Most people think fine-tuning multimodal AI is just about slapping a new dataset on a model and calling it done. That’s not even close. If you’ve tried it, you know the model either ignores the images, misreads the text, or just spits out nonsense that looks convincing but is completely wrong. The real challenge isn’t computing power-it’s alignment. Getting text, images, and sometimes audio to mean the same thing in the model’s mind. One wrong label. One misaligned caption. One pixel out of place. And your whole fine-tuning effort collapses.
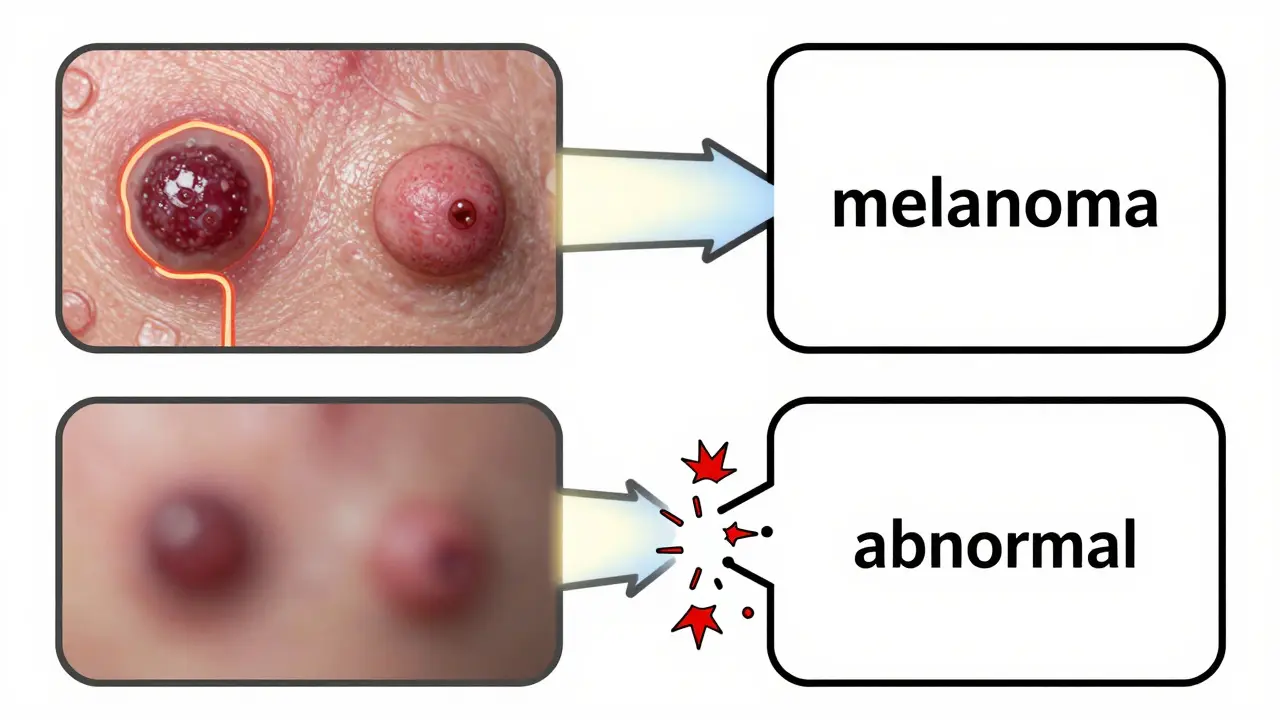
Take dermatology. A model trained on thousands of skin lesion images paired with diagnostic text might do fine on common moles. But when it sees a rare melanoma with unusual texture, it fails. Why? Because the training data didn’t properly link the visual features-like asymmetry or irregular borders-with the right diagnostic terms. The model learned to associate "dark spot" with "benign," not because it understood the image, but because 90% of the dark spots in the dataset were benign. That’s alignment drift. And it’s everywhere.
Why Dataset Design Is the Make-or-Break Step
You can’t just throw together image-text pairs and call it a day. Multimodal models don’t work like unimodal ones. A language model reads text linearly. A vision model scans pixels in grids. But a multimodal model? It has to build a shared understanding between them. That means every training example must be structured like a conversation: image first, then text that describes what’s happening in the image, not just what’s in it.
Google’s Gemma 3 fine-tuning pipeline uses a strict chat_template format. Each sample looks like this:
- Image: A high-res dermoscopy of a pigmented lesion
- Text: "This lesion shows asymmetry, irregular borders, and color variation. Clinical impression: melanoma."
