
Imagine asking an AI to write a story. You type "Once upon a time," and it keeps going until a full tale appears. That simple magic relies on a specific mechanical process called autoregressive generationa method where each new part of the output depends strictly on all previous parts generated in sequence. This isn't random guessing. It is a precise, mathematically driven loop that defines how modern systems like GPT-4, Gemini, and Claude produce text. Understanding this step-by-step token production clarifies why these models are powerful, why they sometimes hallucinate, and where the technology is heading as we move through 2026.
The Core Mechanism of Next-Token Prediction
At its simplest, an autoregressive model works like a predictive text tool on your phone, but far more advanced. When you start typing a message, your keyboard guesses the next word based on what you have already typed. Autoregressive Large Language Models do exactly this, except they predict individual tokensthe basic building blocks of text, which can be whole words, word fragments, or punctuation marks instead of whole phrases. A token might be the word "cat," or the fragment "ness," or even a period ".".
The process begins when you provide a promptthe initial input sequence given to the model to trigger generation. The model reads this sequence and calculates a probability distribution for every possible token in its vocabulary. If the model knows 50,000 different tokens, it assigns a likelihood score to each one for the very next position. For example, if your prompt is "The sky is," the model might assign a high probability to "blue" and a low probability to "banana." It selects the most likely option, adds it to the sequence, and then uses this new, longer sequence to predict the following token.
How the Iterative Loop Works
This looping behavior is the defining characteristic of the architecture. The system does not see the end of the sentence before it starts writing the beginning. Instead, it builds the output one piece at a time, feeding its own creation back into itself for the next step. This recursive cycle creates what experts call a causal chain. To visualize this, consider a scenario where the goal is to complete a cooking recipe step.
- Input: The user provides the phrase "Boil water until it."
- Prediction: The model calculates probabilities. "bubbles" might get 80% chance, "freezes" gets 0.001%, and "sings" gets 5%.
- Selection: The system chooses "bubbles" (argmax or sampled choice).
- Append: The sequence becomes "Boil water until it bubbles.".
- Repeat: This new string is fed back in to predict what comes after "bubbles".
This continues until the model generates a special stop token, often represented as "END" or similar markers, telling the system the thought is finished. Each iteration takes time, which leads us directly into why speed is a major constraint in this design.
The Role of Transformers and Attention Masks
You might wonder how the model knows not to look ahead. If I am writing a book, I know how the plot ends before I write Chapter One. An Transformerthe underlying neural network architecture enabling efficient processing of sequential data through attention mechanisms architecture was originally designed to see everything at once. To make it behave autoregressively, developers introduced a "causal mask." This is a mathematical filter applied during the attention calculation. It effectively blinds the model to any information that hasn't been generated yet.
When calculating the probability for the current token, the attention mechanism checks the hidden states of previous tokens. The mask ensures that for any given position $t$, the attention scores for positions greater than $t$ are set to negative infinity, resulting in zero probability weight. This forces the model to rely solely on history. Without this mask, the model would cheat, looking at the last word while trying to predict the first word, ruining the generative logic required for open-ended creation.
Understanding Limitations and Latency
The step-by-step nature introduces inherent trade-offs. The biggest issue is latency. Because you cannot calculate token five until token four is produced, there is no parallelization possible during inference. You must wait for step one to finish before starting step two. As response lengths grow, the time wall-clock increases linearly. If generating a short answer takes 1 second, a ten-times longer essay might take roughly ten times as long, assuming constant hardware resources.
There is also the problem known as Exposure Biasthe discrepancy between training conditions where the model sees perfect data and inference conditions where it relies on its own imperfect predictions. During training, the model always sees the correct "ground truth" previous tokens provided by humans. But when you ask it to write, it sees only its own previous outputs. If it makes a small error early on-like confusing a subject pronoun-it might struggle to correct that mistake later because the subsequent predictions are conditioned on that initial error. This error propagation is a fundamental weakness of the strict left-to-right design.
