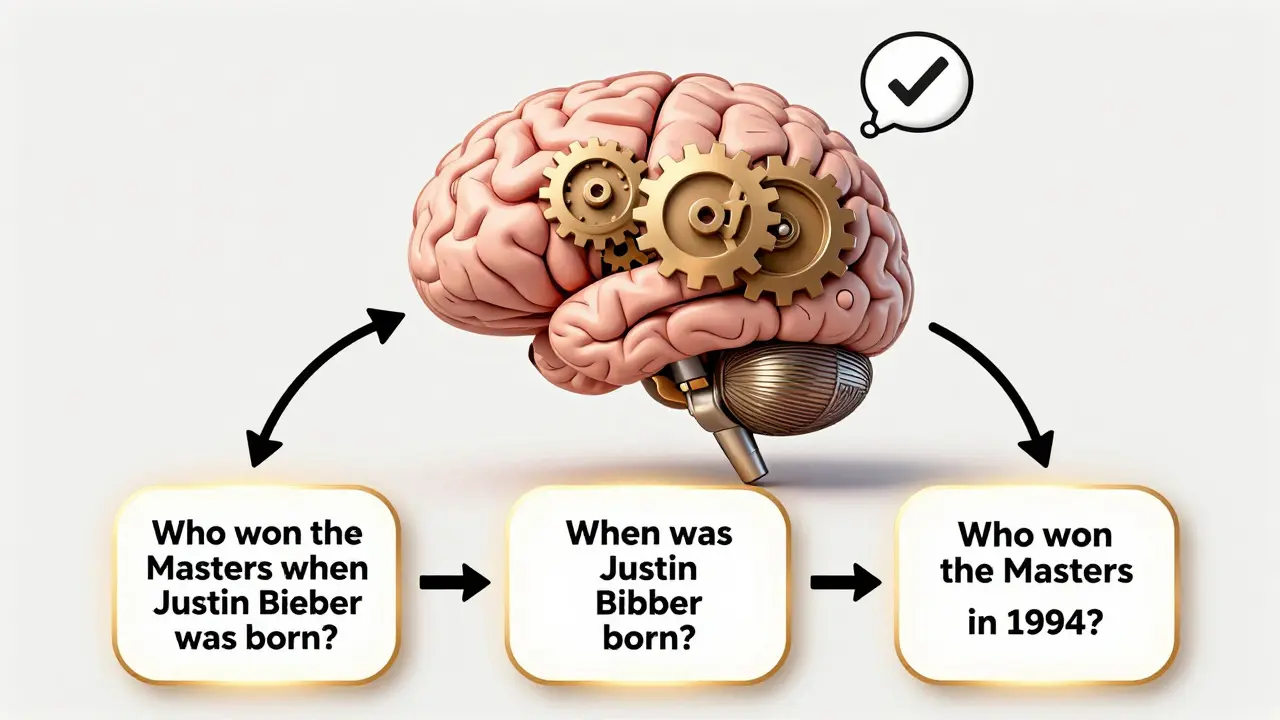
When you ask a large language model a tough question-like "Who won the Masters the year Justin Bieber was born?"-it often guesses. Not because it’s dumb, but because it’s trying to answer too much at once. That’s where self-ask and decomposition prompting come in. These aren’t magic tricks. They’re structured ways to make LLMs think step by step, like a human would. And the results? They’re not just better. They’re often twice as accurate.
How Self-Ask Prompting Breaks Down Problems
Self-ask prompting forces the model to ask itself questions before answering. Instead of jumping straight to a final response, it pauses, breaks the problem apart, and tackles each piece one at a time. The structure is simple:
- Start with the original question.
- Generate a follow-up question: "Follow up: When was Justin Bieber born?"
- Answer that sub-question: "Intermediate answer: Justin Bieber was born on March 1, 1994."
- Ask the next question: "Follow up: Who won the Masters in 1994?"
- Answer again: "Intermediate answer: Ben Crenshaw won the 1994 Masters."
- Combine: "Final answer: Ben Crenshaw won the Masters the year Justin Bieber was born."
This isn’t just a trick for beginners. Research from arXiv paper 2505.01482v2 (May 2025) shows this method boosts GPT-4o’s accuracy on multi-hop reasoning tasks from 68.3% to 82.1%. That’s a 13.8 percentage point jump. For questions that require linking facts across domains-like history, pop culture, and sports-self-ask can lift accuracy from 42.3% to 78.9%. Why? Because it stops the model from guessing. It makes it reason.