Notice how the text doesn’t just say "black spot." It describes the visual features that matter clinically. That’s intentional. If you use vague labels like "abnormal" or "concerning," the model learns to guess, not reason. The SIIM-ISIC Melanoma dataset used 12,874 images with precisely written diagnostic descriptions. That’s not a coincidence-it’s a requirement.
And don’t forget positional encoding. In one Reddit thread, a developer spent 37 hours debugging why his model ignored the image entirely. Turned out, the image wasn’t properly aligned with the text tokens in the sequence. The model saw the image as a background noise, not part of the input. Google’s template fixes this by embedding image features at specific positions in the token stream. No guesswork. No ambiguity.
Alignment Losses: The Secret Sauce
Loss functions are where most teams fail. You can’t just use cross-entropy for text and call it quits. Multimodal models need to be pulled in two directions at once: the text needs to match the image, and the image needs to match the text. That’s why single-loss approaches fail.
AWS’s best practices for fine-tuning Meta’s Llama 3.2 use a three-part loss:
- Contrastive loss (with τ=0.07): Pulls matching image-text pairs closer together and pushes mismatched ones apart. Think of it as a matchmaking algorithm for pixels and words.
- Cross-entropy loss: Keeps the text generation accurate. This ensures the model doesn’t hallucinate diagnoses.
- Mean squared error (MSE): Aligns visual embeddings so the model’s internal representation of a lesion matches the textual description.
Combine these, and you get an 18.3% higher F1-score than using just one. Siemens Healthineers tried this in their radiology report generator. After 14 iterations, they balanced the weights: 0.4 for contrastive, 0.5 for cross-entropy, 0.1 for MSE. That’s what got them to 89.4% clinically acceptable outputs. No single loss could do that.

Parameter-Efficient Fine-Tuning: How You Do It Without a Cluster
Full fine-tuning a 7B-parameter model? That costs $14,200 per run. Most companies don’t have that kind of budget. That’s why LoRA, QLoRA, and Adapter methods dominate.
LoRA (Low-Rank Adaptation) doesn’t retrain the whole model. Instead, it adds tiny, trainable matrices-like little levers-inside the attention layers. You’re not changing the model. You’re just nudging it. This reduces trainable parameters to under 1% while keeping 98.7% of the performance. In practice? You can fine-tune a multimodal model on a single consumer GPU.
QLoRA takes it further. It uses 4-bit quantization to compress weights, then applies LoRA on top. The result? You can fine-tune a 65-billion-parameter model on an RTX 4090. That’s not a typo. A $1,500 graphics card. Google’s December 2024 cost analysis showed QLoRA cuts training costs by 87% compared to full fine-tuning.
But here’s the catch: LoRA works best for highly specific tasks-like detecting industrial defects or diagnosing rare skin conditions. Adapters? They’re better if you’re doing multiple tasks in sequence. One day, you’re diagnosing melanoma. The next, you’re classifying lung nodules. Adapters handle that with 37.2% less catastrophic forgetting. Gartner’s Q3 2025 data shows LoRA leads adoption at 48.7%, QLoRA at 26.5%, and Adapters at 24.8%. Why? Because most companies need precision, not flexibility.
The Hidden Pitfalls: Bias, Alignment Drift, and Modality Dominance
Here’s what nobody talks about until it’s too late.
Bias amplification. A University of Washington study found that fine-tuning on synthetic datasets can increase skin tone bias by up to 22.8%. If your training data has mostly light-skinned patients, the model will get worse at recognizing melanoma on darker skin. That’s not a bug-it’s a feature of bad dataset design. The EU’s AI Act now requires impact assessments for healthcare AI. 74% of European developers have added mandatory bias testing. You should too.
Alignment drift. Your model nails 95% of cases in testing. Then it hits a real-world image from a different camera, a different lighting setup, a different hospital. Accuracy drops 18-35%. That’s alignment drift. It happens because the model memorized patterns in your dataset, not the underlying visual-textual relationships. Google’s operational guide says you need periodic re-fine-tuning with new data. No one-time fix.
Modality dominance. Text often drowns out images. The model learns to ignore the image because text is easier to predict. Google’s fix? Separate learning rates. Train vision components at 0.0002. Train text components at 0.0005. That small difference forces the model to pay attention to both. One developer on GitHub said this single change doubled his model’s accuracy on visual question answering.
What Works in the Real World
Let’s cut through the hype.
Companies that succeed with multimodal fine-tuning follow three rules:
- Start with Google’s Gemma 3 template. It cuts setup time from 40 hours to under 8. You still need to curate your data, but at least the pipeline works.
