
You ask your AI assistant a question, and it gives you a vague, generic, or completely wrong answer. You check the source documents, and the information is right there. So why did the system miss it? The problem usually isn't the Large Language Model (LLM) itself. It’s the query.
Most Retrieval-Augmented Generation (RAG) systems fail because they treat user input as a static string to be matched against a database. But humans don't speak in perfect search queries. We use pronouns, slang, incomplete sentences, and complex reasoning that simple keyword matching can't handle. This is where query understanding comes in. By reformulating and expanding your inputs before they hit the vector database, you can boost retrieval accuracy by up to 48% without retraining your models or buying more hardware.
The Core Problem: Why Basic RAG Fails
Retrieval-Augmented Generation relies on two steps: finding relevant documents and then generating an answer based on them. If the first step fails, the second step is doomed. In a basic setup, the system takes your exact words, converts them into vectors, and looks for similar vectors in the database. This works fine if you ask, "What is the capital of France?" But it breaks down with questions like, "Why did the merger fail given the regulatory environment last year?"
According to benchmark tests from Stanford University's Center for Research on Foundation Models in February 2024, poorly structured natural language queries lead to suboptimal retrieval results in a significant portion of enterprise cases. The gap between what a user means and what the vector search engine understands is the "semantic gap." Query understanding bridges this gap by acting as a translator between human intent and machine logic.
| Feature | Basic RAG | Query-Enhanced RAG |
|---|---|---|
| Input Handling | Direct pass-through | Analyzed and transformed |
| Accuracy Improvement | Baseline | 35-48% higher retrieval accuracy |
| Latency Overhead | Minimal | 150-300ms additional processing |
| Complexity | Low | Moderate to High |
Key Techniques: Reformulation and Expansion
To fix broken queries, developers use specific techniques. These aren't magic; they are structured prompts that force the LLM to think before it searches. Here are the most effective methods used in production environments today.
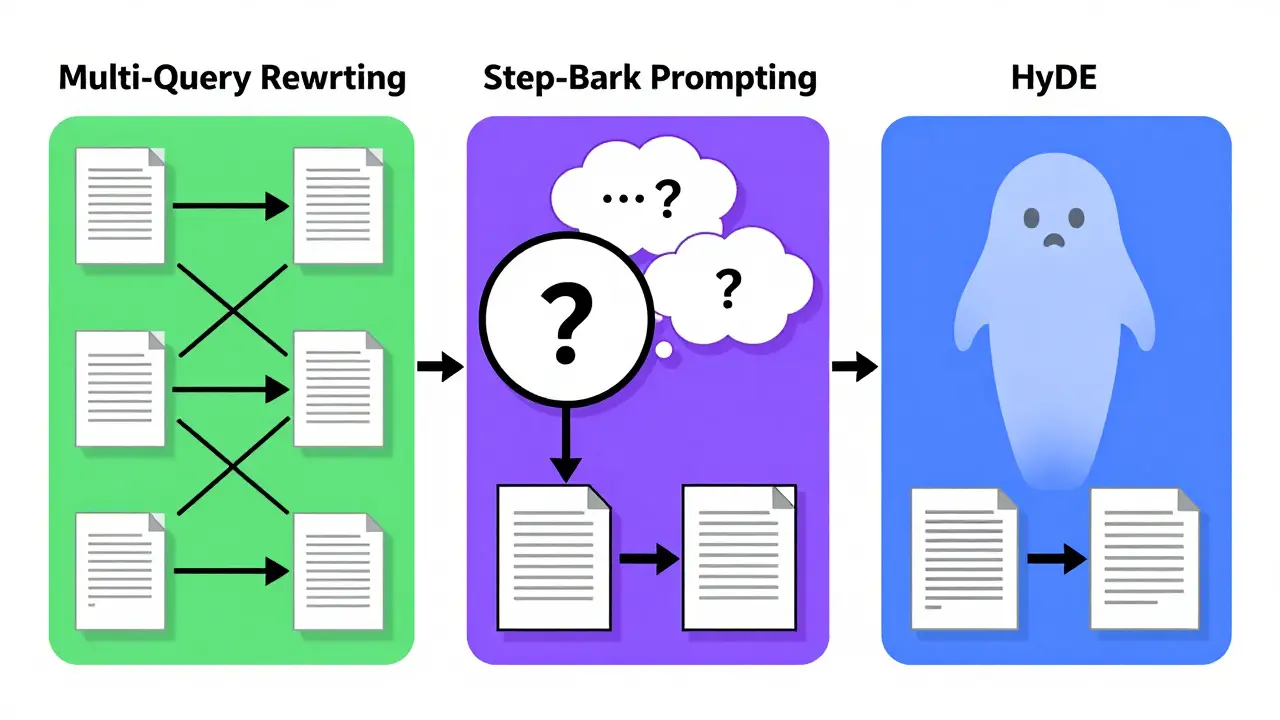
Multi-Query Rewriting
This technique involves asking the LLM to generate multiple versions of the original query from different angles. Instead of searching once, the system searches three times and combines the results. For example, if a user asks about "best practices for cloud security," the system might also search for "AWS IAM configuration tips" and "cloud infrastructure vulnerabilities." According to testing by the University of Washington's RAG research team in June 2024, this approach increases relevant document retrieval by 37.2% compared to single-query approaches.
