Tag: transformer architecture

Long-Form Generation with Large Language Models: Mastering Structure, Coherence, and Accuracy
Learn how to achieve reliable long-form content with LLMs by mastering structure, preventing drift, and implementing rigorous fact-checking workflows.
Read more
Autoregressive Generation in Large Language Models: Step-by-Step Token Production
Explore how autoregressive Large Language Models generate text step-by-step. Learn about token production, causal masks, exposure bias, and comparison with other architectures.
Read more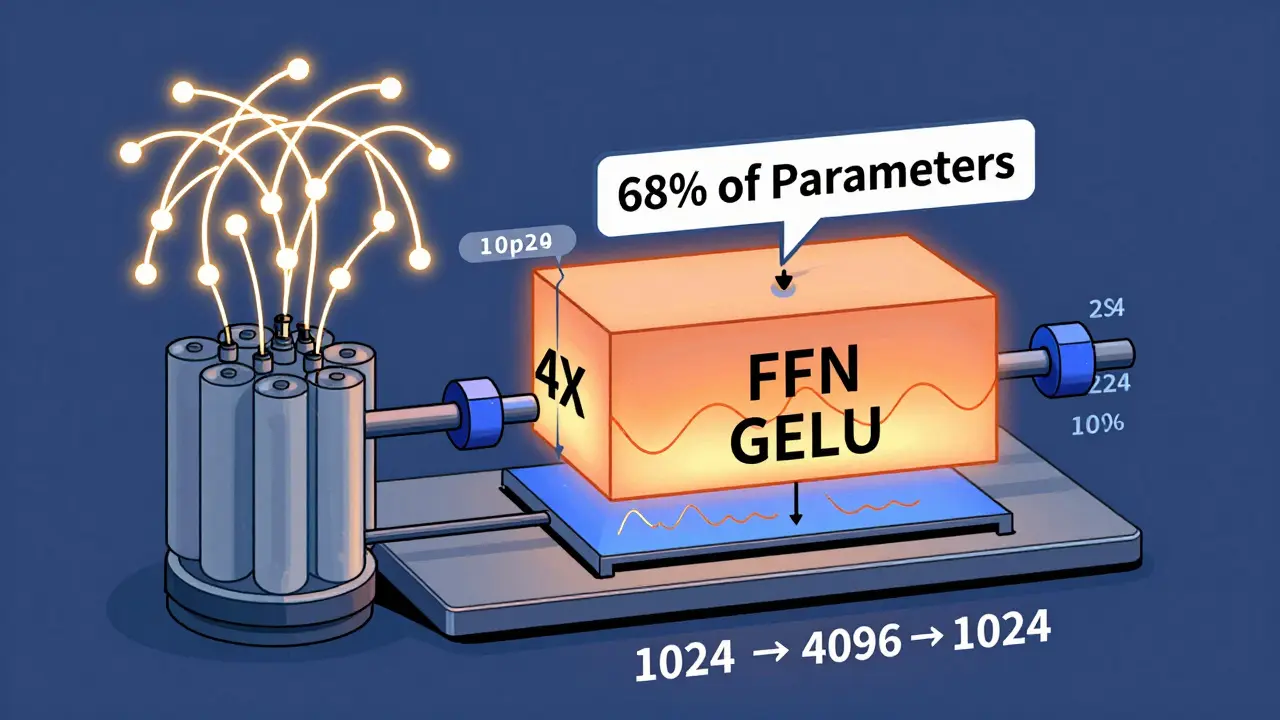
Feedforward Networks in Transformers: Why Two Layers Boost Large Language Models
The two-layer feedforward network in transformers isn't just a default - it's the key to why large language models work so well. Here's why it outperforms simpler or deeper alternatives, and why it's still the industry standard in 2026.
Read more
Key Components of Large Language Models: Embeddings, Attention, and Feedforward Networks Explained
Understand the three core parts of large language models: embeddings that turn words into numbers, attention that connects them, and feedforward networks that turn connections into understanding. No jargon, just clarity.
Read more