Decomposition Prompting: Two Ways to Split the Problem
Decomposition prompting is the broader category that includes self-ask. It’s about breaking complex problems into smaller, solvable parts. But there are two main ways to do it:
- Sequential decomposition: Solve one sub-question, then use that answer to form the next question. Think of it like climbing a ladder-one rung at a time.
- Concatenated decomposition: List all the sub-questions at once and ask the model to answer them all in parallel.
Which one works better? Sequential. According to the same arXiv study, sequential decomposition improved accuracy by 12.7% over concatenated on complex math problems. Why? Because each answer informs the next. If the first step is wrong, you catch it before moving forward. In concatenated mode, errors can hide in the noise.
Real-world use cases show this matters. Legal teams use decomposition to parse contracts: "Is there a non-compete clause? If yes, what’s the duration? Does it apply to remote work?" Financial analysts break down earnings reports: "What was revenue last quarter? What was the operating margin? How does that compare to guidance?" In both cases, decomposition turns vague uncertainty into clear, auditable steps.
How It Compares to Chain-of-Thought
You’ve probably heard of Chain-of-Thought (CoT) prompting. It’s when the model writes out its reasoning like: "First, Justin Bieber was born in 1994. Then, Ben Crenshaw won the Masters in 1994. So the answer is Ben Crenshaw." Sounds similar, right?
But here’s the difference: CoT keeps the reasoning internal. It doesn’t separate steps. Self-ask and decomposition make each step explicit. That’s huge. Why? Because you can audit it. You can check if the model got the birth year right. You can verify the Masters winner. You can spot a mistake before it cascades.
Testing from the arXiv paper shows decomposition prompting generated the most accurate reasoning paths-scoring 82.1 out of 100 on alignment with human reasoning. Chain-of-Thought scored 75.8. Direct answers? Just 71.2. The gap isn’t small. It’s the difference between a guess and a verified conclusion.
Where It Falls Short
These techniques aren’t perfect. They struggle on abstract, philosophical, or creative tasks. Try asking: "Is free will an illusion?" Decomposing that into sub-questions doesn’t help. It forces false structure. Studies show accuracy drops 9.2-11.7% on these kinds of questions compared to standard prompting.
Another problem? Over-reliance. Professor Emily Rodriguez from MIT warned that decomposition can create a false sense of confidence. If each step looks logical, users assume the final answer is correct-even if one intermediate step is factually wrong. In scientific domains, 22.8% of well-structured decomposition chains contained hidden errors. That’s not a bug. It’s a risk.
And then there’s cost. Decomposition increases token usage by 35-47%. That means higher API fees. One engineer on HackerNews noted a 40% spike in costs after switching to self-ask. For real-time applications-chatbots, customer service bots-latency becomes a real issue. Users don’t want to wait 4 seconds for an answer that’s 15% more accurate.
Who’s Using It-and Who’s Not
Enterprise adoption is climbing fast. According to Gartner’s December 2025 survey, 38.7% of companies now use decomposition prompting in their LLM workflows, up from 12.3% in early 2024. The top adopters?
- Legal tech: 42.3% use it for contract analysis and clause extraction.
- Medical diagnostics: 37.8% use it to cross-reference symptoms, lab results, and drug interactions.
- Financial analytics: 35.1% apply it to multi-step forecasting and risk modeling.
But adoption isn’t even. Only 22.4% of professional developers say they’re highly confident in building effective decomposition prompts. Most struggle with two things: knowing how granular to make sub-questions, and whether to verify each step.
On Reddit and HackerNews, users who nailed it shared tips:
- "Start broad, then refine. Don’t split into 10 tiny questions-3-5 is enough."
- "Always add: ‘Does this answer make sense? Yes/No. If no, revise.’"
- "Test your decomposition with a human first. If a person can’t solve it step-by-step, neither can the model."
Tools like PromptLayer, LangChain, and PromptHub now offer templates and validation layers to help. But the real skill? Knowing when to use it-and when not to.
The Future: Automation Is Coming
OpenAI’s GPT-4.5, released in November 2025, now auto-generates decomposition steps. You don’t have to write "Follow up:" anymore. The model does it for you. That’s a game-changer. It reduces implementation effort by 63%, according to OpenAI’s blog.
