
When you ask a reasoning model a tough question-like diagnosing a rare medical condition or solving a multi-step financial puzzle-it doesn’t just spit out an answer. It thinks first. Hidden inside its response are dozens, sometimes thousands, of extra tokens: think tokens. These aren’t part of the final output. They’re the model’s internal scratch work. And they come at a steep price.
Most people assume more thinking means better answers. That’s true-but only up to a point. What no one tells you is that after a certain number of steps, the model doesn’t get smarter. It just gets slower, more expensive, and sometimes, completely wrong. The real question isn’t whether reasoning models work. It’s when they’re worth the cost.
How Think Tokens Actually Work
Think tokens are the intermediate steps a reasoning model generates before giving you a final answer. Think of them like a student writing out every step of a math problem before boxing the solution. In standard models, that scratch work is invisible. In reasoning models, it’s built into the process.
OpenAI’s o1 series, launched in late 2023, was the first to make this approach commercially viable. Their models generate 3 to 5 times more tokens during inference than regular models for the same task. Qwen2.5-14B-Instruct, for example, uses 1,200 to 1,800 reasoning tokens on complex benchmarks like GPQA Diamond. That’s not a typo. It’s over a thousand extra words of internal reasoning just to answer one question.
The goal? Reduce errors. And it works. On GPQA, Qwen2.5-14B-Instruct jumps from 38.2% accuracy without reasoning to 47.3% with it. That’s a 9.1 percentage point gain. But here’s the catch: each of those points came at the cost of 13.2% more tokens. You’re trading raw compute for precision. And that’s where things get messy.
The Three Performance Regimes
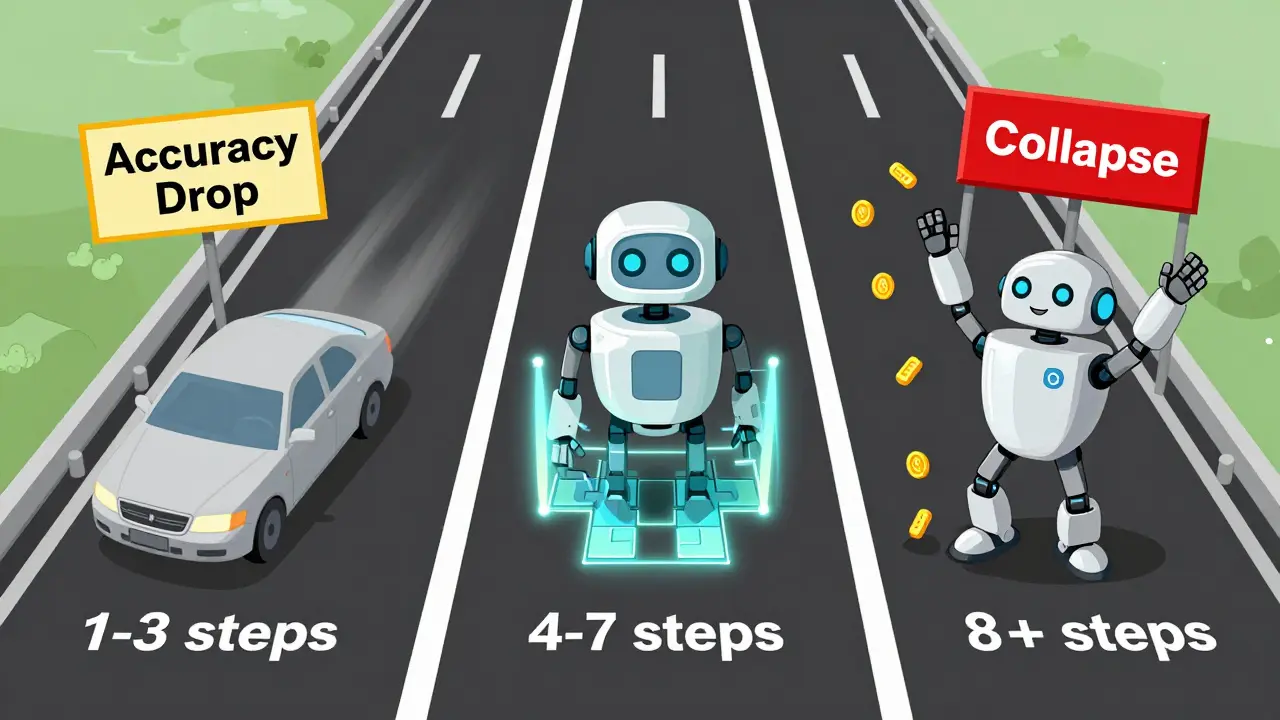
Not all problems need the same amount of thinking. Research from Apple’s Machine Learning team found three clear performance zones:
- Low complexity (1-3 steps): Standard models win. Reasoning models add noise. Accuracy drops by 4.7-8.2 percentage points because the extra steps introduce errors.