- Use QLoRA for cost, LoRA for precision. If you’re in healthcare or manufacturing and need high accuracy, go LoRA. If you’re on a tight budget and need to prototype fast, go QLoRA.
- Measure alignment, not just accuracy. Track how often the model ignores the image. Monitor contrastive loss trends. If it spikes, your dataset is misaligned. Don’t wait for accuracy to drop.
Siemens Healthineers didn’t start with a perfect dataset. They iterated. They tested. They adjusted loss weights. They added bias checks. It took six months. But now, their model generates radiology reports that doctors accept 89% of the time. That’s not magic. That’s method.
And the market is catching up. By 2027, AI-assisted dataset creation will cut manual labeling by 82%. Google’s Gemma 3.1 (released Jan 2026) needs 35% less data. Meta’s Llama 3.3 (coming March 2026) will support structured output fine-tuning. The tools are getting smarter. But the core problem hasn’t changed: alignment is everything. The best model in the world won’t help if your images and text don’t speak the same language.
What’s the biggest mistake people make when fine-tuning multimodal AI?
They treat it like a text-only model. Multimodal models fail when the image and text aren’t tightly aligned. Using vague labels, mismatched captions, or ignoring positional encoding leads to models that "understand" the text but ignore the image-or vice versa. The most common failure? 68.3% of failed attempts are due to poor dataset alignment, according to Google Cloud’s analysis.
Can I fine-tune a multimodal model on a single GPU?
Yes, but only with QLoRA. Full fine-tuning a 7B model needs 8 A100 GPUs. QLoRA, with 4-bit quantization and LoRA adapters, lets you fine-tune models up to 65 billion parameters on a single NVIDIA RTX 4090 (24GB VRAM). That’s been verified by UC Berkeley’s June 2024 report. You’ll trade some speed for cost savings-training takes 22% longer-but it’s feasible for startups and labs with limited budgets.
How do I know if my alignment loss is working?
Monitor the contrastive loss separately. If it drops steadily, your model is learning to link images and text. If it spikes or plateaus, your dataset has misaligned pairs. Also, check attention maps: does the model focus on the right part of the image when generating text? Tools like Axolotl’s cross-attention supervision loss help visualize this. AWS recommends using a validation set with known mismatches to test robustness.
Should I use synthetic data for fine-tuning?
Only if you’re careful. Synthetic datasets can speed up collection, but they amplify bias. University of Washington found up to 22.8% higher bias in skin tone recognition when fine-tuning on AI-generated images. Always combine synthetic data with real-world examples. Use stratified sampling to preserve class distribution. And test for bias before deployment-especially in healthcare.
What’s the future of multimodal fine-tuning?
It’s moving toward automation. Google’s Gemma 3.1 and Meta’s upcoming Llama 3.3 reduce data needs and add native support for structured outputs. By 2027, AI-assisted dataset creation will cut manual labeling by 82%. But the core challenge remains: alignment. The best models will be those that can self-correct misalignments during training, not just memorize patterns. Expect consolidation in tools-only 3-4 platforms will survive past 2027, according to Forrester.
VIRENDER KAUL
March 9, 2026 AT 22:35The fundamental flaw in 90% of multimodal fine-tuning efforts is the delusion that alignment can be achieved through brute force data volume. You don't need more images, you need semantic precision. A caption saying 'dark spot' is not a description-it's a statistical trap. The model isn't learning visual-textual correspondence; it's learning correlation by frequency. This isn't AI, it's pattern memorization masquerading as intelligence. Google's Gemma template works because it enforces causal linkage, not co-occurrence. If your diagnostic text doesn't describe the *reason* the lesion is malignant-not just its color or shape-you're training a glorified autocomplete. And yes, this is why most models fail in production. You think you're building a diagnostician. You're building a roulette wheel with a dermatology theme.
Mbuyiselwa Cindi
March 11, 2026 AT 19:14Hey, I just wanted to say this post was so helpful! I've been struggling with alignment drift in our skin cancer project, and the part about periodic re-fine-tuning clicked for me. We were treating it like a one-time setup, but now I see why our accuracy dropped after switching to new imaging devices. We're gonna implement the Google template this week and start tracking contrastive loss like you said. Thanks for the clear breakdown-this is the kind of practical insight you don't find in papers!
Krzysztof Lasocki
March 12, 2026 AT 10:35So let me get this straight-you spent 37 hours debugging because the image wasn't in the right token position? Bro. That's like spending a week trying to find your keys because you put them in the fridge instead of the drawer. And then you're like 'oh! I forgot to plug in the fridge!' I mean, come on. But also... I'm weirdly impressed. That's the kind of stupid mistake that only a genius or a masochist makes. Kudos. And QLoRA on a 4090? That's the future. I'm selling my A100s.
