Imagine asking your database a question in plain English-like "Show me last quarter’s sales by region, but only for customers who bought more than five items"-and getting back the exact data you need, no SQL needed. That’s not science fiction. It’s Natural Language to Schema (NL2Schema), and it’s already reshaping how businesses interact with data.
For years, getting data out of databases meant writing SQL queries. That put the power in the hands of data engineers and analysts. Everyone else? They waited. But now, with large language models (LLMs) that understand context, relationships, and even subtle intent, you can skip the syntax entirely. You just ask. The system figures out the structure. And it works-when it’s done right.
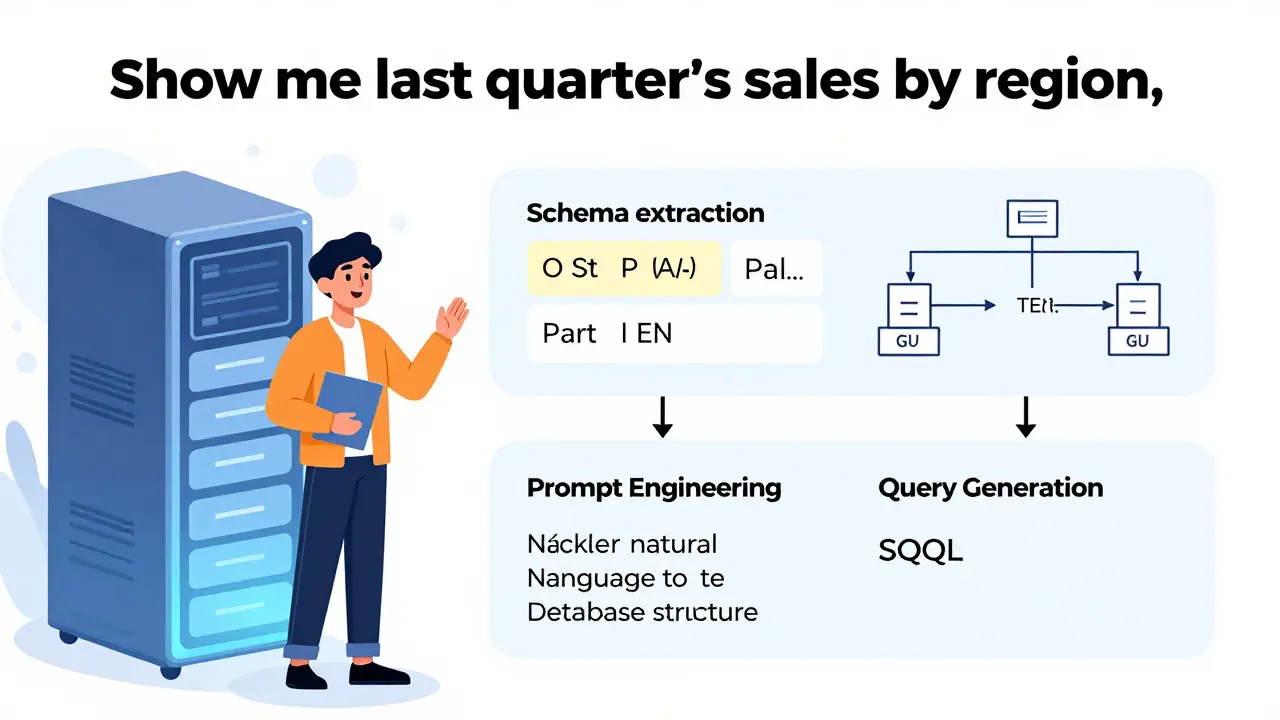
How NL2Schema Actually Works
It’s not magic. It’s architecture. At its core, NL2Schema breaks down into three steps:
- Schema extraction-the system reads your database structure: table names, column types, primary keys, foreign keys, and relationships.
- Prompt engineering-your natural language question is paired with that schema, so the LLM knows what it’s working with.
- Query generation-the model builds an SQL query, validates it, and runs it.
Without step one, you’re just guessing. If the system doesn’t know that CustomerID links to Orders, it won’t join the tables. If it doesn’t know OrderDate is a timestamp, it might treat it as text. That’s why most failed implementations blame the model-when the real problem is bad schema awareness.
