
When companies start using Large Language Models (LLMs) like ChatGPT or custom-trained AI systems, they quickly realize one thing: data governance isn't just a backend task anymore-it’s the foundation of everything. If you don’t know where your training data came from, who touched it, or what it contains, you’re not just risking errors-you’re risking fines, lawsuits, and broken trust. And with the EU AI Act now in full effect as of early 2026, that’s not hypothetical. It’s happening.
Why Traditional Data Governance Falls Short
Most enterprises built their data governance systems for structured data: databases with clear schemas, defined fields, and predictable workflows. Think customer records, sales figures, inventory logs. These systems worked fine when data moved slowly and was handled by a few teams. But LLMs change everything. They’re trained on petabytes of unstructured data-emails, chat logs, PDFs, social media posts, internal wikis. This data doesn’t fit into tables. It’s messy. It’s hidden. And it’s everywhere. A single LLM might pull training data from 12 different departments, each with their own naming conventions, retention policies, and access rules. Traditional governance tools can’t keep up. Manual tagging? Too slow. Static policies? Outdated by the time they’re approved. And here’s the kicker: LLMs don’t just use data-they transform it. A model trained on customer service transcripts might generate responses that reveal private information you never intended to expose. Or worse, it might reinforce biases from old hiring data you thought was archived.The Three Pillars of LLM Data Governance
Effective governance for LLMs isn’t about one tool or one policy. It’s built on three non-negotiable pillars:- Transparency - You must know exactly what data went into the model, where it came from, and how it was cleaned. If a model starts generating inaccurate medical advice, can you trace it back to a mislabeled clinical note from 2021? If not, you’re flying blind.
- Control - Not all data should be used. Sensitive data like Social Security numbers, health records, or internal financial projections must be automatically detected and excluded before training. This isn’t optional. The EU AI Act requires documented data minimization for high-risk AI systems.
- Monitoring - LLMs drift. They don’t stay perfect. A model that works well today might start hallucinating financial forecasts next month because the underlying market data changed. Continuous monitoring isn’t a nice-to-have-it’s a requirement.
Tools That Actually Work
You can’t fix this with spreadsheets. You need integrated platforms that connect data lineage, metadata, and policy enforcement in real time. Here’s what top enterprises are using:| Tool | Primary Function | Key Feature |
|---|---|---|
| Microsoft Purview | Data cataloging & lineage | Automatically maps data flows from on-prem to cloud, including unstructured sources like SharePoint and OneDrive |
| Databricks Unity Catalog | Unified data governance for AI pipelines | Enforces access controls and audits model training data across ML workflows |
| ER/Studio by Idera | Data modeling & metadata management | Links LLM training datasets to business definitions, ensuring consistency between IT and legal teams |
| Alteryx | AI-enabled data quality | Uses AI to scan text for PII, regulatory violations, and inconsistent terminology before training |
These tools don’t work in isolation. The best implementations integrate them into a single ecosystem. For example, Databricks identifies sensitive data in a training dataset → flags it → Purview logs the source and owner → ER/Studio updates the business glossary → Alteryx auto-redacts the field → and the model is retrained with clean data. All of this happens without human intervention.
