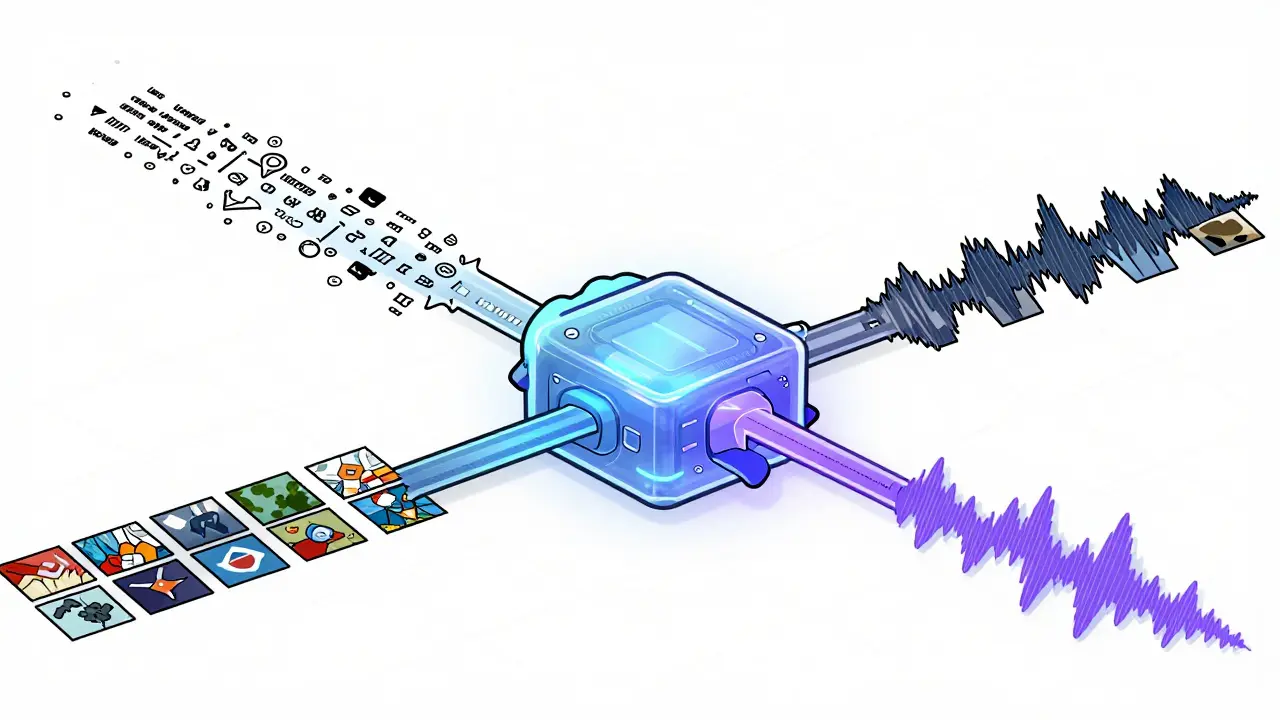
Real-world data is messy. It’s incomplete, biased, expensive to collect, and often impossible to share due to privacy laws like GDPR or HIPAA. For years, data scientists have worked around these limitations by cleaning datasets manually or using simple statistical imputation. But as machine learning models grow more complex-especially those requiring text, images, audio, and sensor data simultaneously-the old tricks stop working. You can’t just fill in missing values when you need a video of a car crash that matches the audio of screeching tires and the telemetry data from the vehicle’s sensors.
This is where Synthetic Data Generation meets Multimodal Generative AI. Instead of scraping the web or conducting costly clinical trials, companies are now generating artificial datasets that mimic reality across multiple formats. This approach doesn’t just fill gaps; it creates entirely new training scenarios that never existed, allowing AI systems to learn faster, safer, and more privately. By June 2026, this technology has moved from experimental research labs into production environments for healthcare, autonomous driving, and enterprise software.
What Is Multimodal Synthetic Data?
To understand why this matters, we first need to define what we mean by "multimodal." In traditional AI, a model might process only text (like a chatbot) or only images (like a photo classifier). Multimodal AI is a system that processes and generates information from multiple types of inputs, such as combining visual features with semantic text tokens and spectral audio features. These systems require training data where these different formats are perfectly aligned. For example, a medical AI needs patient notes (text), X-rays (images), and heart rate monitors (time-series data) all linked to the same patient record at the same timestamp.
