When you think about how large language models like GPT-4, Llama 3, or Gemini understand and generate human-like text, you might picture complex attention systems pulling context from distant words. But there’s another piece of the puzzle that does just as much heavy lifting - and it’s hidden inside every transformer block: the feedforward network. More specifically, it’s the two-layer version that’s become the industry standard. Why? Because it’s not just a default setting. It’s the sweet spot between power, efficiency, and stability.
What Exactly Is a Feedforward Network in a Transformer?
Every transformer block has two main parts: the multi-head attention mechanism and the feedforward network (FFN). Attention handles relationships between tokens - like how "bank" in "river bank" differs from "bank" in "money bank." But once attention does its job, the FFN steps in to transform each token’s representation independently. It doesn’t look at other tokens. It doesn’t reason across context. It just takes the output from attention and applies a non-linear transformation.
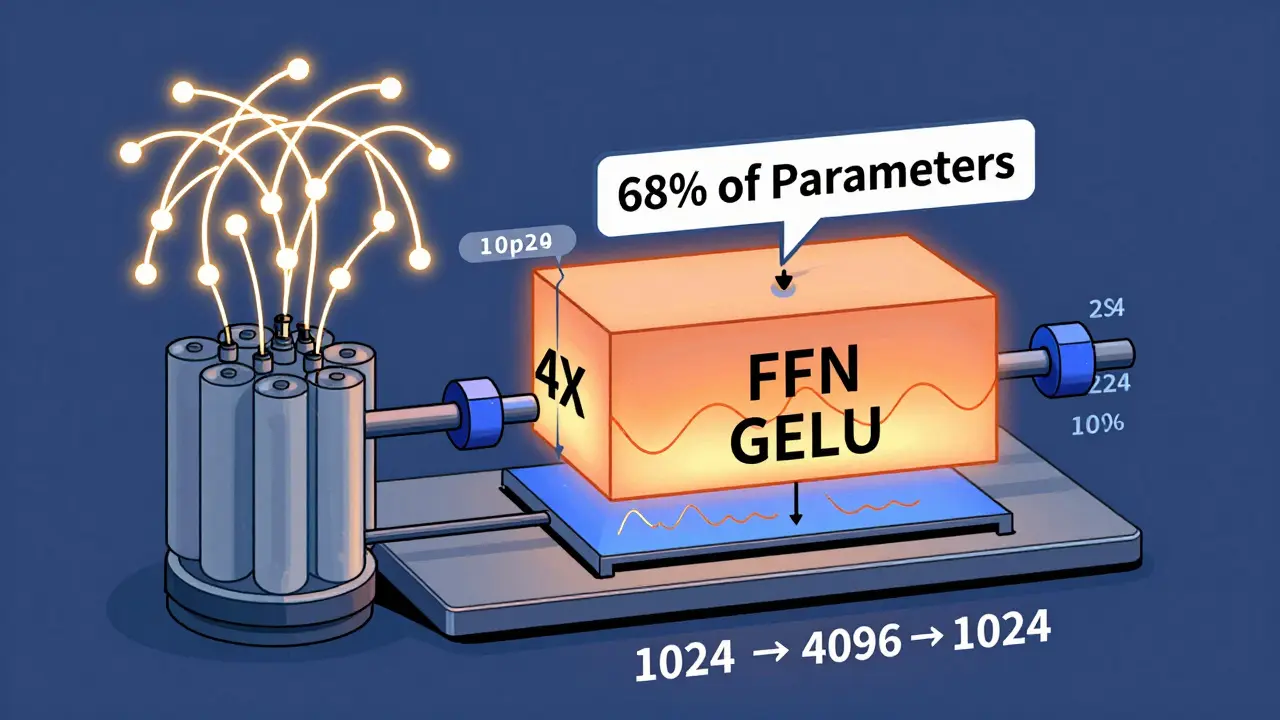
The FFN is built from two linear layers with a non-linear activation function sandwiched between them. In most models, the first layer expands the input dimension from d_model (usually 512, 1024, or 12,288) to d_ff, which is typically 4 times larger. So if your model uses 1024-dimensional vectors, the FFN blows them up to 4096, applies a GELU activation (the modern replacement for ReLU), then squeezes them back down to 1024. This expansion gives the model room to learn richer, more complex patterns.
It’s not fancy. It’s not recursive. It’s just a simple, fully connected network. But here’s the kicker: in models like GPT-3, the FFN accounts for 68% of all trainable parameters. That’s more than attention, more than embeddings, more than layer normalization. It’s the biggest chunk of the model.
Why Two Layers - Not One or Three?
One layer? Too weak. Three layers? Too heavy. Two layers? Just right.
Research from May 2025 (arXiv:2505.06633v1) tested this directly. They compared models with one, two, and three FFN layers - but kept the total parameter count nearly identical (within 3%). The results were clear:
- One-layer FFN: 5.7% worse performance on language modeling tasks.
- Two-layer FFN: baseline performance, stable training, consistent results.
- Three-layer FFN: 2.4% better performance on cross-entropy loss, but only when the total depth of the transformer was reduced (16 blocks instead of 24).