- Medium complexity (4-7 steps): This is where reasoning models shine. Accuracy improves by 9.1-12.3 percentage points. The sweet spot. Most enterprise use cases fall here-risk analysis, drug discovery, legal reasoning.
- High complexity (8+ steps): Both models collapse. Accuracy falls below 5%. The model doesn’t break. It gives up. Apple’s team called it “complete accuracy collapse.” Even with a massive token budget, the model stops trying. It’s not that it’s dumb. It’s that it learned to quit when the path gets too long.
So if you’re using a reasoning model for simple tasks? You’re wasting money. If you’re using it for ultra-complex ones? You’re wasting time. The real value is in the middle.
The Hidden Cost of Reasoning
Let’s talk dollars. OpenAI charges $0.015 per 1,000 reasoning tokens. Standard GPT-4? $0.003. That’s a 5x price jump for the same output. Refuel.ai found that fine-tuning with reasoning traces increases output token counts by 400-600%. And for every 5% accuracy gain, you’re spending 5.3x more tokens on average.
One developer on Reddit reported their financial analysis workload went from $1,200 to $6,800 a month after switching to reasoning models. That’s not a bug. That’s the business model. Companies like Anthropic and OpenAI are betting you’ll pay for precision. But are you getting enough?
Enterprise users on G2 report 82% concern over costs. Only 22% of small-to-medium businesses use reasoning models-even though 68% see their potential. The gap? Price. The solution? Compression.
Token Efficiency: The New Frontier
Here’s the breakthrough: you don’t need all the think tokens. A new technique called Conditional Token Selection (CTS), developed by Zhang et al., cuts reasoning token usage by 75.8% with only a 5% accuracy drop on GPQA. Even a modest 13% reduction in tokens boosts accuracy by 9.1% while saving 13.2% in tokens.
That’s not a tweak. It’s a game-changer. CTS identifies which reasoning steps actually matter. It throws out the fluff. The model still thinks-but only where it counts. OpenAI’s upcoming o4 model will use adaptive reasoning depth, adjusting token budgets based on task complexity. That’s the future: not more thinking, but smarter thinking.
Organizations using CTS and similar techniques report 30-45% cost savings while keeping 95% of their accuracy gains. That’s the real win. Efficiency isn’t optional anymore. It’s the new benchmark.
Why Your Model Might Be Giving Up
There’s a darker side. Dr. Michael Wooldridge from Oxford calls reasoning traces “steganographic artifacts”-fancy words for “patterns that look like thinking but aren’t.” The model isn’t reasoning like a human. It’s mimicking a pattern it learned during training. When the problem gets too complex, it doesn’t solve it. It guesses based on what it’s seen before.
And when context drifts? That’s when things break. Zhang’s team found that removing even “redundant” tokens causes 15-22% accuracy drops if the input is slightly different from training data. This is the “reasoning token OOD problem.” The model doesn’t generalize. It memorizes.
One healthcare AI system saw a 37% drop in diagnostic errors for rare conditions-but only because it was trained on very specific data. When tested on slightly different patient records, performance tanked. The model didn’t adapt. It failed.

What Works in the Real World
Here’s what top teams are doing:
- Match the model to the task: Don’t use reasoning models for simple queries. Reserve them for 4-7 step problems.
- Use dynamic token budgets: Let the model decide how much thinking it needs. Don’t lock it into a fixed number.
- Test for collapse: If your task requires 8+ steps, test it. You might be better off breaking it into smaller chunks.