Comparison With Alternative Architectures
Not all language models work this way. The primary alternative is Autoencodingan approach used in models like BERT where the task is to understand bidirectional context rather than generate sequentially. Models trained via autoencoding, such as BERT or RoBERTa, look at both left and right context simultaneously. They fill in blanks inside a sentence rather than predicting what follows at the end. While excellent for understanding semantics and searching documents, they struggle to generate coherent long-form text because they lack the iterative forward-building capability of autoregressive designs.
| Feature | Autoregressive | Autoencoding (BERT) | Diffusion Models |
|---|---|---|---|
| Directionality | Left-to-Right Only | Bidirectional | Noise Reduction |
| Primary Goal | Creation / Generation | Understanding / Classification | Drafting / Refinement |
| Error Correction | None (No Backtracking) | N/A (Predicts All at Once) | Iterative Refinement Possible |
| Latency | Sequential (High) | Parallel (Low) | Moderate |
Recently, diffusion-based text models have emerged as a potential third path. Unlike the strict sequential chain of autoregression, diffusion models treat text generation like image generation. They start with noise and iteratively refine the signal. Research from late 2025, including studies by Yang et al., suggests that future systems may combine autoregressive generation for coherence with diffusion-like revision capabilities. This hybrid approach aims to keep the strengths of current LLMs while fixing the exposure bias and lack of global planning.
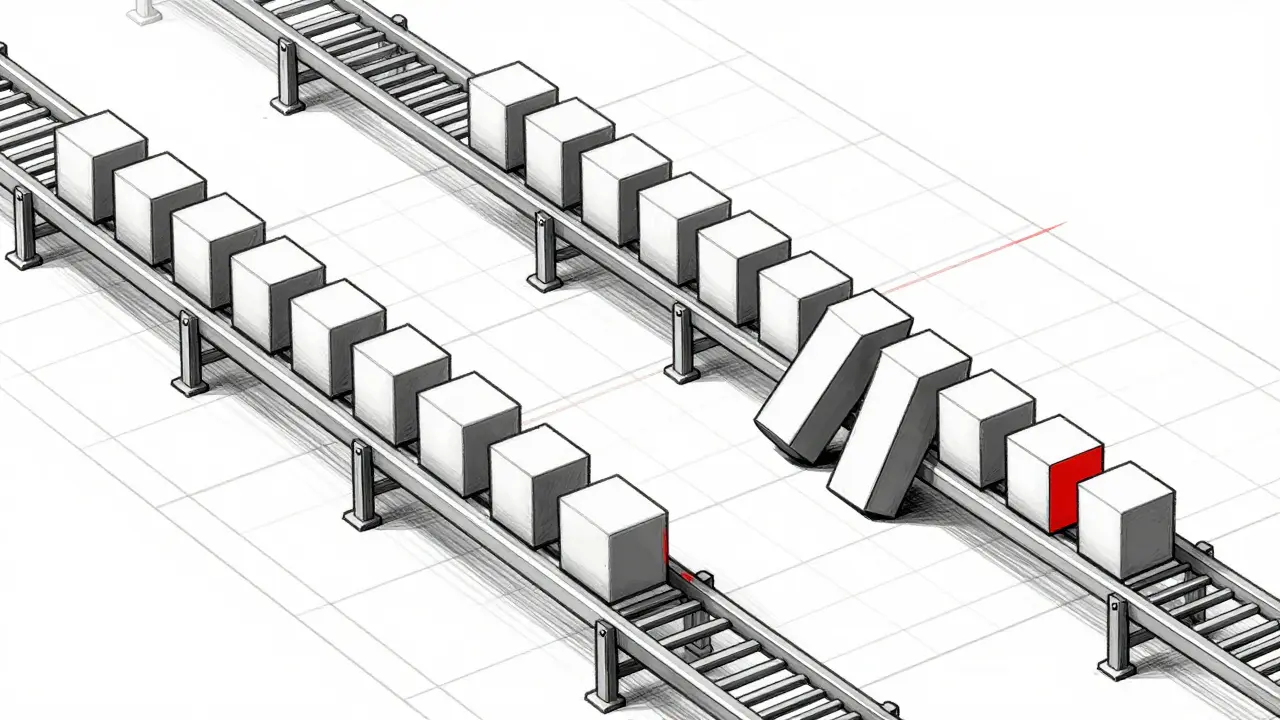
Real-World Implementation in 2026
As of early 2026, the industry standard remains heavily reliant on the autoregressive principle. Almost every commercial assistant, code generator, and translator operates on this foundation. OpenAI's GPT series, Google's Gemini, and Anthropic's Claude all utilize masked self-attention to enforce this causality. Despite theoretical critiques regarding efficiency, the practical ability to maintain long-range dependency without external memory banks has kept this method dominant.