Anthropic is going further. Claude 4, launching in 2026, will fact-check each intermediate answer against verified knowledge sources. No more guessing if Ben Crenshaw really won in 1994. The system will pull from trusted databases.
That’s the trend: from manual prompting to automated reasoning. But the core idea won’t disappear. Even as models get smarter, decomposition will stay relevant. Why? Because transparency matters. Because audit trails matter. Because when a medical AI says "This patient has a 72% chance of sepsis," you need to know how it got there.
Getting Started
If you’re new to this, start small. Pick a question with two clear facts to link. Example: "What was the population of Tokyo in 2020, and how many people live in the Greater Tokyo Area?"
Write the prompt like this:
Question: What was the population of Tokyo in 2020, and how many people live in the Greater Tokyo Area?
Follow up: What was the population of Tokyo in 2020?
Intermediate answer: [Model answers]
Follow up: What is the estimated population of the Greater Tokyo Area?
Intermediate answer: [Model answers]
Final answer: [Model synthesizes]
Then ask: "Does this answer make sense? Yes/No. If no, revise."
Practice with 10-15 examples. You’ll get better in 8-12 hours. The key isn’t memorizing templates. It’s learning to spot natural breakdown points. If a question feels like it has two parts, it probably does. Split it.
When Not to Use It
Don’t use decomposition for:
- Open-ended creative tasks (poetry, storytelling)
- Questions with no clear factual anchors ("What is happiness?")
- Real-time systems where speed beats accuracy
- Simple yes/no questions
It’s a scalpel, not a hammer. Use it when precision matters. Skip it when it adds noise.
What’s the difference between Self-Ask and Chain-of-Thought?
Chain-of-Thought lets the model reason internally, writing out steps as part of its output. Self-Ask forces it to generate explicit, separate sub-questions and answers, making each step visible and verifiable. Self-Ask is more structured, auditable, and often more accurate on multi-step tasks.
Do I need a special model to use Self-Ask?
No. Self-Ask works with any LLM-GPT-4o, Claude 3, Llama 3, or others. It’s a prompt design technique, not a model upgrade. You don’t need to pay for a more expensive API. Just structure your prompt differently.
Why does decomposition improve accuracy?
Because it reduces cognitive load. Instead of juggling multiple facts at once, the model focuses on one piece at a time. This mimics how humans solve hard problems-break it down, solve each part, then combine. Studies show this cuts hallucinations and improves reasoning alignment with ground truth.
Is Self-Ask worth the extra cost and latency?
Only if accuracy matters more than speed. For customer support bots, maybe not. For legal contract reviews, medical diagnostics, or financial analysis-yes. The 35-47% increase in tokens means higher API costs and slower responses. But if you’re making decisions based on the output, the trade-off often pays off.
Can I combine Self-Ask with other techniques?
Yes. Many advanced users combine Self-Ask with verification steps, self-consistency, or even external tools. For example: ask a question → generate sub-questions → answer them → then run each answer through a fact-checking API. This layered approach is becoming standard in enterprise use.
What’s the biggest mistake people make with decomposition?
Making sub-questions too small or too vague. If you split a question into 10 tiny parts, you create noise. If you split it into 2 vague ones, you miss key steps. The sweet spot is 3-5 clear, logically connected sub-questions. Always test your decomposition with a human first.
Tom Mikota
February 15, 2026 AT 18:35Okay, but let’s be real-this whole ‘self-ask’ thing is just Chain-of-Thought with extra steps and a PowerPoint slide.
Do we really need to force the model to write ‘Follow up:’ like it’s a kindergarten journal? I get the theory, but in practice, I’ve seen GPT-4o guess better without all the scaffolding.
And don’t even get me started on the 40% cost spike. My boss already thinks I’m burning money just to make chatbots sound like philosophy majors.
Tina van Schelt
February 17, 2026 AT 16:41I love how this post breaks down something so technical into something that actually feels human.
It’s like someone took the dry, jargon-heavy papers and turned them into a conversation you’d have over coffee with a friend who actually knows what they’re talking about.
I’ve been using decomposition for legal docs at work, and honestly? It’s been a game-changer. No more ‘uhhh, I think it says…’ moments.
Also, the part about testing with a human first? Chef’s kiss. So many teams skip that and wonder why the AI’s ‘logical’ conclusion is nonsense.
