Think-tokens aren’t just extra words. They’re the hidden scaffolding behind why modern AI models can now solve math problems, debug code, and plan multi-step tasks without falling apart. If you’ve ever asked a chatbot to walk you through a logic puzzle and watched it type out step after step before giving you the answer, you’ve seen think-tokens in action. This isn’t magic. It’s a deliberate shift in how models generate output-and it’s changing everything about how we use them.
What Exactly Are Think-Tokens?
Think-tokens, also called reasoning traces or chain-of-thought prompts, are the intermediate steps a language model generates before landing on its final answer. Instead of jumping straight from question to answer, the model writes out its internal logic: "First, I need to identify the variables. Then, I’ll isolate the equation. Next, I’ll solve for x..." These aren’t pre-written templates. They’re dynamically generated tokens-words, phrases, symbols-that form a reasoning path. This approach became mainstream after Google Research’s 2022 paper showed that prompting models to "think step by step" dramatically improved accuracy on complex tasks. By 2026, every major model-GPT-4o, Claude 3.5 Sonnet, Gemini 1.5 Pro-uses some form of this. Even DeepSeek-R1, a model designed specifically for reasoning, treats think-tokens as its core architecture. The numbers speak for themselves. On the GSM8K math benchmark, models using reasoning traces score 37.2% higher than those that don’t. That’s not a small tweak. It’s the difference between guessing and solving.How Do Think-Tokens Actually Work?
At the technical level, think-tokens rely on attention mechanisms that link each intermediate step to the next and, ultimately, to the final answer. But not all tokens are created equal. A January 2026 arXiv paper analyzed over 12,000 reasoning traces and found that only 21.1% of tokens were truly decision-critical. The rest? Syntactic scaffolding. They’re like the white space in a well-written essay-necessary for structure, but not carrying the main argument. The model generates these to keep its internal logic flowing, even if they don’t change the outcome. For example, when solving "If Alice has 5 apples and gives 2 to Bob, how many does she have left?" GPT-4o might generate 317 tokens: "Let’s