Tag: feedforward network
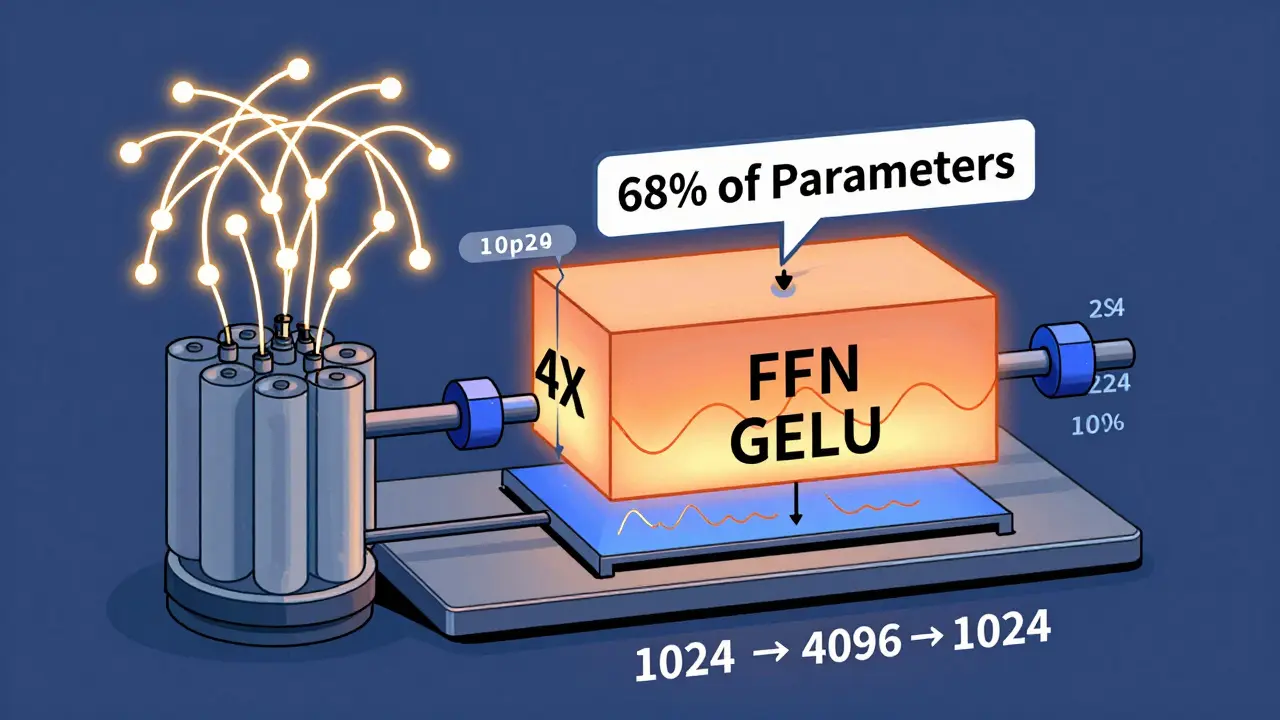
Feedforward Networks in Transformers: Why Two Layers Boost Large Language Models
The two-layer feedforward network in transformers isn't just a default - it's the key to why large language models work so well. Here's why it outperforms simpler or deeper alternatives, and why it's still the industry standard in 2026.
Read more