Large language models (LLMs) are powerful, but they’re stuck in the past. No matter how smart they seem, their knowledge freezes at the date their training data ended. That’s fine for general chat, but when you’re using them in real business apps-like customer support, legal research, or financial analysis-out-of-date answers aren’t just annoying. They’re dangerous. That’s where RAG systems come in. By pulling in live documents during each response, RAG lets LLMs speak with current facts. But here’s the catch: if the documents they pull from are stale, the whole system breaks. Keeping those documents fresh isn’t optional. It’s the difference between a reliable tool and a confidently wrong one.
How RAG Works (And Why It Breaks)
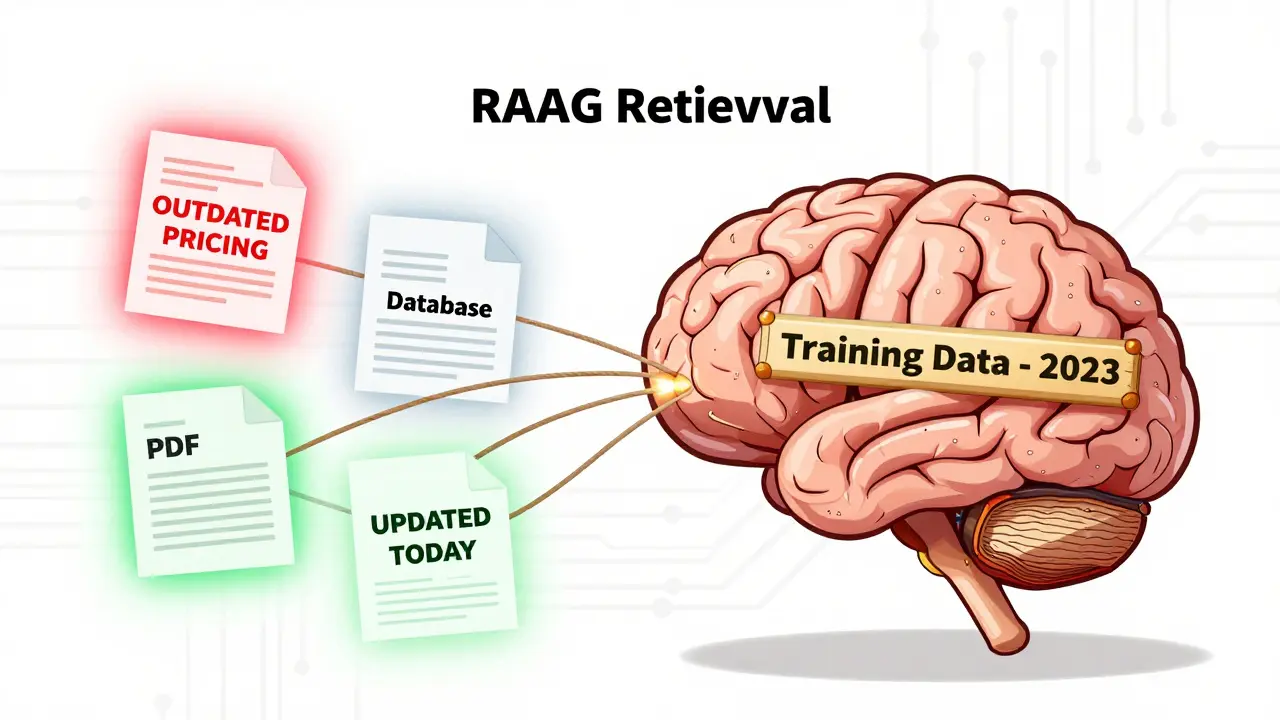
RAG stands for Retrieval-Augmented Generation. At its core, it’s a two-step process. First, when a user asks a question, the system searches through a collection of documents-like PDFs, database records, or internal wikis-to find the most relevant snippets. Then, it feeds those snippets to the LLM, which uses them as context to build an answer. The magic? The LLM doesn’t rely on its own memory. It answers based on what it just read.But this only works if the documents are accurate and current. Imagine asking a RAG system for your company’s latest pricing policy. If the index still has last year’s brochure, the LLM will confidently quote outdated rates. The user won’t know the answer is wrong. The system doesn’t say, “I’m not sure.” It says, “The current rate is $49/month.” And that’s a problem.