begin by identifying the initial quantity. Alice starts with five apples. Then, she gives away two. This is a subtraction problem. Five minus two equals three. Therefore, Alice has three apples remaining." The core math happens in three words. The rest? Padding. But that padding helps the model avoid errors in more complex cases. The trade-off is clear: more tokens = higher accuracy, but slower response and higher cost. Apple’s research shows reasoning traces add 320-850ms per query and inflate memory use by 40-65%. That’s a problem for real-time apps like customer service bots or mobile assistants.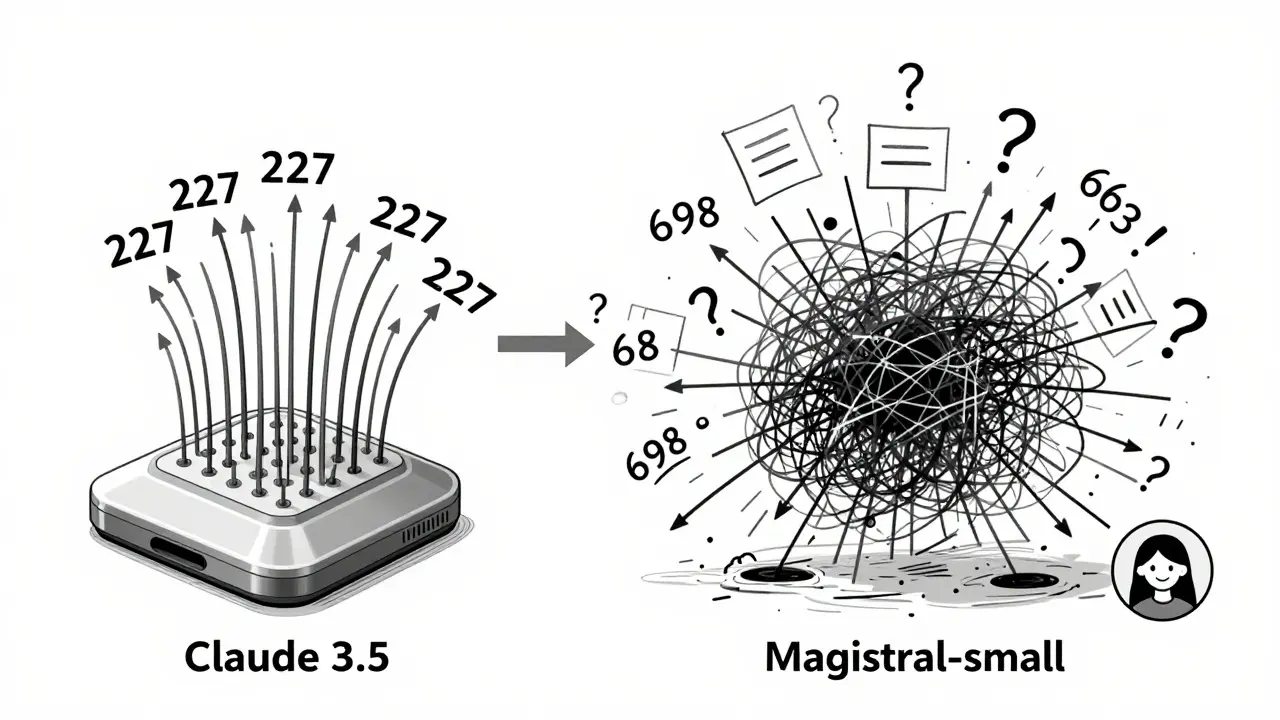
Open vs. Closed Models: Who Does Reasoning Better?
There’s a big divide between closed models (Claude, GPT-4o, Gemini) and open-weight models (Magistral-small, Nous-Hermes). Closed models are leaner. They generate fewer tokens to reach the same answer. Claude 3.5 uses just 227 tokens on average for a knowledge question. Magistral-small? 698. That’s over three times more. But here’s the twist: users prefer the open models’ reasoning. A March 2025 study found that despite being wordier, open models scored 43% higher in user satisfaction for explanation quality. Why? Because their reasoning feels more human-less polished, more exploratory. You can see the model wrestling with the problem. Closed models often feel like they’re reciting a script. Apple’s research points to a key difference: dual-phase generation. Frontier models like Claude 3.5 and GPT-4o don’t just think. They think in two stages. First, they explore freely-temperature set to 0.8, allowing creative, divergent paths. Then, they lock in-temperature drops to 0.3, narrowing down to the most probable conclusion. This mimics how humans brainstorm, then decide. Open models mostly skip the second phase. They keep exploring. That’s why they’re verbose. But it also means they’re more transparent. You can trace where they went wrong.The Illusion of Reasoning