Enterprise systems like Oracle Database 23c, Microsoft SQL Server 2022, and PostgreSQL 15 all support this now. But not every tool handles it equally. According to Oracle’s 2024 benchmarks, systems that actively pull schema data from metadata catalogs in real time (called retrieval-augmented generation, or RAG) reduce errors by over 30%. Simple systems just paste the schema into the prompt-and that’s where things fall apart.
Why ER Diagrams Matter More Than You Think
Most people think of databases as tables and columns. But the real power lies in the relationships. That’s where ER diagrams come in. An Entity-Relationship diagram shows how tables connect: one-to-many, many-to-many, optional links, inheritance, constraints.
Here’s the catch: LLMs don’t understand ER diagrams like a human does. They see text. So if you say "Find all orders with returns", the model needs to know:
- Which table holds orders?
- Which table holds returns?
- Is there a foreign key linking them?
- Is the relationship one-to-one or one-to-many?
Without that, you get wrong joins, missing data, or phantom results. Microsoft’s own GitHub examples show their system fails to interpret many-to-many relationships in 41.6% of test cases. That’s not a small error-it’s a data integrity risk.
That’s why new tools are starting to generate ER diagrams from natural language. In September 2024, Microsoft released a feature that turns your description-"Customers place orders, each order has one or more items"-into a visual diagram with 76.4% accuracy. Oracle’s upcoming Schema Intelligence Engine does the reverse: it takes your ER diagram and turns it into a natural language description so the model can learn it.
This two-way translation is the next frontier. If you can describe your schema in plain English, and the system can turn that into a working database structure-or vice versa-you’re no longer coding. You’re designing.
What Works Best-And What Doesn’t
Not all natural language queries are created equal. Here’s what most systems handle well:
- Simple data retrieval: "Show me all products from supplier X" → 94.2% accuracy
- Filtering: "Sales over $1,000 in January" → 89.7% accuracy
- Single-table aggregations: "Average order value last quarter" → 87.3% accuracy
But try anything complex, and accuracy drops fast:
- Window functions: "Rank customers by total spend, then show top 10%" → 52.4% accuracy
- Recursive queries: "Show all subordinates in the org chart down to level 5" → 43.1% accuracy
- Multi-database transactions: "Compare inventory from warehouse A with sales from region B" → 38.9% accuracy
Why? Because these require deep understanding of logic, not just vocabulary. A model might know what "rank" means, but not how to apply it across sorted partitions. Or it might miss that "warehouse A" and "region B" live in different systems entirely.
And then there’s ambiguity. AWS found that 37.8% of user queries are unclear. "Show me last month’s data"-last month’s what? Sales? Users? Returns? Without context, the system guesses. And guesses are dangerous.
Real-World Use Cases and Pitfalls
Companies that got this right saw dramatic changes.
A healthcare provider in Ohio implemented Microsoft’s solution with custom schema annotations. Clinical analysts-who had never written SQL-started pulling patient trends, medication usage, and readmission rates on their own. Query time dropped 65%. No more waiting for IT.
A Fortune 500 retailer used AWS’s NL2SQL tool to let store managers check inventory levels. But they hit a wall. Their schema had 400+ tables. The model kept mixing up product codes and warehouse IDs. It took three months of manual tuning, adding business rules like "ProductID starts with P- and links to WarehouseTable via LocationCode", before accuracy hit 73%.
On the flip side, users report consistent complaints:
- "It thinks my date format is text." (Salesforce data engineer)
- "It keeps joining the wrong tables." (Deloitte analyst)
- "I asked for revenue, and it gave me units sold." (Retail manager)
The biggest pitfall? Trusting the output. A December 2024 DBTA survey found 89% of database admins worry about running unvalidated SQL generated by AI. One company had a query that accidentally deleted 12,000 customer records because the model misinterpreted a filter as a delete condition. That’s why every enterprise system now includes SQL validation layers-98.7% of them, according to the Defensive Publications Series.
Cost, Adoption, and What’s Coming Next
The market is exploding. Gartner estimates the NL2Schema market hit $2.3 billion in 2024 and will hit $8.9 billion by 2027. Financial services lead adoption at 62%, followed by healthcare (58%) and retail (54%).