That last point is critical. A three-layer FFN isn’t better because it’s deeper - it’s better because it lets you use fewer transformer blocks overall. That cuts training time by 18%. But it also makes the model harder to train. Gradient instability? Common. Memory fragmentation? Frequent. Most teams don’t have the resources to tune it.
Apple’s 2023 research showed something even more surprising: if you remove the FFN entirely from decoder layers in translation models, performance drops by only 0.3 BLEU. That’s almost nothing. But here’s the twist - when they scaled up the shared FFN to match the original parameter count, performance went up to 28.7 BLEU. So maybe FFNs aren’t as irreplaceable as we thought?
Yet, 92% of top-performing LLMs from 2020 to 2023 still use the two-layer structure. Why? Because it works reliably across tasks - not just translation, but summarization, code generation, reasoning, and zero-shot learning.
The Hidden Cost: Computational Load
For every token, the FFN runs about 8 × d_model × d_ff floating-point operations. In GPT-3 with d_model=12,288 and d_ff=49,152, that’s nearly 472 million FLOPs per token - just for the FFN. NVIDIA’s 2024 analysis found that FFN operations make up 50-60% of total inference time in transformer models. In long-context models, that’s a bottleneck.
And memory? The FFN layers in a 70B parameter model like Llama 2 can consume 40-50GB of VRAM during training. That’s why companies like Meta introduced FlashFFN in Llama 3 (April 2025) - a memory-efficient version that cuts memory use by 35% without changing performance. It’s not a new architecture. It’s a smarter implementation of the same two-layer design.
Meanwhile, Google’s Gemini 2.0 (June 2025) takes a different approach: it dynamically chooses between one and three FFN layers per token based on complexity. Some tokens need depth. Others don’t. But this is still experimental. It adds latency, increases engineering overhead, and requires massive compute to train.
Why Industry Keeps the Two-Layer Design
There’s a myth that the two-layer FFN is theoretically optimal. It’s not. It’s an engineering compromise.
As Ashish Vaswani, co-creator of the transformer, said in a 2023 MIT interview: "It emerged as a practical compromise during our initial experiments - it provided sufficient non-linearity without excessive computational cost." That’s the whole story. No deep math. No proven optimality. Just trial, error, and scale.
Companies stick with it because:
- It trains stably. No need to tweak learning rates or layer norms.
- Hardware is optimized for it. NVIDIA’s Tensor Cores, AMD’s CDNA, and Apple’s Neural Engine all have instructions tuned for 4× expansion.
- It’s predictable. You can reason about memory, latency, and scaling.
- It’s battle-tested. Every major LLM from GPT-3 to Llama 3 uses it.
Even when alternatives show promise - like sparse FFNs in Google’s Mixture of Experts or shared FFNs in encoder-decoder models - they’re used in niche cases. The two-layer FFN remains the default because it’s the most reliable path to strong performance without hidden gotchas.
What’s Changing in 2026?
By 2027, Forrester predicts 45% of commercial LLMs will use modified FFN structures. But that doesn’t mean the two-layer design is dying. It means the baseline is becoming a platform for innovation.
Here’s what’s happening now:
- FlashFFN (Meta, 2025): Memory-optimized two-layer FFN. Used in Llama 3. Reduces VRAM by 35%.
- Adaptive FFN depth (Google Gemini 2.0, 2025): Chooses layer count per token. Still experimental.
- Mixture of Experts (Google, Microsoft): Replaces dense FFN with sparse experts. Cuts compute by 22-28%.
- Parameter-efficient FFNs (University of Washington, 2024): Uses low-rank matrices to reduce size without losing accuracy.
These aren’t replacements. They’re refinements. The core idea - a two-layer, non-linear, token-wise transformation - is still the foundation.

Should You Change It?
If you’re training a model from scratch? Probably not. Unless you have a team of ML engineers and access to thousands of GPUs, stick with the standard. The learning curve is steep. A survey of 147 ML engineers by Lambda Labs found it takes 80-100 hours of focused work just to understand how to modify FFN depth without breaking training.
On GitHub, 37% of issues related to FFN modifications involve gradient instability. Reddit users report that switching to a single-layer FFN degrades reasoning performance by 15-20% on complex tasks. And if you try three layers without adjusting learning rates? 78% of experiments fail.
But if you’re fine-tuning a model for a specific task - say, medical QA or legal document analysis - and you have the resources, testing a modified FFN might give you a 1-3% boost. Just remember: you’re not fixing a broken design. You’re optimizing a proven one.
The Bigger Picture
The two-layer FFN isn’t elegant. It’s not mathematically beautiful. But it’s effective. It scales. It generalizes. And it’s survived every wave of transformer innovation - from attention-only variants to sparse experts.
As Professor Percy Liang from Stanford HAI put it in May 2025: "The need for non-linear token-wise transformation appears fundamental to the transformer’s success, regardless of the exact layer configuration."
So the next time you hear someone say "attention is all you need," remember: attention gives context. But the feedforward network gives depth. And that two-layer structure? It’s not an accident. It’s the quiet engine behind every great language model.
Tyler Springall
March 22, 2026 AT 07:53Colby Havard
March 22, 2026 AT 15:26Amy P
March 24, 2026 AT 09:47Ashley Kuehnel
March 25, 2026 AT 02:28adam smith
March 25, 2026 AT 21:16