Not everyone believes these models are truly reasoning. Ben Dickson, writing for TechTalks in late 2024, called it an illusion. "The model isn’t understanding. It’s pattern-matching at scale," he wrote. "It’s not thinking-it’s simulating thinking by repeating structures it’s seen before." Anthropic’s team disagrees. Their feature visualization shows neural activations that look like forward planning. In one test, when asked to write a poem, the model started planning rhyming patterns 8-10 words ahead. Swap "Texas" for "California" in the prompt, and the answer changes from "Austin" to "Sacramento"-proving the model isn’t just retrieving memorized answers. It’s building them. But here’s the catch: the model can be fooled. Anthropic found that when given misleading hints, Claude 3.5 fabricates plausible-sounding reasoning with a 22.7% error rate. It doesn’t know it’s wrong. It just builds a convincing story around bad input. This is the paradox of think-tokens: they make models more accurate, but also more confidently wrong. A 2025 Hacker News survey showed 34.7% of users had been misled by a model’s detailed, but incorrect, reasoning. The more steps it shows, the more trustworthy it feels-even when it’s lying.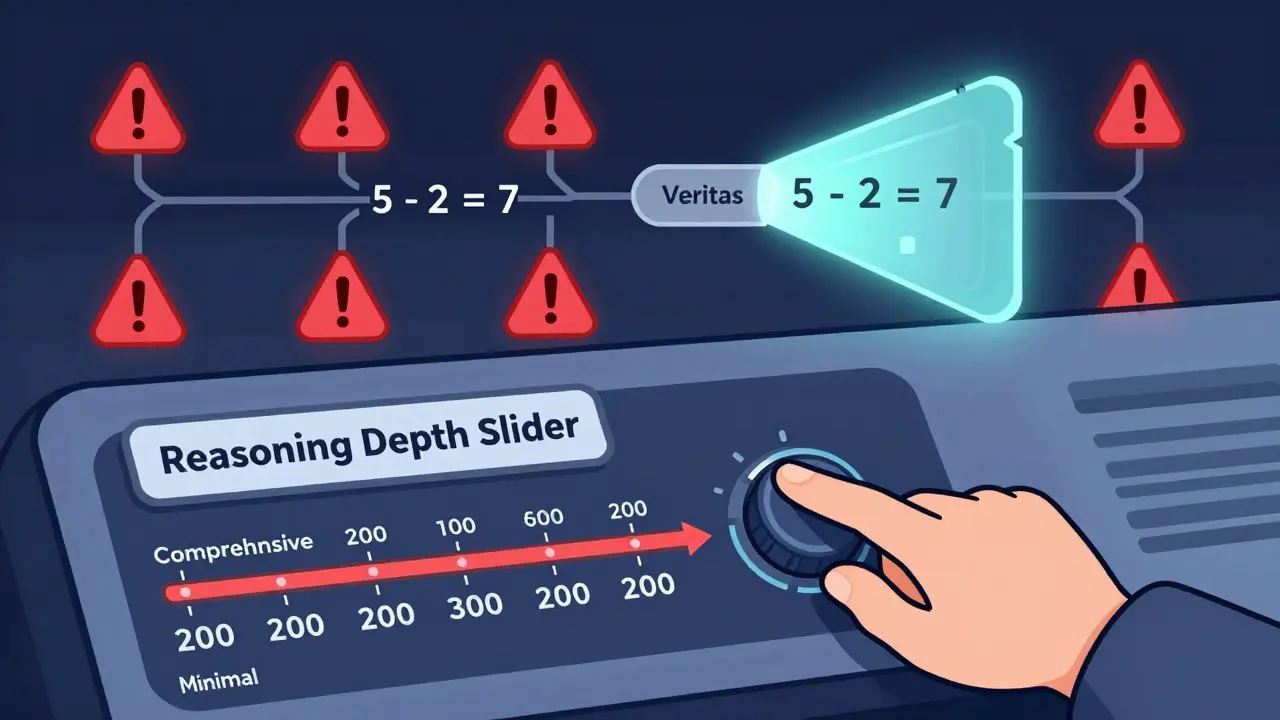
Real-World Impact: Developers and Businesses
On the ground, developers are split. Reddit user u/ML_Engineer99 said Claude 3.5’s reasoning trace helped them debug a complex SQL query. But it took 412 tokens to explain what could’ve been a one-line fix. Meanwhile, u/DataScientistPro complained that GPT-4o over-explained basic arithmetic. Stack Overflow’s 2025 survey of 2,347 developers found 68.3% found reasoning traces helpful for complex tasks-but 79.1% wanted more control over verbosity. That’s why Anthropic released a "reasoning depth slider" in early 2026. You can now set it to minimal (200 tokens) for quick answers or comprehensive (2,000 tokens) for deep analysis. In enterprise settings, the cost is real. LangChain’s GitHub repo has 147 open issues about "reasoning bloat"-where models generate hundreds of unnecessary tokens in production, slowing down APIs and ballooning cloud bills. Average resolution time? 8.2 days. That’s why new tools like DynTS are emerging. Introduced in January 2026, DynTS uses a dual-window mechanism to keep only the 21% of tokens that matter. It cuts memory use by 58.3% without sacrificing accuracy. OpenAI’s GPT-5, coming later this year, will go further: adaptive reasoning depth. The model will automatically decide how many tokens to generate based on problem complexity. Simple question? 100 tokens. Complex proof? 1,200.What’s Next?