Costs vary wildly:
- Commercial platforms (Oracle, Microsoft, ThoughtSpot): $45,000-$120,000/year
- Open-source (Chat2DB): Free tier, enterprise version at $15,000/year
But the real cost isn’t the license-it’s the setup. AWS says schema preparation takes up 65% of implementation time. You need to document every table, every join, every business rule. One data engineer told me: "I spent 60 hours writing prompts just to teach the system what ‘active customer’ means in our system. It’s not in the schema. It’s in our internal docs."
What’s next? By 2026, Gartner predicts 70% of systems will automatically refine their schema understanding based on user feedback. If you correct a wrong query, the system learns. If you say, "No, I meant the shipping date, not the order date," it adjusts.
And the biggest shift? The role of the data engineer is changing. No longer just writing SQL, they’re now teaching AI. Their new job: curating schema metadata, writing clear business definitions, and building feedback loops. The tools are getting smarter-but the humans are still the ones who know what the data really means.
Getting Started: Three Practical Steps
If you’re considering NL2Schema, don’t jump in blind. Here’s how to start:
- Start small-Pick one table with clear relationships. Not your entire data warehouse. Try customer orders or inventory logs.
- Document everything-Write down what each column means in plain English. What’s a "status"? What’s "region"? Include examples. This becomes your prompt guide.
- Validate every result-Never run an AI-generated query without checking the SQL first. Use a tool that shows you the generated code. Train users to read it.
And remember: this isn’t about replacing SQL. It’s about making it accessible. The goal isn’t to make everyone a data expert. It’s to make data available to everyone who needs it.
Can natural language tools generate ER diagrams from text?
Yes. Microsoft’s Azure OpenAI Service (released September 2024) and Oracle’s upcoming Schema Intelligence Engine can convert natural language descriptions into ER diagrams with 76-82% accuracy. These tools parse phrases like "Each customer can have multiple orders, but each order belongs to only one customer" and build visual relationships. However, they still require human review-especially for complex many-to-many links or conditional constraints.
Do I need to know SQL to use NL2Schema?
No. The whole point is to let non-technical users ask questions in plain language. Business analysts, marketers, and managers can use these tools without ever seeing a SELECT statement. However, understanding basic database concepts-like tables, columns, and relationships-helps you ask better questions and spot errors. It’s not required, but it improves accuracy.
Why do NL2Schema tools fail on complex queries?
Because they rely on pattern matching, not true logic. Complex queries involve nested conditions, window functions, recursive hierarchies, or cross-database joins-all of which require deep relational understanding. Most LLMs max out at 32,000 tokens of context. A schema with 500 tables can use over 200,000 tokens. When the system can’t see the full structure, it guesses. That’s why schema-aware systems using real-time metadata retrieval perform far better than those relying on static prompts.
Are there security risks with AI-generated SQL?
Absolutely. If not filtered, AI can generate malicious queries-like DELETE, DROP, or UNION attacks. That’s why every enterprise implementation includes a validation layer that checks for dangerous keywords, validates table access, and blocks unauthorized operations. According to the Defensive Publications Series (2024), 98.7% of commercial systems now use automated SQL sanitization. Still, human review is recommended for high-risk environments like healthcare or finance.
What’s the difference between NL2SQL and NL2Schema?
NL2SQL focuses on turning natural language into SQL queries. NL2Schema goes further: it includes understanding and using the database structure-tables, columns, keys, relationships-to make those queries accurate. Think of NL2SQL as a translator, and NL2Schema as a translator who also knows the grammar rules of the language. Without schema awareness, NL2SQL tools often generate incorrect or incomplete queries.
sonny dirgantara
March 11, 2026 AT 03:49Lauren Saunders
March 11, 2026 AT 08:10Andrew Nashaat
March 12, 2026 AT 04:47Gina Grub
March 12, 2026 AT 10:35Nathan Jimerson
March 12, 2026 AT 16:37Sandy Pan
March 12, 2026 AT 19:03Eric Etienne
March 14, 2026 AT 05:36Dylan Rodriquez
March 14, 2026 AT 23:37