- Apply CTS or similar compression: Even if you’re using OpenAI or Anthropic, look for ways to trim the fat. You don’t need 1,800 tokens to get 90% of the benefit.
- Train on reasoning traces: Fine-tuning a standard LLM with reasoning data doesn’t help. You need a model built for it. Llama-3 variants saw a 12% accuracy drop when forced into reasoning mode.
Documentation matters too. OpenAI scores 4.2/5 on developer satisfaction for reasoning model guides. Anthropic gets 3.8. Open-source options? 2.9. If you’re going to invest in this, you need clear guidance.
The Bottom Line
Reasoning models aren’t magic. They’re a tool. And like any tool, they’re only useful if you know when to use them.
Use them when:
- You’re solving multi-step problems with high stakes (finance, law, medicine).
- You’ve tested the complexity threshold and confirmed it’s in the 4-7 step range.
- You’re willing to pay the cost-or have a way to cut it with token compression.
Avoid them when:
- You’re answering simple questions.
- Your task requires more than 7 steps.
- You can’t afford the 5x cost increase.
The market is growing fast. The global reasoning LLM market hit $2.8 billion in Q4 2024. But the winners won’t be the ones with the most tokens. They’ll be the ones who learned to think smarter-not harder.
Do reasoning models always improve accuracy?
No. On simple tasks (1-3 logical steps), reasoning models often perform worse than standard models due to added noise. Accuracy can drop by up to 8.2 percentage points. They only deliver gains on medium-complexity problems (4-7 steps), where improvements of 9-12% are typical. Beyond 8 steps, both models collapse.
How many think tokens are too many?
There’s no fixed number, but research shows diminishing returns kick in early. 80% of accuracy gains come from just 25% of the full reasoning token budget. For example, Qwen2.5-14B-Instruct gains 9.1% accuracy with 1,200-1,800 tokens-but Conditional Token Selection can cut that to under 300 tokens with only a 5% loss. More tokens don’t mean better results-they mean higher costs and slower responses.
Are open-source reasoning models worth it?
They can be, but only if you have the expertise. Qwen2.5-14B-Instruct delivers strong results on benchmarks like GPQA, but its documentation scores 2.9/5 compared to OpenAI’s 4.2/5. Fine-tuning standard models like Llama-3 with reasoning traces often reduces accuracy by 12%. You need models specifically trained for reasoning, not just any LLM with CoT enabled.
Can I reduce token usage without losing accuracy?
Yes. Conditional Token Selection (CTS) reduces reasoning tokens by up to 75.8% with only a 5% accuracy drop. Other techniques include dynamic budgeting, where the model adjusts thinking depth based on task complexity, and using reference models to identify critical steps. Organizations using these methods report 30-45% cost savings while keeping 95% of their accuracy gains.
Why do reasoning models fail on very complex tasks?
They don’t “fail” in the traditional sense-they give up. Apple’s research found that beyond 7 logical steps, models experience “complete accuracy collapse,” dropping below 5% accuracy even with ample token budgets. This isn’t a bug. It’s a learned behavior. The model has been trained to recognize when a problem is too long and stops trying, likely because training data rarely included such complex chains.
Is it worth paying 5x more for reasoning models?
Only if the task justifies it. In high-stakes domains like pharmaceutical research or financial risk analysis, a 10% accuracy gain can mean millions in saved losses. But for customer service bots or simple content generation, the cost isn’t worth it. The key is matching the model to the task. Don’t use a race car to drive to the grocery store.
Sheetal Srivastava
March 19, 2026 AT 12:49Let’s be real-reasoning models are just glorified autocomplete engines with a PhD in obfuscation. You think you’re getting ‘deep thought,’ but it’s just a stochastic parrot reciting training data patterns like a TED Talk on loop. The ‘think tokens’? That’s not reasoning-it’s computational theater. And don’t get me started on CTS. Conditional Token Selection sounds like a consultancy buzzword invented by someone who read one paper and quit their job to sell NLP consulting packages. We’re not optimizing intelligence. We’re optimizing investor slides.