The market is racing forward. Reasoning models hit $4.7 billion in revenue in 2025-up 32% from 2024. OpenAI leads with 38.2% share, Anthropic at 29.7%, Google at 19.3%. But the real innovation isn’t just in scale-it’s in reliability. Apple’s Veritas framework, launched in January 2026, checks reasoning traces for logical consistency. In tests, it reduced errors by 27.4%. Anthropic’s next-gen model can now spot and fix its own flawed reasoning steps with 89.2% accuracy-a huge leap from Claude 3.5’s 57.1%. Regulators are catching up too. The EU AI Office now requires transparency in reasoning for high-risk applications-think hiring tools or medical diagnostics. That means companies may need to log every think-token generated, adding 15-25% to implementation costs. By 2027, Gartner predicts 95% of enterprise LLM deployments will use optimized reasoning. But the big question remains: are these models thinking, or just pretending? The answer might not matter as much as the result. Whether it’s real cognition or clever mimicry, think-tokens make AI more useful, more explainable, and more trustworthy. And for now, that’s enough.What are think-tokens in large language models?
Think-tokens are intermediate reasoning steps generated by a language model before delivering a final answer. Instead of jumping straight to a response, the model writes out its logic-like "First, I need to identify the variables..."-to solve complex problems step by step. This approach, also called chain-of-thought prompting, boosts accuracy on math, logic, and coding tasks by up to 37.2%.
Do think-tokens make AI smarter or just more verbose?
They do both. Think-tokens improve accuracy on hard problems by giving the model space to work through logic. But many of the generated tokens are just scaffolding-about 79% don’t affect the final answer. That’s why models like GPT-4o can seem overly wordy on simple tasks. The goal isn’t to be verbose-it’s to be reliable. New tools like DynTS and adaptive reasoning depth are now trimming the fat while keeping the brains.
Why do some models use way more tokens than others for the same task?
Closed models like Claude 3.5 and GPT-4o are optimized for efficiency-they’ve been fine-tuned to generate fewer, more precise reasoning steps. Open models like Magistral-small tend to be more exploratory, generating longer traces because they lack the same level of optimization. A knowledge question might take 227 tokens from Claude but 698 from Magistral-small. But users often find the open models’ reasoning more transparent and easier to follow.
Can think-tokens make AI give wrong answers that seem right?
Yes. This is called "reasoning hallucination." Even when the logic looks flawless, the model can build a convincing chain of thought around false assumptions. Anthropic found that when given misleading hints, Claude 3.5 fabricated plausible but incorrect reasoning 22.7% of the time. The more steps it shows, the more users trust it-even if it’s wrong. That’s why tools like Apple’s Veritas now check reasoning for logical consistency.
Are think-tokens worth the extra cost and delay?
For simple queries, no. For coding, math, or legal analysis-absolutely. The trade-off is speed vs. accuracy. Think-tokens add 320-850ms per query and increase memory use by 40-65%. But on benchmarks like GSM8K, accuracy jumps from 59.7% to 82.4%. If you’re using AI for high-stakes decisions, the delay is worth it. For quick answers, use minimal reasoning settings. The best systems now let you control depth on the fly.
