Most large language models sound like they were raised in Silicon Valley. They handle English with ease but stumble when you switch to Spanish, Hindi, or Swahili. This isn't just a minor glitch; it's a structural imbalance caused by the massive amount of English data used during pre-training. If you are building an AI product for a global audience, this limitation is a dealbreaker. The solution lies in cross-lingual fine-tuning, a specialized process that adapts these models to new languages without starting from scratch.
In 2026, we have moved past simple translation tricks. Researchers are now using sophisticated methods that mimic how humans learn second languages. This article breaks down exactly how cross-lingual fine-tuning works, the best techniques available today, and how you can apply them to your own models.
Why Simple Translation Isn't Enough
You might think translating instruction data into another language is all you need. It’s not. When you take an English-centric model and feed it translated instructions, the model often retains its "English-first" thinking patterns. It translates the input, processes it as if it were English, and then translates the output back. This creates a disconnect in nuance, tone, and cultural context.
The core problem is semantic alignment. The model needs to understand that concepts map directly between languages, not just through a translation layer. Recent research highlights that instruction tuning on non-English data alone fails to close this gap. You need targeted strategies that force the model to align its internal representations across linguistic boundaries.
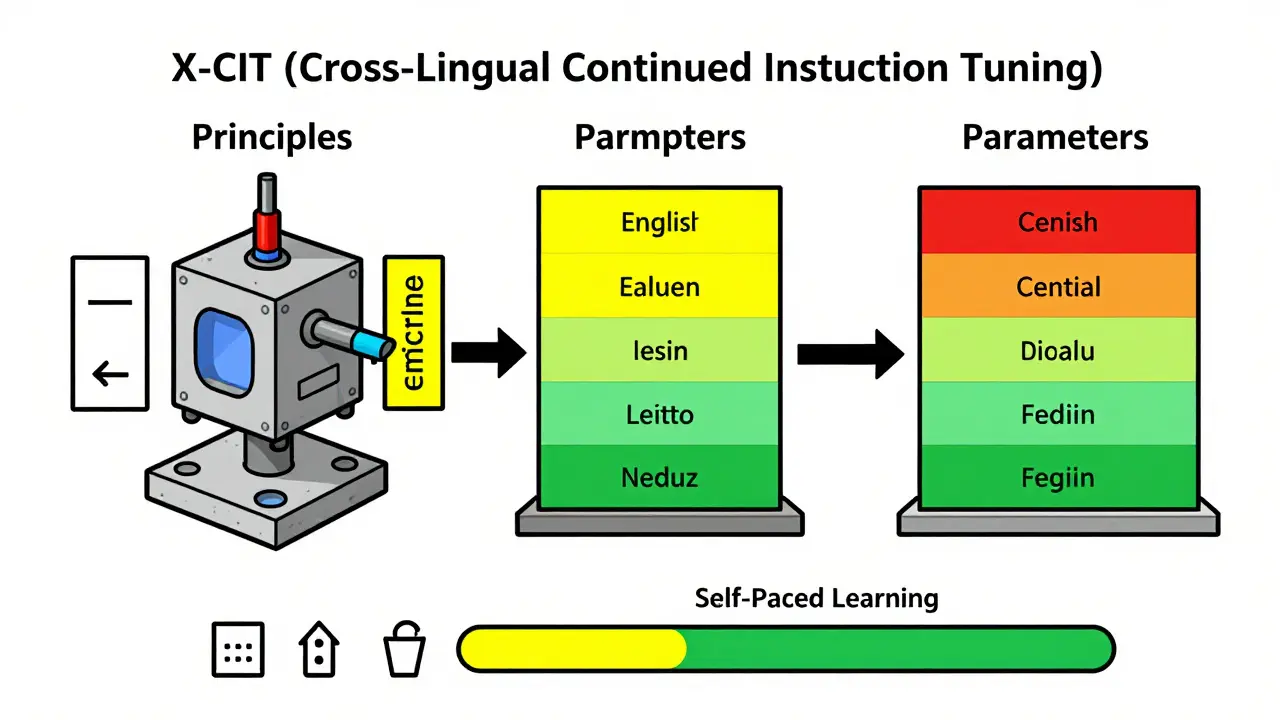
The Human Approach: Cross-Lingual Continued Instruction Tuning (X-CIT)
One of the most effective methods emerging in recent studies is Cross-Lingual Continued Instruction Tuning, or X-CIT. Presented at the Association for Computational Linguistics (ACL) conference, this approach draws inspiration from Chomsky's Principles and Parameters Theory of human language acquisition.
Here is how X-CIT works in practice:
- Establish Principles: First, you fine-tune the Large Language Model on high-quality English instruction data. This establishes the foundational reasoning capabilities and logical structures (the "principles").
- Adjust Parameters: Next, you continue training with target-language translations and customized chat-instruction data. This adjusts the specific linguistic parameters (vocabulary, grammar, syntax) for the new language.
- Mimic Learning Progression: The method uses Self-Paced Learning (SPL). Just as a human learns simple words before complex idioms, the model advances from easy tasks to harder ones. This prevents the model from getting overwhelmed by complex linguistic nuances too early.