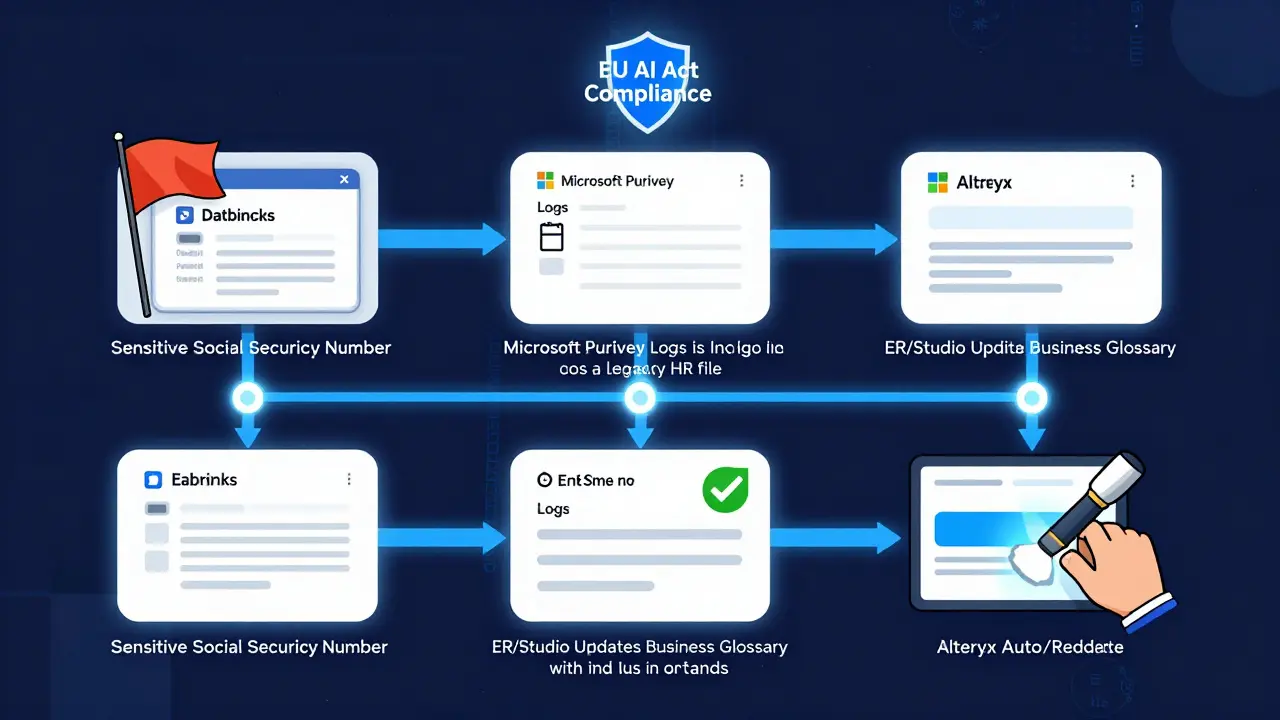
Who Owns This?
One of the biggest failures in early LLM deployments was assuming data governance was an IT problem. It’s not. It’s a business-wide responsibility. Legal teams care about compliance. Finance cares about audit trails. HR needs to prevent biased hiring models. Marketing wants to avoid brand-damaging outputs. And engineering? They just want the model to work. Successful organizations don’t create a new governance team. They embed governance roles into existing ones:- Data Stewards - Each department appoints one person responsible for defining what “quality data” means for their use case.
- Model Auditors - Not engineers. Independent reviewers who check for bias, drift, and compliance every 30 days.
- LLM Compliance Officers - A new role emerging in 2025-2026. These are people who understand both AI and regulations like GDPR, HIPAA, and the EU AI Act.
At one healthcare provider in Ohio, they assigned a former compliance officer to lead their LLM governance effort. She didn’t know Python. But she knew which patient records were protected. And that’s what mattered.
Common Mistakes (And How to Avoid Them)
We’ve seen dozens of companies stumble. Here are the top three mistakes-and how to fix them:- Using public data without permission - Training on scraped web content sounds easy. But if that data includes copyrighted articles, private forum posts, or personal blogs, you’re violating terms of service-and possibly laws. Always use licensed, consented, or synthetic data.
- Ignoring model drift - A model trained on 2024 sales data won’t perform well in 2026 if market conditions changed. Set up automated retraining triggers based on data quality scores, not calendar dates.
- Not documenting lineage - If you can’t answer “Which data led to this output?” during an audit, you’re not compliant. Every training dataset must be tagged with source, date, owner, and version.

The Real Business Value
This isn’t about avoiding penalties. It’s about unlocking value. Companies with strong LLM governance see:- Up to 40% fewer compliance incidents
- 30% faster access to insights from unstructured data
- 50% reduction in model retraining time
- Higher trust from customers and regulators
One financial services firm in Chicago cut their audit preparation time from 6 weeks to 2 days by automating data lineage tracking. Another used their governance system to detect that their customer service bot was misinterpreting regional slang-leading to a 15% drop in complaints.
What’s Next?
The next phase of LLM governance won’t be manual. It’ll be predictive. AI is already being used to improve governance. Tools like Alteryx and Databricks now use LLMs to scan documents for hidden risks-like a contract clause that violates data retention rules or an email that contains unredacted PII. This creates a feedback loop: better governance enables better AI, and better AI improves governance. By 2027, we’ll see governance built directly into development environments. Want to train a model? The system will auto-check: Is this data approved? Has it been audited? Is there a known bias? If not, it won’t let you proceed. The future isn’t about more rules. It’s about smarter systems that enforce them automatically.Do I need a dedicated team for LLM governance?