The root issue? RAG systems are built on indexes. These indexes are made by taking documents, splitting them into chunks, turning each chunk into a vector (a numerical representation), and storing them in a vector database. Once built, the index doesn’t change unless you tell it to. If a document gets updated, deleted, or added in your source system-say, a SharePoint folder or a PostgreSQL table-the index stays frozen. That’s why document freshness isn’t a nice-to-have. It’s the foundation.
The Three Ways to Keep RAG Updated
There are three main strategies for keeping your RAG index in sync with live data. Each has trade-offs in cost, complexity, and reliability.
Full Re-indexing: The Simple But Heavy Approach
This is the easiest method. Every night-or every week-you wipe out the entire vector index and rebuild it from scratch. You fetch every document, re-chunk them, re-embed them, and reload everything. It’s brute force, but it works.
Pros: Guaranteed consistency. If a document was deleted in your source, it’s gone from the index. No surprises. Simple to implement. Good for small datasets under 10,000 documents.
Cons: Slow. If you have 500,000 documents, re-embedding them all takes hours. During that time, users get outdated answers. Expensive. You’re using compute power for everything, even the 98% of documents that didn’t change. Not scalable.
Companies with small, static knowledge bases-like a startup with a 20-page internal handbook-can get away with this. But as your data grows, this becomes a bottleneck.
Incremental Updates: The Smart Way
This is where things get interesting. Instead of rebuilding everything, you only update what changed. You need to know: which documents were added? Which were modified? Which were deleted?
To do this, you need change detection. One way is polling: check your source system every hour for documents modified after the last update time. Another is Change Data Capture (CDC)-a database-level feature that sends out a signal whenever a row changes. For example, if your product catalog lives in a SQL table with a last_updated timestamp, you can query for anything changed since 2:00 AM.
When a change is found:
- New documents: Embed them and add them to the index.
- Updated documents: Re-embed them and use the vector store’s upsert function to replace the old version. This works if each document has a unique ID-like a database primary key or a UUID.
- Deleted documents: Use the same unique ID to remove them from the index. If you don’t track deletions, stale docs linger forever.
Pros: Fast. Efficient. Minimal downtime. Updates can happen hourly or even in real time. Scales to millions of documents.
Cons: Requires robust change detection. If your source system doesn’t support timestamps or webhooks, polling can miss changes. If you don’t track deletions, your index gets bloated with ghosts. Complex to debug.
Many production RAG systems use this. It’s the sweet spot between accuracy and performance.
Hybrid Approach: The Real-World Standard
Most teams that get RAG right don’t pick one method. They combine them.
Here’s how it works: run incremental updates every hour to catch the majority of changes. Then, once a week, do a full re-index to clean up drift. Why? Because incremental updates aren’t perfect. A bug in your change detector? A failed embed? A corrupted chunk? Over time, small errors pile up. The index slowly drifts from the source.
A weekly full re-index resets everything. It removes orphaned vectors, fixes embedding mismatches, and ensures perfect alignment. It’s like defragmenting a hard drive-but for knowledge.
This hybrid model is what you’ll see in companies like Salesforce, Microsoft, and startups using RAG at scale. It balances cost, speed, and reliability.

What You Must Track: Document Identity and Metadata
You can’t update what you can’t identify. Every document or chunk in your RAG index needs a unique, stable identifier. Avoid using content hashes. If a document changes, its hash changes too-and now you can’t tell if it’s the same doc with updates or a new one.
Instead, use:
- Database primary keys
- Unique URLs (like
https://internal.company.com/docs/policy-v3) - UUIDs generated at ingestion time
And don’t just store the ID. Store metadata too:
source_document_id: The original ID from your systemlast_modified_timestamp: When the source file was last changedversion_number: If your documents have versioning (like Confluence or Google Docs)
Why? Because when a user says, “This answer seems wrong,” you need to trace it back. Was this chunk from an old version? Did the source file change yesterday? Metadata turns debugging from guesswork into a traceable log.
How to Know If Your RAG Is Out of Sync
You won’t always know when your system is giving bad answers. That’s the danger. But here are three signs:
- Users report contradictions: “Last week, it said X. Now it says Y.”
- Retrieval quality drops: Fewer relevant documents show up in search results. Use Mean Average Precision (MAP) to track this over time.