Step-Back Prompting
Sometimes, a question is too specific for the available data. Step-back prompting asks the LLM to first identify the general principle behind the specific question. If a user asks, "Did the 2024 tax law change affect small business deductions?" the system first retrieves information on "2024 US tax law changes" and "small business deduction rules" separately. Google AI researchers found in March 2024 that this improves factual accuracy in complex knowledge-intensive questions by 29.8%. It reduces hallucinations because the model grounds its specific answer in broader, well-retrieved facts.
Hypothetical Document Embeddings (HyDE)
Instead of embedding the question, HyDE asks the LLM to imagine what a perfect answer would look like. It generates a hypothetical document and then embeds that document to find real documents that match it. This is powerful because the embedding space is optimized for statements, not questions. It effectively turns a question into a statement, which vector databases handle much better.
Architectural Components of Query Understanding
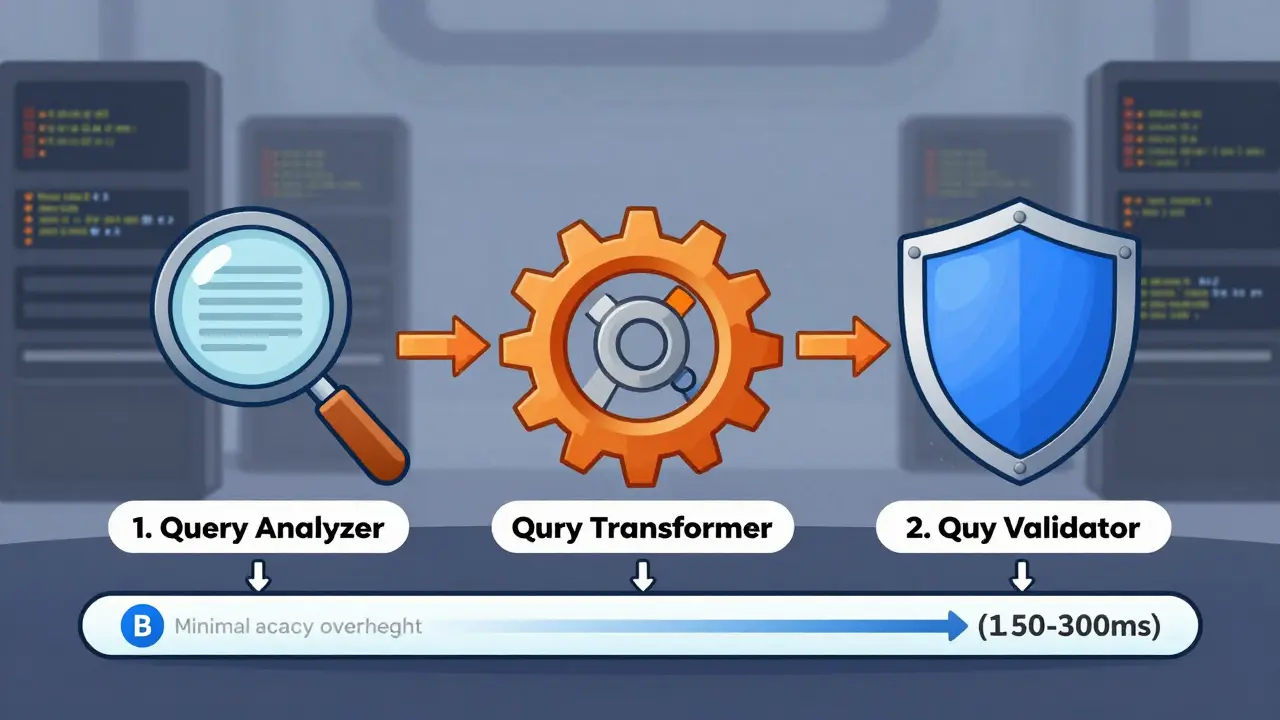
Implementing these techniques requires a structured pipeline. NVIDIA's RAG 101 framework outlines three primary components:
- The Query Analyzer: Parses the semantic structure of the input. It identifies entities, intents, and ambiguities. For instance, it recognizes that "it" refers to the previously mentioned product.
- The Query Transformer: Applies the chosen reformulation technique (like multi-query or step-back). This component often uses a lightweight transformer model. LangChain version 2.1, released in July 2024, introduced standardized modules supporting seven distinct reformulation techniques.
- The Query Validator: Assesses the quality of the transformed queries before sending them to the retriever. This prevents garbage-in-garbage-out scenarios where the expansion creates nonsensical search terms.
These components add minimal computational overhead. Modern implementations typically add only 150-300ms to the overall query processing time while reducing retrieval failures by 42%, according to NVIDIA's benchmarks using the Natural Questions dataset.