Synthetic Data is artificially generated information that mimics the statistical properties and patterns of real-world data without containing actual private records. When you combine these two concepts, you get Multimodal Synthetic Data Generation. This process uses generative models to create realistic, synchronized datasets. If you need to train an autonomous vehicle to recognize a pedestrian crossing in rain, you don’t wait for a rainy day. You generate thousands of hours of video, corresponding lidar point clouds, and audio of wet tires-all synthetically created but statistically identical to real-world conditions.
The core value proposition here is threefold: privacy preservation, cost reduction, and overcoming data scarcity. According to a 2023 HIMSS Analytics survey, 67% of large healthcare organizations were using synthetic data, but only 28% had implemented multimodal capabilities due to technical complexity. The gap exists because generating one modality is easy; keeping them consistent is hard.
How Multimodal Generative Models Work
Generating synthetic data isn’t magic; it’s math. The architecture typically follows a three-stage process, as detailed by N-iX in March 2024. First, input processing occurs using modality-specific feature encoders. Text is processed by language models into semantic token embeddings. Images are broken down by computer vision encoders into visual feature maps. Audio is normalized into spectrograms or MFCCs (Mel-frequency cepstral coefficients).
Second, these disparate representations undergo representation fusion. The model maps these different inputs into a shared latent space. This is the critical step where the AI learns how a specific sound correlates with a specific visual event. If the fusion fails, your generated video might show a dog barking, but the audio track plays a cat meowing. That’s called a "mode collapse" or alignment failure.
Third, content generation happens through decoders that reconstruct the final outputs from the shared space. Several architectures dominate this space:
- Generative Adversarial Networks (GANs): Two neural networks compete against each other-one generates data, the other tries to detect if it’s fake. GANs excel at creating sharp, realistic images and audio but can struggle with diversity and stability during training.
- Variational Autoencoders (VAEs): These compress data into a probabilistic latent space and then reconstruct it. VAEs offer better control over the generation process and interpretable latent spaces, making them useful for tweaking specific attributes (e.g., changing the weather in a synthetic scene without altering the car model).
- Diffusion Models: Currently the state-of-the-art for high-quality image and audio generation. They work by adding noise to data and then learning to reverse the process. Diffusion models provide excellent diversity and controllability, which is why they power tools like Stable Diffusion and NVIDIA’s recent enterprise releases.
- Neural Ordinary Differential Equations (NODEs): Specifically designed for time-series data. Unlike standard models that look at discrete time steps, NODEs model continuous-time trajectories. This is crucial for healthcare, where patient vitals change smoothly between irregular check-ups.
Key Architectures: From GANs to MultiNODEs
While general-purpose models like GPT-4 or Midjourney are famous, specialized architectures drive industrial synthetic data generation. One standout example is MultiNODEs, which is a hybrid modeling framework published in July 2022 that combines Neural Ordinary Differential Equations with variational autoencoders to handle mixed static and time-dependent variables. Developed for clinical applications, MultiNODEs addresses a major pain point in healthcare data: missing values and irregular assessment intervals. Real patient data is rarely clean. A patient might miss a blood test, or their heart rate monitor might drop offline. MultiNODEs learns the underlying continuous trajectory of the patient’s health, allowing it to estimate variable states at any arbitrary timepoint. This enables smooth interpolation and extrapolation beyond the training data span.
In contrast, traditional approaches like Variational Autoencoders for Mixed Bayesian Networks (VAMBN) struggle with these temporal dependencies. MultiNODEs maintains real data signals, such as variable interdependencies, while generating highly realistic synthetic patient trajectories. A 2023 pilot study by the Mayo Clinic used MultiNODEs for heart failure prediction, achieving 92% accuracy matching real-data performance while completely eliminating patient privacy concerns.
For non-temporal data, diffusion models have taken the lead. NVIDIA’s announcement of "Generative AI Enterprise" in March 2024 highlighted its ability to generate physically accurate synthetic data at scale for physical AI applications. This includes simulating lighting, shadows, and material textures for robot training. The key difference here is fidelity: robots need to understand physics, not just pixels. Therefore, the synthetic data must adhere to physical laws, which requires integrating simulation engines like NVIDIA Omniverse Replicator with generative AI models.

Why Multimodal Beats Single-Modality Approaches
You might wonder why we can’t just generate text, images, and audio separately and stitch them together. The answer lies in cross-modal understanding. As noted by Digital Divided Data in August 2023, siloed datasets fail in scenarios requiring integrated context. Imagine training a customer service bot. If you generate text transcripts separately from voice recordings, the bot won’t learn that a raised pitch in audio often correlates with frustration in text sentiment.