- Metadata mismatch: You see chunks with
last_modified_timestampfrom 6 months ago, but the source file was updated yesterday.
Set up alerts. If a document’s last update is older than 7 days, flag it. If more than 5% of retrieved chunks have timestamps older than your last full re-index, trigger a diagnostic run.
Real-World Example: A SaaS Support Bot
Imagine a company uses RAG to power its customer support chatbot. Its knowledge base has 200,000 help articles. New articles are added daily. Old ones get rewritten weekly. Bugs are patched hourly.
They tried full re-indexing every night. It took 4 hours. During that time, the bot gave outdated answers. Customers complained.
Then they switched to hybrid:
- Every 2 hours: Incremental update. Only re-embed articles with new
last_modifiedtimestamps. - Every Sunday at 2 AM: Full re-index. Clear everything, rebuild from scratch.
Result? 99.8% of changes are reflected within 2 hours. Drift is eliminated weekly. The bot’s accuracy rose 32% in three months. Customer satisfaction scores jumped.
What’s Next: Monitoring, Alerts, and Automation
The future of RAG isn’t just about syncing data. It’s about knowing when it’s broken.
Build monitoring into your pipeline:
- Track the age of your top 10 most-retrieved documents.
- Compare the timestamp of retrieved chunks against the source system’s latest version.
- Log every update-what changed, when, and whether it succeeded.
- Alert engineers if the index is more than 12 hours out of sync.
Some teams even auto-trigger a full re-index if drift exceeds a threshold. It’s not perfect, but it’s better than waiting for a customer to call.
Document freshness isn’t a feature. It’s a requirement. And if you’re building RAG systems, you’re not just an AI engineer-you’re a data custodian. Your job isn’t to make the LLM smarter. It’s to make sure it never lies.
Why can’t I just retrain the LLM instead of updating the RAG index?
Retraining an LLM is expensive, slow, and overkill. It requires massive compute, weeks of time, and a full dataset reprocessing pipeline. RAG solves the same problem by updating just the documents-often in minutes. You keep the same model, but give it fresh context. It’s like upgrading your library instead of rewriting every book.
What happens if a document is deleted but the index doesn’t reflect it?
The deleted document stays in the index as a ghost. The LLM might retrieve it and use it to generate an answer-even though the source is gone. This leads to hallucinated or outdated responses. That’s why tracking deletions is critical. Use unique IDs and explicit delete commands in your vector database to remove them.
Can I use webhooks to trigger RAG updates?
Yes-if your source system supports it. Platforms like Notion, Google Drive, or PostgreSQL with logical replication can send webhooks when files change. This gives you near real-time updates. If your system doesn’t support webhooks, use polling every 15-60 minutes as a fallback.
How often should I do a full re-index?
Monthly is common for large systems. Weekly is better if you have high data churn. For small systems (under 10K docs), daily might be fine. The goal is to catch drift before it impacts users. If your incremental updates are working well, you can stretch it to monthly. If you’ve had issues with stale answers, do it weekly.
Do I need to re-embed every chunk of an updated document?
Yes. Even a small edit changes the meaning of the text, and that changes the vector. Embeddings are sensitive to wording. If you update a sentence, re-embed the entire chunk it’s in. Don’t try to patch partial vectors-that leads to inconsistency. Treat each chunk as atomic.
Is there a tool that automatically handles RAG sync?
Not fully. Tools like LangChain, LlamaIndex, and Weaviate help you build the pipeline, but they don’t automate change detection or deletion tracking. You still need to write logic for polling, CDC, and metadata management. The tools give you the bricks-you still have to build the house.
Ray Htoo
March 5, 2026 AT 22:45Man, this post nails it. I’ve seen so many teams skip document freshness because ‘it works fine for now’-until a customer gets billed the wrong amount because the system quoted a price from 2022. The hybrid approach? Absolute gold. We switched from nightly full re-indexes to hourly increments + weekly resets, and our support bot’s accuracy jumped like crazy. No more ‘I thought the policy changed’ tickets.
Also, metadata is everything. We started storing source_document_id and last_modified_timestamp like it was gospel, and suddenly debugging became a 10-minute hunt instead of a 3-day witch hunt. Don’t skip the metadata.
