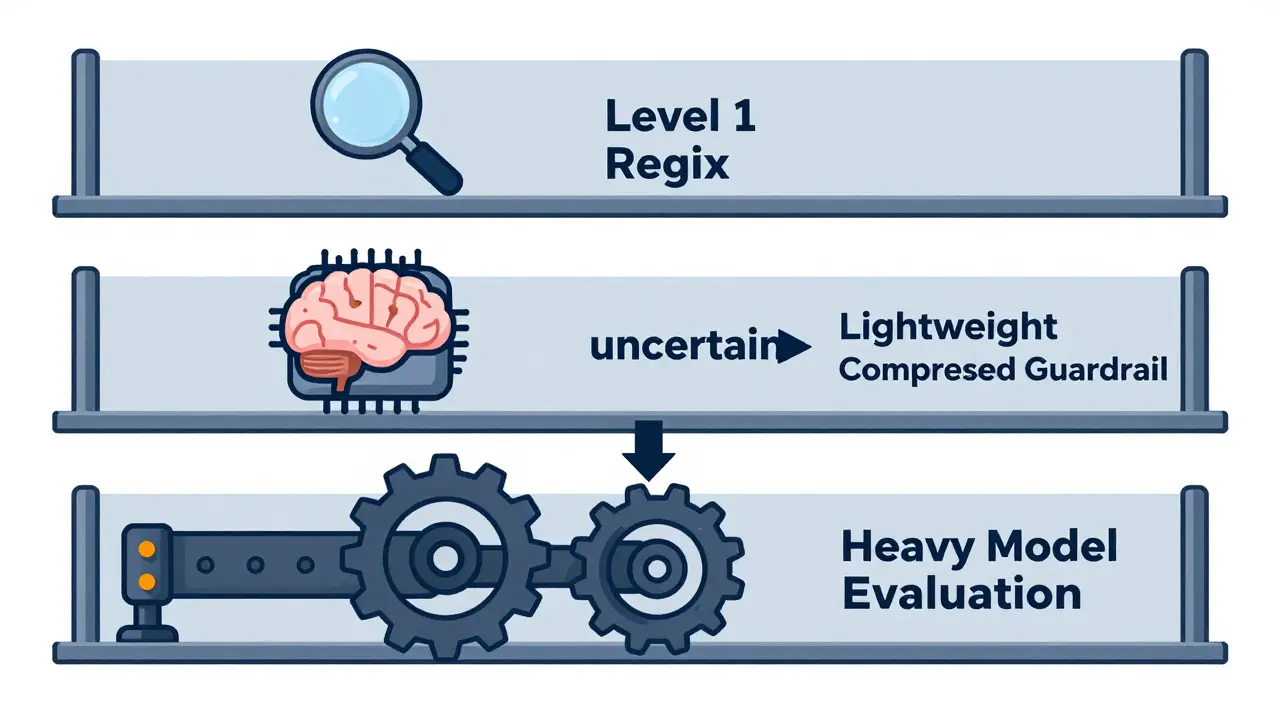
Here’s how it works in practice:
- Level 1: Regex/Keyword Scan. Fastest, cheapest. Catches obvious violations. If clean, pass. If suspicious, escalate.
- Level 2: Lightweight Compressed Guardrail. Uses M2S-compressed input. Outputs a confidence score. If high confidence, act on it. If low confidence, escalate.
- Level 3: Heavy Model Evaluation. Full-context analysis by a larger, more capable model. Used only for edge cases.
This strategy optimizes for both precision and recall. You avoid the cost of running heavy models on every request, but you don’t sacrifice safety on ambiguous inputs. The key is calibrating your confidence thresholds based on your risk tolerance. A financial app might set a lower threshold for escalation than a casual chatbot.
Tiered Architectures for Real-World Deployment
Implementing confidence and abstention requires a tiered architecture. You can’t just plug one model into your pipeline and hope for the best. Here are the components you need to build a robust system:
| Strategy | Speed | Cost | Accuracy | Best Use Case |
|---|---|---|---|---|
| Regex/Keyword Filtering | Instant | Negligible | Low | Catching obvious profanity or PII |
| M2S Compressed Guardrail | Fast | Low | High | General-purpose safety checks on multi-turn chats |
| LoRA-Guard Adaptation | Medium | Medium | Very High | Domain-specific safety with minimal parameter overhead |
| Full LLM Evaluation | Slow | High | Highest | Edge cases requiring nuanced understanding |
LoRA-Guard (Low-Rank Adaptation for Guardrails) is another powerful tool in this stack. It achieves 100 to 1000× lower parameter overhead by sharing knowledge between the main LLM and the guardrail. Instead of training a separate safety model from scratch, LoRA-Guard fine-tunes a small adapter on top of an existing base model. This complements M2S compression beautifully: you reduce input tokens with M2S, then process them efficiently with a LoRA-adapted model.