Multimodal synthetic data provides complementary information integration. According to N-iX, this leads to improved accuracy and greater adaptability. Here is a comparison of single-modality versus multimodal synthetic data generation:
| Feature | Single-Modality (e.g., Image-only GAN) | Multimodal (e.g., MultiNODEs/Diffusion) |
|---|---|---|
| Data Types Handled | One format (text OR image OR audio) | Multiple synchronized formats (text + image + time-series) |
| Alignment Accuracy | N/A (no cross-referencing needed) | Critical; requires precise temporal and semantic sync |
| Use Case Example | Generating stock photos for marketing | Training self-driving cars with video, lidar, and engine telemetry |
| Computational Cost | Moderate | High (requires >24GB VRAM per node) |
| Bias Risk | Confined to one domain | Can amplify biases across multiple dimensions if not validated |
The trade-off is complexity. Integrating diverse data sources requires teams with expertise in multiple AI domains. Preprocessing alone is a hurdle: text must be tokenized, vision data resized into feature maps, and audio normalized. If any step is misaligned, the entire synthetic dataset becomes useless for training robust models.
Implementation Challenges and Hardware Requirements
Don’t underestimate the resources needed. Generating high-fidelity multimodal data is computationally expensive. NVIDIA recommends at least 24GB of VRAM for high-fidelity generation at scale. Most enterprise implementations use distributed systems across multiple GPUs and nodes. RunPod’s October 2023 guide emphasizes implementing quality assessment filters during generation to automatically discard low-quality samples, maintaining dataset standards.
Beyond hardware, there are significant ethical and technical risks. Dr. Rumman Chowdhury, Responsible AI Lead at Twitter, cautioned in June 2023 that synthetic multimodal data risks amplifying biases present in training data across multiple dimensions. If your base model was trained on biased historical hiring data, the synthetic resumes it generates will perpetuate that bias, potentially making it harder to detect because the data looks "clean" and statistically perfect.
Another challenge is the "representation gap." Synthetic data is great for common scenarios but often fails to capture rare, edge-case events unless explicitly programmed to do so. A hospital system reported on Reddit in March 2023 that while MultiNODEs reduced data collection costs by 60%, it took three months of fine-tuning to properly model rare disease trajectories. Without careful validation, models may perform well on synthetic data but fail in the real world.
Market Trends and Regulatory Landscape
The market for synthetic data is exploding. Valued at $310 million in 2022, it is projected to reach $1.2 billion by 2027, growing at a CAGR of 31.2% according to MarketsandMarkets. Healthcare leads adoption at 32% of enterprise use cases, followed by automotive (24%) and retail (18%).
Regulators are catching up. The FDA’s September 2023 draft guidance on AI in Software as a Medical Device specifically acknowledged synthetic data as acceptable for validation purposes, provided it is "properly characterized and validated." This is a game-changer for med-tech companies who previously struggled to share patient data across institutions. However, Forrester warns in Q2 2024 that overreliance on synthetic data without proper validation frameworks could lead to systemic model failures. The key is treating synthetic data as a supplement, not a replacement, for real-world testing in critical applications.
Best Practices for Getting Started
If you’re looking to augment your datasets with multimodal synthetic data, start small. Don’t try to rebuild your entire training pipeline overnight. Follow these steps:
- Identify the Bottleneck: Are you lacking rare examples? Privacy compliance? Or multi-format alignment? Start with the problem that hurts most.
- Choose the Right Architecture: For time-series clinical data, look into MultiNODEs or similar ODE-based models. For visual-physical simulations, explore NVIDIA Omniverse. For general content, diffusion models are the standard.
- Validate Rigorously: Use downstream performance testing. Train a model on synthetic data and test it on a small holdout set of real data. If the performance drops significantly, your synthetic data lacks fidelity.
- Implement Quality Filters: Automate the rejection of low-quality samples. As RunPod suggests, maintain high standards by filtering during generation.
- Monitor for Bias: Regularly audit your synthetic datasets for demographic and contextual biases. Use tools like IBM’s AI Fairness 360 or Google’s What-If Tool.
Businesses can begin experimenting with accessible models like DALL-E or Stable Diffusion for visual content, combined with LLMs like GPT-4 for text, before moving to custom-trained multimodal generators. The goal is to build a feedback loop where synthetic data improves model performance, which in turn helps generate better synthetic data.
What is the difference between synthetic data and augmented data?
Data augmentation typically involves applying simple transformations to existing data, such as rotating an image or flipping audio. Synthetic data generation creates entirely new data points from scratch using generative models. While augmentation increases volume slightly, synthetic generation can create infinite variations and entirely new scenarios that did not exist in the original dataset.