When tested on the Llama-2-7B model across five different languages, X-CIT improved performance by an average of 1.97% on objective benchmarks and a significant 8.2% on LLM-as-a-judge evaluations. That jump in judge-based scoring suggests the responses felt more natural and aligned with user intent, not just statistically correct.
| Method | Core Mechanism | Best For | Limitation |
|---|---|---|---|
| Standard Supervised Fine-Tuning (SFT) | Training on translated instruction pairs | Quick prototypes, high-resource languages | Poor semantic alignment, "translationese" output |
| X-CIT | Phased learning mimicking human acquisition | High-quality conversational AI | Requires structured phased dataset creation |
| CrossAlpaca | Translation-following demonstrations | Question Answering, factual retrieval | Less effective for creative generation |
| Modular Merging | Separating math/reasoning from language layers | Low-resource languages, specialized tasks | Complex implementation, requires expert merging |
Semantic Alignment with CrossAlpaca
If your primary goal is accuracy in information retrieval rather than open-ended conversation, look at the CrossAlpaca approach. This method focuses heavily on "Translation-following" demonstrations. Instead of just asking the model to answer a question in the target language, you provide examples where the model explicitly follows a translation step before answering.
This technique forces the model to maintain tight semantic links between the source and target languages. In tests on multilingual Question Answering benchmarks like XQUAD and MLQA, CrossAlpaca outperformed models tuned only on monolingual data across six languages. It proves that showing the model *how* to bridge the language gap is more valuable than just giving it the destination data.
Modular Approaches for Low-Resource Languages
What if you don’t have enough data for a full fine-tuning run? Many languages lack the vast corpora needed for traditional training. Here, modular approaches shine. Research indicates that the parts of a model responsible for mathematical reasoning are distinct from those handling linguistic nuances.
By freezing the reasoning parameters and only updating the language-specific layers, or by using Layer-Swapping to merge separate "language experts" with a base model, you can achieve strong results with minimal data. This is particularly useful for low-resource languages where task-specific post-training data is scarce. The key insight here is that reverting less useful fine-tuning updates after training often yields better results than trying to freeze parameters from the start.
Handling Code-Switching and Real-World Speech
Real users don't speak in pure, academic sentences. Bilingual speakers often code-switch, mixing two languages within a single sentence. A model trained only on pure Spanish or pure English will fail here.
Recent work presented at the RESOURCEFUL-2025 workshop addressed this by fine-tuning models on code-switched combinations of Indian languages and English. They introduced the S-index (Switching-Index), a metric to measure the level of code-switching in an utterance. By training on this messy, realistic data, models learned to generalize and perform Part-of-Speech (POS) tagging even on combinations they hadn't seen during training. If your AI interacts with diverse communities, ignoring code-switching means ignoring your actual users.

Implementation Checklist for 2026
To adapt your Large Language Model effectively, follow these steps:
- Audit Your Base Model: Choose a model with strong baseline multilingual support (like Llama-3 or Mistral variants) rather than English-only architectures.
- Curate Parallel Data: Gather high-quality instruction sets in both English and your target language. Ensure the translations are culturally nuanced, not literal.
- Select Your Strategy: Use X-CIT for conversational agents, CrossAlpaca for QA systems, or Modular Merging for data-scarce scenarios.
- Implement Self-Paced Learning: Structure your training data from simple to complex to avoid catastrophic forgetting of core reasoning skills.
- Evaluate Holistically: Don't rely solely on BLEU scores. Use LLM-as-a-judge metrics to assess fluency and cultural appropriateness.
Future Directions: Beyond Text
The field is expanding beyond natural language. Researchers are now exploring cross-lingual fine-tuning for code generation, allowing developers to write comments and documentation in their native language while generating code efficiently. As models become more multimodal, expect to see these techniques applied to voice and video, further breaking down language barriers in real-time interactions.
What is the difference between cross-lingual fine-tuning and standard fine-tuning?
Standard fine-tuning usually focuses on adapting a model to a specific task or domain within a single language. Cross-lingual fine-tuning specifically targets the adaptation of a model from one language (typically English) to another, focusing on bridging semantic gaps and adjusting linguistic parameters to ensure the model understands and generates text naturally in the target language.
Do I need a lot of data for cross-lingual fine-tuning?
It depends on the method. Approaches like X-CIT require high-quality parallel instruction data. However, for low-resource languages, modular approaches and model merging allow you to achieve good results with significantly less data by leveraging the model's existing multilingual pre-training and only updating specific layers.
Which base models are best for cross-lingual adaptation?
Models with strong initial multilingual training, such as Llama-3, Mistral, or Qwen, are ideal candidates. Starting with a model that already has some exposure to the target language reduces the effort needed for fine-tuning compared to starting with an English-only model.
How do I evaluate the success of my cross-lingual fine-tuning?
Use a combination of objective benchmarks (like XQUAD or MLQA for QA tasks) and subjective evaluations (LLM-as-a-judge). Objective metrics check for correctness, while judge-based metrics assess fluency, cultural nuance, and adherence to instructions, which are critical for user satisfaction.
Can cross-lingual fine-tuning help with code-switching?
Yes. By including code-switched data in your fine-tuning set-where users mix two languages in a single sentence-you can train the model to handle this common real-world scenario. Specialized metrics like the S-index can help you measure and improve this capability.