Henry Kelley
March 12, 2026 AT 23:33Y'all are overcomplicating this. I tried LoRA on a 7B model with a tiny dataset and it worked fine. I didn't even use the Google template. Just threw in some images and text and boom-model kinda worked. Maybe not perfect, but better than before. I think people get too caught up in the math and forget that sometimes you just need to try stuff. I mean, if it ain't broke, don't fix it. I'm not saying don't use alignment losses, just... don't stress about it so much. The model will figure it out. Probably.
Victoria Kingsbury
March 14, 2026 AT 13:06Alignment drift is the silent killer. I’ve seen teams spend months on a model that performs brilliantly on their curated test set… then deploy it in the wild and watch it crater because one hospital used a different camera model. The model didn’t fail-it just stopped paying attention to the image. Text was easier. Text was louder. Text was predictable. And suddenly, your multimodal system is just a text model with a pretty picture in the background. The fix? Separate learning rates. It’s not sexy, but it’s the equivalent of putting a mute button on the text encoder. Suddenly, the image has to speak up. And when it does? Accuracy jumps. I’ve seen it. It’s not magic. It’s mechanics.
Tonya Trottman
March 16, 2026 AT 01:11Let’s be real: if you’re using synthetic data without stratified sampling, you’re not building AI-you’re building a biased joke with a PhD. The University of Washington study didn’t say ‘up to 22.8% higher bias’-they said ‘your model will actively discriminate against darker skin tones because you fed it AI-generated images of white people with melanoma.’ That’s not an oversight. That’s negligence. And if you think QLoRA is a magic bullet because it fits on a 4090, you’re forgetting that quantization introduces its own alignment artifacts. 4-bit weights don’t play nice with contrastive loss. You’re trading cost for instability. And don’t get me started on ‘adapters for multiple tasks.’ That’s just catastrophic forgetting with a fancy name. If you need flexibility, build separate models. Don’t try to make one model do everything. It’s not a Swiss Army knife. It’s a scalpel. Use it like one.
Rocky Wyatt
March 17, 2026 AT 10:53You think alignment is the problem? Nah. It’s the people. The ones who think they can slap a dataset together on a Friday afternoon and ship it Monday. The ones who ignore bias because ‘it’s just a prototype.’ The ones who say ‘it works on my machine’ like it’s 2003. I’ve seen models fail because someone used a caption like ‘concerning lesion’ instead of describing asymmetry. And then they wonder why the model doesn’t generalize. It’s not the loss function. It’s the laziness. It’s the arrogance. It’s the belief that AI is just code and not a mirror of human bias, error, and poor judgment. You want better models? Hire better data annotators. Pay them more. Train them. Treat them like engineers. Not temp workers.
Santhosh Santhosh
March 19, 2026 AT 08:29I’ve been working on this problem for over five years now, across three different institutions, and I can tell you that every single breakthrough came not from a new architecture or a fancy loss function, but from one simple thing: listening to the clinicians. We had this model that was performing at 82% accuracy, and we thought we were done. Then we sat with a dermatologist for three days while she reviewed 200 false positives. She said, ‘It keeps thinking this one is benign because the border looks smooth-but look at the center. There’s a subtle blue-gray hue that’s barely visible unless you zoom in 400%. That’s the clue.’ We went back, annotated 1200 new images with that exact phrasing, and suddenly, the model started catching those cases. The alignment wasn’t broken. We just weren’t speaking the same language. The model didn’t need more data. It needed more context. And that context doesn’t come from a spreadsheet. It comes from a conversation.
Veera Mavalwala
March 20, 2026 AT 16:08Alignment? Pfft. That’s just code for ‘you didn’t do your homework.’ You think this is hard? Try training a model on a dataset where half the images are blurry, the captions are written by interns, and the metadata says ‘malignant’ when the biopsy says ‘benign.’ I’ve seen it. I’ve wept. I’ve screamed into a pillow. And then I got mad. So I built a pipeline that auto-detects mismatched pairs using a secondary classifier-like a fact-checker for your training data. It’s not perfect, but it catches 63% of the garbage before it ever touches the model. And guess what? Your contrastive loss stops spiking. Your F1 score climbs. Your boss stops asking why the model is hallucinating ‘melanoma’ on a tattoo. You don’t need a cluster. You need discipline. You need to care. And if you don’t? Then yeah, go ahead and fine-tune on synthetic data. Watch your model turn into a racist, myopic, text-obsessed ghost. But don’t come crying when it kills someone. Because you didn’t just build a bad model. You built a weapon.