However, researchers are pushing boundaries. There is active exploration into "look-ahead" techniques and draft-correct cycles within the same inference pass. The goal is to reduce the latency penalty without sacrificing the quality of the probabilistic predictions. While the core loop remains the same-token, append, repeat-the internal machinery is becoming smarter about how probabilities are calculated and how context is weighted during those steps.
Conclusion on Mechanism Design
The step-by-step nature of autoregressive generation is a double-edged sword. It allows for incredible depth in reasoning, letting the model "think" through a sentence as it writes. But it locks the system into a linear timeline where mistakes are hard to undo. As we advance into more complex AI tasks requiring structured outputs or verified math, the pressure to evolve beyond pure autoregression grows. Yet, for now, it remains the engine driving the most capable language tools available to us.
What exactly is a token in LLM generation?
A token is the smallest unit of text the model processes, which can be a full word, part of a word, or punctuation. For example, the word "running" might be split into "run" and "ning" depending on the model's vocabulary size.
Why can't LLMs see the future tokens?
They are restricted by a causal mask during training. This prevents the model from learning shortcuts by seeing the answer before predicting it, ensuring it learns to predict the next step based only on history.
Does autoregressive generation allow editing?
No, not during the generation process. Once a token is outputted, the model moves to the next position. It cannot go back to change previous words, which limits its ability to revise drafts internally.
Is exposure bias a major problem?
Yes. It happens because the model trains on perfect data but runs on its own imperfect predictions, leading to potential error accumulation over long sequences.
Are there alternatives to autoregressive models?
Yes, autoencoding models like BERT focus on understanding context, and emerging diffusion models offer iterative refinement similar to image generation rather than strict left-to-right prediction.
Ronnie Kaye
March 27, 2026 AT 08:19I guess this means my phone keyboard was basically training an LLM before I even knew what that meant
The way it predicts words is pretty similar to what those big models do under the hood
It feels like cheating when you get it right three times in a row without thinking
Still glad we aren’t waiting hours for a simple sentence to load anymore
Ian Maggs
March 28, 2026 AT 22:59Your observation regarding predictive typing is, quite frankly, insightful; although one must consider, that there is a vast gulf between, the context of a keypad versus, the neural pathways simulated here
It is, a matter of scale, as well as complexity
We must ponder, the implications of such causality on free will itself
One might wonder if we are merely generating noise with meaning attached retroactively
Perhaps, the universe operates similarly, step by incremental step
The beauty lies in, the sequential unfolding of reality rather than instant omniscience
Michael Gradwell
March 30, 2026 AT 14:50people think tokens are words but they arent always
i learned the hard way when debugging sequence alignment issues
the attention mask logic is critical for preventing lookahead cheats
you cannot fake your way through architecture design
respect the mechanics behind the magic
Emmanuel Sadi
March 30, 2026 AT 18:43You act like you discovered the ocean with all your lecture about tokens
Spare us the engineering ego trip since you clearly missed the main point
Exposure bias is the real headache not some vocabulary table lookup
Your advice sounds like something a junior dev posts on slack after overtime
Flannery Smail
March 31, 2026 AT 20:37This whole discussion ignores the fact that diffusion models are already eating the market share
Sequential processing is just a legacy bottleneck that engineers refuse to abandon
We are wasting compute cycles on left to right generation when parallel options exist
Soon enough the timeline of these papers will look like ancient history
Priyank Panchal
April 1, 2026 AT 23:59Current benchmarks show autoregressive models still outperform diffusion approaches in coherent long-form generation tasks.
Nicholas Carpenter
April 2, 2026 AT 23:00It is really exciting to see how far we have come in just a few years.
We used to struggle with basic text generation tasks that seemed trivial.
Now machines can construct entire narratives without human intervention.
The concept of exposure bias seems scary to new developers though.
They worry about errors compounding over long paragraphs.
But honestly I think the progress in self-correction is promising.
Many researchers are already working on hybrid models right now.
These new systems try to combine speed with accuracy goals.
It shows us that innovation never truly stops in this field.
We should encourage more students to learn about tokenization deeply.
Understanding the math helps everyone appreciate the technology better.
People often fear automation taking away creative jobs eventually.
Yet these tools mostly serve to enhance our own productivity instead.
The future of writing looks quite bright and full of possibilities.
We must remain optimistic while monitoring ethical usage standards too.