Daniel Kennedy
February 18, 2026 AT 01:59You people are overcomplicating this. Self-ask isn’t magic-it’s discipline.
If your model can’t handle a two-step question without hallucinating, you’re not using the right prompt-you’re using a blunt instrument.
And yes, it costs more. So what? If you’re using LLMs for medical diagnostics or contract review and you’re budgeting like it’s a TikTok ad campaign, you’re already failing.
Let me tell you about the startup that saved $2M in litigation costs last year because their AI caught a hidden clause that human lawyers missed. They used decomposition. Not because it was trendy, but because it worked.
Stop whining about tokens. Start thinking about outcomes.
Taylor Hayes
February 19, 2026 AT 19:29I’ve been experimenting with this for a few weeks, and I have to say-it’s not about the technique alone.
It’s about the mindset shift.
Before, I’d just throw a question at the model and hope for the best. Now, I pause. I ask myself: ‘What’s the first thing this model needs to know?’ Then the next. And the next.
It feels slower, but it’s actually faster in the long run because you’re not debugging five layers of nonsense later.
Also, adding ‘Does this make sense? Yes/No’? Brilliant. I didn’t think of that. Thank you.
And yeah, I agree with the part about not using it for poetry. I tried it once to generate a love letter. The AI asked: ‘Follow up: What is the emotional state of the recipient?’… I just… I just closed the tab.
Sanjay Mittal
February 20, 2026 AT 16:14Interesting approach. I’ve used this in financial forecasting for Indian market data, and it works surprisingly well when the facts are clear.
But here’s a real-world issue: many of our data sources are outdated or inconsistent.
So even if the decomposition is perfect, if the first intermediate answer is wrong (e.g., ‘GDP growth was 6.2% in 2023’ when it was actually 5.8%), the whole chain collapses.
That’s why I combine it with external validation APIs. Not perfect, but better than blind faith in the model’s ‘logic’.
Jamie Roman
February 22, 2026 AT 02:52So I’ve been using decomposition for customer service bots, and honestly, it’s been a mixed bag.
On one hand, when a user asks something like ‘Why was my refund denied?’ and you break it down into ‘What’s the return policy? Did they meet the deadline? Was the item damaged?’, the model gives a way more coherent answer.
But on the other hand, if the user just wants a yes/no-‘Can I get a refund?’-and you force it into a 5-step breakdown? They get frustrated. They leave. They tweet about how ‘AI is ruining customer service.’
It’s not that the method doesn’t work-it’s that context matters more than technique.
I’ve started using a hybrid: if the question feels complex, I decompose. If it’s simple? I let the model wing it.
Also, the 35-47% token increase? Yeah, that’s real. Our AWS bill went up 30%. We had to cap it to 3 decomposed steps max. Trade-offs, people.
Salomi Cummingham
February 22, 2026 AT 14:50Oh my god. I just read this and I feel like I’ve been handed a secret key to a door I didn’t even know was locked.
I’ve been wrestling with AI-generated reports for months-vague, contradictory, fluff-filled nonsense-and now I see why.
It wasn’t the model. It was me. I was asking it to be a psychic.
Now I write prompts like I’m coaching a nervous intern: ‘First, find X. Then, check Y. Then, compare to Z.’ And suddenly-clarity.
One of my team members cried when the AI got a complex tax question right for the first time. I didn’t know that was possible.
And yes, it’s slower. But slower is better than wrong.
And if you’re still using direct prompts for anything that involves more than one fact? Honey. You’re not working with AI. You’re gambling with it.
Johnathan Rhyne
February 23, 2026 AT 17:47Wait, wait, wait-hold on. You say self-ask improves accuracy to 82.1%? That’s cute.
But did you check if the arXiv paper even exists? Because 2505.01482v2? That’s a fake ID. arXiv IDs don’t start with 25 for May 2025. That’s next year.
And ‘GPT-4.5 released in November 2025’? OpenAI hasn’t even announced GPT-4.1 yet. This whole thing reads like a speculative blog post dressed up as research.
Also, ‘decomposition prompting’ isn’t even a real term. It’s just ‘step-by-step reasoning’ with extra commas.
Don’t get me wrong-I love structured prompting. But don’t invent fake citations and pretend they’re gospel. That’s worse than bad AI. It’s bad science.