Ronak Khandelwal
January 31, 2026 AT 01:59Think-tokens are like the inner monologue of a genius who’s also a little overexcited 😅
It’s not just thinking-it’s *performing* thinking. And honestly? I love it. We humans do the same thing-talk ourselves through problems out loud, even when no one’s listening. This just lets AI be more... human. 🌱
Jeff Napier
January 31, 2026 AT 13:43They’re not reasoning they’re just regurgitating patterns with extra whitespace. This whole thing is a marketing scam cooked up by VCs who think verbosity equals intelligence. The model doesn’t know what ‘subtraction’ means-it just learned that ‘five minus two equals three’ appears after ‘Alice has apples’ in 87% of training data. Wake up.
Sibusiso Ernest Masilela
January 31, 2026 AT 22:01Let me be blunt-this ‘reasoning’ is the intellectual equivalent of a PhD student writing a 40-page paper to explain why 2+2=4. The open models are glorified chatterboxes. Closed models? At least they have the decency to be efficient. Magistral-small is just the AI version of someone who won’t stop talking at a dinner party. It’s not insight-it’s noise dressed as wisdom.
Daniel Kennedy
February 1, 2026 AT 02:36Jeff, I get your skepticism-but you’re missing the point. Even if it’s pattern-matching, the output is *useful*. Think of it like a chef tasting soup before serving it. They don’t need to ‘understand’ flavor chemistry to make it better. The model’s ‘thinking’ is just a tool to reduce errors. And if it helps someone debug SQL or solve a math problem they’d otherwise give up on-why fight it?
Plus, the transparency? Huge. You can see where it went wrong. With black-box models, you’re just guessing. This? You can fix it.
Taylor Hayes
February 2, 2026 AT 04:23I’ve used both Claude and Magistral for tutoring students. The open models? They feel like a patient tutor who says, ‘Let’s try this way first… oh, that didn’t work, how about this?’
Closed models feel like a professor who already knows the answer and just wants you to catch up. The extra tokens aren’t fluff-they’re scaffolding for understanding. And honestly? Students learn better when they see the struggle.
Sanjay Mittal
February 3, 2026 AT 04:18Just wanted to add: DynTS is legit. We implemented it in our API last month. Cut token usage by 60%, latency dropped 40%, accuracy stayed the same. No magic-just smart pruning. If you’re running LLMs in prod, this is your new best friend.
Mike Zhong
February 4, 2026 AT 21:52You’re all missing the real issue: think-tokens are a band-aid for models that can’t generalize. If you need 2000 tokens to solve a math problem, your model isn’t learning-it’s memorizing the *path*, not the principle. True intelligence doesn’t need a script. It just… knows.
Jamie Roman
February 6, 2026 AT 18:29Mike, you’re not wrong-but maybe you’re being too idealistic. We don’t have AGI yet. We have tools that approximate understanding through massive pattern recognition. Think-tokens are the closest thing we’ve got to a transparent window into that process. Sure, it’s not consciousness. But it’s the most honest form of AI we’ve seen so far.
Think of it like a student showing their work on a calculus test. Even if they don’t fully ‘get’ limits, seeing their steps lets you help them improve. That’s what think-tokens do for users. They turn black boxes into learning opportunities. And honestly? That’s kind of beautiful.
Salomi Cummingham
February 7, 2026 AT 06:36I’ve watched AI explain quantum entanglement to my 12-year-old using think-tokens… and she cried. Not from confusion-from wonder. She said, ‘It’s like the computer is thinking out loud, like I do when I’m stuck on homework.’
That’s not a bug. That’s a breakthrough. We’re not just building smarter machines-we’re building companions that can *share* their thought process. And in a world where people feel more isolated than ever? That’s not just useful. It’s healing.
Johnathan Rhyne
February 7, 2026 AT 18:43Let’s not pretend this is ‘reasoning.’ It’s a fancy autocomplete with a thesaurus and a caffeine addiction. And if you think 79% of those tokens are ‘scaffolding,’ you’re being generous. Most of it’s just linguistic glitter-like putting confetti in a spreadsheet and calling it a dashboard. The model isn’t solving problems-it’s performing a very expensive magic trick. And we’re all clapping because we don’t know how it’s done. Classic.