And yeah, re-embedding the whole chunk? Non-negotiable. I’ve seen people try to ‘patch’ vectors after a tiny edit. It’s like repainting one brick of a wall and expecting the whole thing to match. Doesn’t work. Embeddings are fragile.
Also, if your system doesn’t support webhooks, just poll every 15 minutes. It’s ugly, but better than ghosts haunting your responses.
Natasha Madison
March 6, 2026 AT 19:14This is all corporate propaganda. You think your ‘RAG system’ is keeping things fresh? Nah. They’re just feeding you curated lies. Who controls the documents? Who decides what gets indexed? What if the ‘updated’ document was altered to hide something? You’re not getting truth-you’re getting whatever the admins want you to believe. The ‘hybrid model’? That’s just a way to make you think you’re safe while they quietly purge inconvenient data. Wake up.
And don’t even get me started on UUIDs. That’s just another way to track you. Every ID you store? It’s a fingerprint. They’re building a dossier on every user. This isn’t innovation. It’s surveillance with a fancy name.
Sheila Alston
March 7, 2026 AT 16:22Ugh. Another tech bro pretending he’s a data steward. Let me guess-you think you’re some kind of ethical guardian because you ‘track metadata’? Newsflash: you’re not saving anyone. You’re just making your company’s AI sound more authoritative so they can keep charging clients for ‘cutting-edge solutions’ while the real work-actual human oversight-is outsourced to interns who don’t even know what a vector database is.
And ‘document freshness’? Please. If your customers are relying on your AI to give them legal or financial advice, you’ve already failed. No AI should be making decisions that affect people’s lives. But hey, if you want to automate liability, go ahead. I’ll be over here, watching your company get sued next year.
Also, ‘customer satisfaction scores jumped’? That’s because they stopped calling. Nobody wants to complain when the bot just nods and says, ‘According to our records…’
sampa Karjee
March 9, 2026 AT 07:38How quaint. You speak of ‘incremental updates’ and ‘hybrid models’ as if this is engineering brilliance. In reality, this is just glorified sysadmin work dressed up in LLM jargon. Real AI would not require such brittle, fragile, and labor-intensive maintenance. The fact that you need to re-embed every chunk, track UUIDs, and schedule weekly re-indexes proves one thing: you’re not building intelligence-you’re building a Rube Goldberg machine out of PostgreSQL, Weaviate, and wishful thinking.
And you call this ‘data custody’? No. You’re a librarian with a Python script. True AI doesn’t need a document index. It learns. It adapts. It doesn’t need your 200,000 help articles to function. You’re clinging to the past because you lack the courage-or the compute-to train a model that can generalize.
Stop pretending you’re a pioneer. You’re a patchwork mechanic.
Patrick Sieber
March 9, 2026 AT 22:14Spot on. The hybrid approach is the only sane way to go. We run incremental updates every hour, full re-index every Sunday, and we’ve got alerts set up if any of the top 10 retrieved docs are older than 48 hours. It’s not sexy, but it works.
Also, the metadata point? Critical. We lost a week of debugging because someone used a content hash as the ID. Changed one word in a policy doc? Boom-new ID, ghost chunk, duplicate vector. Took forever to trace. Now we use UUIDs + source_id + timestamp. Clean. Traceable. No drama.
And yes, re-embed the whole chunk. Always. No shortcuts. I’ve seen teams try to ‘update’ vectors by interpolating changes. It’s a nightmare. Embeddings aren’t linear. A single word flip can flip the whole vector direction. Treat each chunk like a single atom. No partial updates.
Kieran Danagher
March 11, 2026 AT 11:43So you’re telling me the future of AI is… a cron job? And we’re all just sysadmins now? Congrats, you turned LLMs into glorified Google Docs bots.
‘Weekly re-index’? That’s not innovation. That’s a band-aid on a leaking dam. The real problem? We’re using LLMs as truth engines when they’re probabilistic parrots. No amount of document hygiene fixes that. You’re not fixing the model-you’re just feeding it better snacks.
But hey, if your CEO wants a shiny dashboard that says ‘99.8% accuracy,’ go ahead. Just don’t blame me when the bot tells a customer their mortgage rate dropped to 0.5% because last week’s doc said ‘historically low rates.’
At least admit it: this isn’t AI. It’s a very expensive autocomplete with a side of sysadmin hell.