Is synthetic data legally compliant with GDPR and HIPAA?
Yes, properly generated synthetic data does not contain personal identifiable information (PII) and is generally considered anonymous. However, compliance depends on the generation method. If the model memorizes real records (overfitting), it could potentially reconstruct private data. Best practices include using differential privacy techniques and rigorous validation to ensure no real individual can be re-identified from the synthetic output.
Which industries benefit most from multimodal synthetic data?
Healthcare benefits from generating patient trajectories and medical imaging without privacy risks. Automotive and robotics use it for training autonomous systems in dangerous or rare scenarios (e.g., accidents, extreme weather). Finance uses it for fraud detection with balanced datasets, and retail uses it for virtual try-ons and inventory simulation.
How much computing power is needed to generate multimodal synthetic data?
Requirements vary by fidelity. Basic text-image pairing can run on consumer GPUs. However, high-fidelity multimodal generation involving video, lidar, and continuous time-series data requires enterprise-grade hardware. NVIDIA recommends at least 24GB VRAM per GPU, and large-scale projects often utilize distributed clusters with multiple A100 or H100 GPUs to handle the computational load of diffusion models or NODEs.
Can synthetic data replace real-world testing?
No, it should complement, not replace, real-world testing. Synthetic data is excellent for initial training, scaling up dataset size, and testing edge cases. However, due to the "representation gap," models trained solely on synthetic data may fail to generalize to unpredictable real-world nuances. Always validate synthetic-trained models against a curated set of real-world data before deployment.
Lisa Puster
June 27, 2026 AT 04:06another day another tech bro trying to sell us on the idea that computers can replace human intuition. you think generating fake data is going to solve the fact that your models are biased by design? its just laundering bad data with a fancy math coat of paint. nobody cares about your 'multimodal' buzzwords when the underlying logic is still garbage
Joe Walters
June 27, 2026 AT 18:22lol u guys really think this stuff works in production? i tried running a simple diffusion model on my rig and it crashed after 2 hours. the article says 24GB VRAM is needed but honestly thats a lie for anything complex. also why does everyone pretend these architectures are stable? they are not. multiNODEs sounds like a made up name from a sci fi movie. typical corporate hype cycle nonsense
Robert Barakat
June 28, 2026 AT 23:47the essence of synthetic data is not merely replication but the philosophical act of creation through absence. we generate what is not there to understand what is. it is a mirror held up to reality that reflects only the shadows we choose to illuminate. the alignment of modalities is akin to the harmony of spheres in ancient cosmology. if the audio does not match the visual the universe of the model collapses into chaos. we are building gods out of noise
Michael Richards
June 29, 2026 AT 08:53listen up because i am only going to say this once. if you are not using differential privacy techniques you are doing it wrong. most people here are playing around with toys while enterprise teams are dealing with actual compliance nightmares. the FDA guidance mentioned in the post is critical. you cannot just dump synthetic data into a medical pipeline without rigorous validation. stop treating this like a hobby project and start treating it like engineering. bias amplification is real and it will destroy your product
Laura Davis
June 30, 2026 AT 13:36i feel like we need to talk about the ethical implications more openly. yes the tech is cool but who is responsible when the synthetic data fails in a real world scenario? like if a self driving car misses a pedestrian because the rain simulation was off? we need boundaries. i support innovation but we have to protect vulnerable groups from algorithmic harm. lets keep the conversation respectful and focused on safety please
Lisa Nally
July 2, 2026 AT 10:51actually the distinction between VAEs and GANs is quite nuanced and often misunderstood by laypeople. VAEs provide a probabilistic latent space which allows for much finer grained control over attribute manipulation whereas GANs suffer from mode collapse issues that make them less suitable for high fidelity multimodal tasks requiring strict temporal consistency. furthermore the integration of NODEs for time series data is not just an add on but a fundamental architectural shift required for handling irregular sampling rates in clinical datasets. one must appreciate the mathematical elegance of continuous time trajectories
Edward Gilbreath
July 4, 2026 AT 04:16they want you to believe synthetic data is safe but its just a way to hide the fact that they are stealing your biometric data. the government loves this stuff because it creates a parallel reality where they can test surveillance algorithms without your consent. dont fall for the marketing. its all a conspiracy to erode privacy under the guise of innovation. wake up sheeple
kimberly de Bruin
July 5, 2026 AT 18:07silence is golden but data is silver and synthetic gold is just lead painted to look valuable. we chase perfection in numbers but forget the messy beauty of truth. the machine dreams in binary but we live in analog. perhaps the error is the point