Implementation Challenges and Trade-offs
While the benefits are clear, query understanding is not free. It introduces complexity. A survey of 127 AI engineers by Towards Data Science in May 2024 found that implementation requires approximately 35-50% more development effort than basic RAG. Developers must tune prompts, manage token limits, and debug why a specific expansion failed.
Token consumption is another major concern. Multi-query rewriting can increase token usage by 2.7x compared to basic queries. This impacts cost, especially at scale. Additionally, there is a risk of bias amplification. Dr. Emily Bender of the University of Washington warned in October 2024 that over-reliance on query expansion risks introducing subtle biases. In legal RAG systems, query expansion increased the retrieval of precedential cases by 28% but also amplified historical biases present in those cases by 19%.
Debugging becomes harder. When a system returns a bad answer, is it because the retrieval failed, the expansion was wrong, or the generation model hallucinated? Tracing the error back through the transformation layer requires robust logging and monitoring tools.
When to Use Query Understanding
Not every application needs advanced query understanding. Microsoft Research evaluated 15,000 diverse queries in August 2024 and found that query understanding shows diminishing returns for simple factual queries where basic keyword matching suffices. If your chatbot answers "What is our return policy?" you don't need step-back prompting.
However, query understanding excels in:
- Ambiguous terminology: Users using slang or industry jargon.
- Multi-faceted questions: Queries requiring synthesis of multiple documents.
- Domain-specific contexts: Healthcare, legal, and finance, where precision is critical.
In fact, adoption rates are highest in these sectors. As of Q3 2024, 68% of healthcare AI applications and 61% of legal tech platforms incorporate advanced query understanding techniques, according to Forrester's September 2024 industry survey.
Best Practices for Implementation
If you decide to implement query understanding, follow these guidelines to avoid common pitfalls:
- Start Simple: Begin with multi-query rewriting. It offers the best balance of complexity and performance improvement. Allocate 2-3 weeks for integration after establishing a basic RAG pipeline, as recommended by NVIDIA's September 2024 guide.
- Limit Expansion Depth: Don't expand infinitely. Most developers settle on 2-3 expansion variations. Beyond that, noise increases faster than signal.
- Use Lightweight Models: You don't need the largest LLM for query transformation. A model with approximately 110 million parameters can run on entry-level GPUs like the NVIDIA T4 or even CPU-only environments with acceptable latency trade-offs of 200-400ms.
- Monitor Bias: Regularly audit retrieved documents for bias, especially in sensitive domains like legal or HR. Implement guardrails in the validator component.
- Handle Context: Incorporate conversational history. Handling context from previous turns requires an additional 15-25% development effort but significantly improves user experience in chat interfaces.
The Future of Query Understanding
The field is evolving rapidly. NVIDIA announced RAG Stack 2.0 at GTC 2024, featuring "adaptive query transformation" that dynamically selects the optimal reformulation technique based on query complexity metrics. Beta testing showed an 18.3% improvement over static approaches. LangChain's roadmap includes "self-correcting query expansion" scheduled for Q2 2025, which uses LLM-generated feedback to iteratively refine query transformations.
Academic research is also advancing. Stanford University's November 2024 preprint demonstrated a 41.7% improvement in complex query handling by modeling query elements as knowledge graphs. This suggests that future systems will move beyond text-based expansion to structural understanding of queries.
By 2026, 87% of analysts surveyed by Gartner believe query understanding will become a standard component of all enterprise RAG systems. It is no longer a nice-to-have feature; it is a necessity for any AI application that demands high accuracy and reliability.
What is query understanding in RAG?
Query understanding in RAG is the process of analyzing, reformulating, and expanding user inputs before they are sent to the retrieval system. It transforms ambiguous or poorly structured natural language queries into optimized search queries that maximize the relevance of retrieved information, thereby improving the accuracy of the final LLM-generated response.
How does multi-query rewriting improve RAG?
Multi-query rewriting improves RAG by generating multiple variations of the original query from different perspectives. This increases the chances of retrieving relevant documents that might have been missed by a single, literal search. Studies show it can increase relevant document retrieval by over 37% compared to single-query approaches.
What is step-back prompting?
Step-back prompting is a technique where the LLM first identifies the general principles or broader concepts behind a specific question before retrieving information. This helps in answering complex, knowledge-intensive questions by grounding the specific answer in broader, well-retrieved facts, reducing factual hallucinations by nearly 30%.
Is query understanding worth the added complexity?
For simple factual queries, basic keyword matching may suffice. However, for complex, ambiguous, or domain-specific questions, query understanding is essential. It can improve retrieval accuracy by 35-48% and is now considered a standard component for enterprise-grade RAG systems in industries like healthcare and legal tech.
What are the risks of query expansion?
The main risks include increased computational cost and token usage, potential amplification of biases present in the training data or retrieved documents, and added debugging complexity. Proper validation and monitoring are required to mitigate these issues.