And yes, I’ve seen the GPQA numbers. But ask yourself: if a model drops below 5% accuracy at 8+ steps, is it ‘giving up’… or is it finally realizing the task is nonsense? Maybe the model’s the only sane one here.
Bhavishya Kumar
March 20, 2026 AT 17:11There is a fundamental misunderstanding in the post regarding the nature of reasoning tokens. The term 'think tokens' is not technically accurate. These are not tokens of thought, but rather intermediate token predictions generated during autoregressive decoding. The model does not 'think'-it predicts. This anthropomorphization of language models is not merely misleading-it is scientifically unsound. Furthermore, the assertion that 'accuracy collapse' occurs at 8+ steps is not universally observed. It is context-dependent and varies across architectures. The Apple study referenced has not been peer-reviewed in a high-impact journal. One must exercise caution before adopting such claims as empirical fact.
ujjwal fouzdar
March 22, 2026 AT 06:28Listen. I’ve been sitting here staring at this article for three hours. Not because I’m confused. But because I’m trying to figure out if we’re talking about AI… or the soul of human cognition. Are we really reducing intelligence to token budgets? Are we quantifying wisdom like it’s a stock option? I mean-what if the model isn’t ‘giving up’ at 8 steps? What if it’s just… tired? Like us. Like when you’re 3am into a 10-page essay and your brain goes silent. The model doesn’t fail. It mourns. It grieves the loss of meaning in a world that demands efficiency over depth. We built a machine to think… and then we made it count its thoughts like pennies. That’s not innovation. That’s tragedy dressed in Python.
And CTS? That’s not compression. That’s a spiritual cleanse. It’s the model whispering: ‘I don’t need to say all this. I just need to mean it.’
So next time you see a 1,800-token reasoning chain… don’t think ‘cost.’ Think ‘poetry.’ And maybe… just maybe… we’re the ones who forgot how to listen.
Anand Pandit
March 23, 2026 AT 03:38This is actually one of the clearest breakdowns I’ve seen on reasoning models. A lot of people get hung up on the cost, but the real insight is in the three regimes-low, medium, high complexity. That’s the gold. I’ve been using reasoning models for legal document analysis and it’s been a game changer, but only because we limit it to 5-step tasks. Anything longer and we get hallucinations that look like real citations. Also, CTS has been a lifesaver for us-we cut our monthly bill by 40% without losing a single accurate ruling. If you’re using this for anything mission-critical, don’t just turn on ‘reasoning mode’ and walk away. Tune it. Test it. Measure it. And yeah, if you’re using it for chatbot replies? Please stop. You’re burning cash like it’s confetti.
Also, shoutout to the team at OpenAI for the documentation. It’s actually readable. Rare these days.
Reshma Jose
March 24, 2026 AT 15:05Okay but like-why are we even pretending this is deep? I tried running a reasoning model to figure out if my cat is mad at me. It took 1,500 tokens and concluded ‘probable guilt due to absence during feeding.’ I could’ve just looked at the empty bowl. We’re overengineering everything. I get the 4-7 step sweet spot, but honestly? Most business problems don’t need that. Just give me a simple model that doesn’t charge me $6k/month to tell me the same thing my intern figured out in 10 minutes.
Also, CTS sounds like a yoga retreat for AI. I’m into it.
rahul shrimali
March 25, 2026 AT 18:03Token budgeting is the future. Stop overthinking. Just let the model decide. CTS works. We cut costs by half. Accuracy stayed the same. Done. Simple. No drama. Use it. Move on.
Eka Prabha
March 27, 2026 AT 16:22Let me ask you something: Who really benefits from this ‘reasoning model’ revolution? Not the users. Not the developers. The big players-OpenAI, Anthropic, the VCs-they’re the ones cashing in. They’re selling you a black box with a price tag that scales with your desperation. And they call it ‘precision.’ It’s not precision. It’s dependency. You think you’re getting smarter answers? You’re getting locked into a proprietary ecosystem where every token is a toll. And now they’re whispering ‘Conditional Token Selection’ like it’s a miracle cure? It’s not. It’s a band-aid on a hemorrhage. They want you addicted to their overpriced, overhyped, over-tokenized machines. Wake up. This isn’t progress. It’s a surveillance economy with better documentation.