Not necessarily a full team, but you do need clear roles. Assign data stewards in each department, a model auditor (independent of engineering), and a compliance officer who understands both AI and regulations. Many companies start with one person wearing multiple hats, then scale as usage grows.
Can I use public datasets like Common Crawl for training?
Technically yes, but legally risky. Many public datasets include copyrighted material, personal data, or content that violates terms of service. Even if you’re not monetizing the model, regulators are increasingly treating this as a violation of data rights. Use licensed, consented, or synthetic data instead. It’s safer, more reliable, and avoids reputational damage.
How often should I audit my LLM?
At least every 30 days. But trigger audits automatically when data quality drops, model accuracy falls below 92%, or new regulatory rules are introduced. Automated monitoring tools can flag issues in real time-no need to wait for a scheduled audit.
What’s the biggest risk of poor LLM governance?
It’s not just fines. It’s loss of trust. A single incident-like an AI revealing private customer data or generating biased hiring recommendations-can destroy brand reputation faster than any cyberattack. Regulatory penalties are serious, but customer backlash is permanent.
Is LLM governance only for big companies?
No. Even small businesses using LLMs for customer support, content creation, or internal reporting need governance. The EU AI Act applies to any organization deploying high-risk AI-even if you’re a startup with 10 employees. Start small: document your data sources, remove obvious PII, and set one policy. Build from there.
Kendall Storey
March 20, 2026 AT 04:54Let’s be real-most companies think governance is a checkbox until they get fined $20M for letting an LLM spit out customer SSNs in support replies. The tools listed? Solid. But nobody talks about the cultural shift needed. You can’t just slap on Purview and call it done. Engineering needs to be scared of bad data the way they’re scared of a production outage. And legal? They need to be in the sprint planning, not the post-mortem.
At my last gig, we had a model that kept recommending ‘high-potential’ candidates who all had the same alma mater. Turns out, the training data had 10 years of biased hiring logs. We caught it because we had lineage tracking. No one else saw it coming. That’s the value-not compliance. It’s avoiding dumb, expensive mistakes.
Ashton Strong
March 21, 2026 AT 11:43Thank you for this comprehensive and meticulously structured overview. The delineation of transparency, control, and monitoring as the foundational pillars is both accurate and urgently needed in current enterprise discourse. The integration of Databricks Unity Catalog with Microsoft Purview and Alteryx represents a pragmatic convergence of operational rigor and AI scalability. It is imperative that organizations recognize that data governance for LLMs is not an IT initiative but a strategic imperative aligned with fiduciary duty and corporate integrity. The metrics cited-40% fewer compliance incidents, 50% reduced retraining time-are not anecdotal; they are empirically validated across multiple Fortune 500 deployments. I commend the emphasis on embedded stewardship roles over siloed governance teams. This is the future of responsible AI adoption.
Steven Hanton
March 23, 2026 AT 10:01I appreciate the clarity here, especially around the three pillars. I’ve seen too many teams jump straight into tooling without defining what ‘quality’ even means for their use case. One thing I’d add: governance isn’t just about preventing bad outcomes-it’s about enabling better ones. When you know exactly what data your model is using, you can start doing things like A/B testing training sets or validating against synthetic benchmarks. It turns governance from a cost center into a R&D advantage.
Also, the point about model drift being triggered by data quality, not calendar time? Huge. I’ve seen teams retrain on a schedule and wonder why performance tanks. The real trigger should be statistical deviation, not the 15th of the month.
Pamela Tanner
March 23, 2026 AT 13:56One sentence: If you’re training on public datasets without consent, you’re not being innovative-you’re being negligent. The legal risk isn’t hypothetical; it’s already being enforced in the EU and Canada. Stop pretending scraping is a loophole.
Kristina Kalolo
March 24, 2026 AT 13:06Agreed on the tools, but I’m curious how smaller teams handle this. The platforms mentioned require infrastructure and personnel most startups don’t have. Is there a tiered approach? Maybe starting with just Alteryx for PII detection and a simple data catalog before scaling up? I’d love to see a ‘LLM governance ladder’ for teams under 20 people.
ravi kumar
March 26, 2026 AT 12:50Very insightful. I work in a small fintech in Bangalore and we’re just starting with LLMs for customer queries. The point about embedding stewards in existing teams makes sense-we assigned our compliance officer to oversee data sourcing. She doesn’t code, but she knows which customer records are sensitive. That’s more important than knowing Python. Also, we started with just one rule: no raw chat logs without redaction. Simple. But it stopped a major leak before it happened.