Caching also plays a crucial role. If two users ask the same question, don’t run the guardrail twice. Cache the decision for identical prompts. Combine this with confidence scoring, and you create a system that learns over time, becoming faster and cheaper with each interaction.
Tools and Frameworks for Implementation
You don’t have to build all of this from scratch. Several frameworks provide the building blocks for efficient guardrailing:
- Meta’s Prompt-Guard: A specialized model with only 86 million parameters. It’s tiny compared to typical 70B models, enabling fast classification. Ideal for Level 2 checks in a tiered system.
- NeMo Guardrails: Offers programmable rails for controllable LLM applications. You define rules explicitly, giving you precise control over behavior without relying solely on black-box predictions.
- Guidance AI: Provides a programming paradigm that interleaves control structures with generation. You can constrain outputs using regex and context-free grammars, ensuring structural compliance alongside safety.
- LMQL (Language Model Query Language): Introduces SQL-like syntax for querying language models. It supports logit masking and custom operators, allowing fine-tuned control over token selection based on real-time constraints.
These tools vary in complexity. Prompt-Guard is plug-and-play for basic safety. NeMo and Guidance require more engineering effort but offer greater flexibility. LMQL is best for developers who need granular control over decoding processes. Choose based on your team’s expertise and your application’s specific needs.
Future Directions: Adaptive Templates and Distillation
The field is moving toward adaptive approaches. Future systems won’t use a static compression template for every input. Instead, they will automatically select the optimal template-hyphenize, numberize, or pythonize-based on the specific safety scenario. A legal document review might benefit from pythonize for its structure, while a casual conversation might do better with hyphenize.
Combining Defensive M2S with model distillation is another promising avenue. Distillation transfers knowledge from a large teacher model to a smaller student model. If you distill a safety-aware large model into a compact guardrail trained on M2S-compressed data, you get the best of both worlds: the nuanced judgment of the large model and the speed of the small one.
Expect to see more standardized benchmarks for evaluating compressed guardrails. Current research spans multiple model families, but broader adoption requires consistent metrics for comparing efficiency, accuracy, and robustness across different architectures. As these standards emerge, deploying safe, efficient LLMs will become less of an art and more of a science.
What is Defensive M2S?
Defensive M2S is a compression technique that converts multi-turn conversations into single-turn representations using templates like hyphenize, numberize, and pythonize. It reduces token counts by up to 94.6% while preserving the semantic information needed for accurate safety detection, lowering computational costs from O(n²) to O(n).
How does confidence-based abstention improve guardrails?
Confidence-based abstention allows guardrails to express uncertainty instead of making forced binary decisions. When confidence is low, the system abstains and escalates the input to a more rigorous, albeit slower, evaluation layer. This balances precision and recall, preventing false positives while catching subtle threats.
Is M2S compression effective for all types of attacks?
M2S is particularly effective against multi-turn jailbreak attacks, which rely on cumulative context. Studies show compressed prompts can sometimes outperform original multi-turn attacks in success rate, meaning the guardrail sees the core adversarial signal. However, effectiveness varies by template and model combination, so empirical testing is essential.
What is LoRA-Guard and how does it help?
LoRA-Guard uses Low-Rank Adaptation to add safety capabilities to existing LLMs with minimal parameter overhead (100-1000× lower than full fine-tuning). It shares knowledge between the main model and the guardrail, making it highly efficient for domain-specific safety checks when combined with input compression techniques like M2S.
Which framework should I use for production guardrails?
For simple, fast checks, Meta’s Prompt-Guard is ideal due to its small size (86M parameters). For programmable control, consider NeMo Guardrails or Guidance AI. If you need granular control over token generation and constraints, LMQL offers SQL-like querying capabilities. Most production systems combine several of these in a tiered architecture.