Remember when you had to guess the exact keywords a database wanted? You’d type "cloud migration cost," get zero results, then try "server move budget," and still come up empty. That era is ending. Large Language Models (LLMs) are turning search engines from dumb lookup tools into intelligent systems that actually understand what you mean. This isn't just about better spelling correction; it's about a fundamental shift in how machines process human intent.
We are moving from keyword matching to semantic understanding. When an LLM powers your search, it doesn't just look for the word "cost." It understands the concept of financial planning, budget constraints, and resource allocation. For businesses dealing with massive amounts of data, this difference between finding a document and finding the *right* answer is the gap between inefficiency and competitive advantage.
The Core Shift: From Keywords to Meaning
Traditional search relies on inverted indices. Think of it like a library card catalog where every book is listed under specific words. If the book says "feline" but you search for "cat," traditional search might miss it unless there’s a manual synonym link. It’s brittle. It breaks down with nuance, slang, or complex queries.
Semantic search changes the game by converting text into numbers-specifically, vectors. These aren't random numbers. They are high-dimensional coordinates that map meaning. In this mathematical space, words with similar meanings sit close together. "Server migration" and "cloud transition" might have different words, but their vector representations overlap significantly because they describe the same business activity.
| Feature | Traditional Keyword Search | LLM-Powered Semantic Search |
|---|---|---|
| Matching Logic | Exact string matches | Conceptual similarity via vectors |
| Context Awareness | Low (ignores surrounding words) | High (understands sentence structure) |
| Synonym Handling | Requires manual lists | Automatic via embedding geometry |
| User Intent | Limited to explicit terms | Infers implicit needs |
This shift allows systems to recognize that "Oracle Cloud Infrastructure benefits" and "OCI advantages" are semantically identical, even if the phrasing differs. The LLM acts as the translator between human ambiguity and machine precision.
How LLMs Power Modern Search Architecture
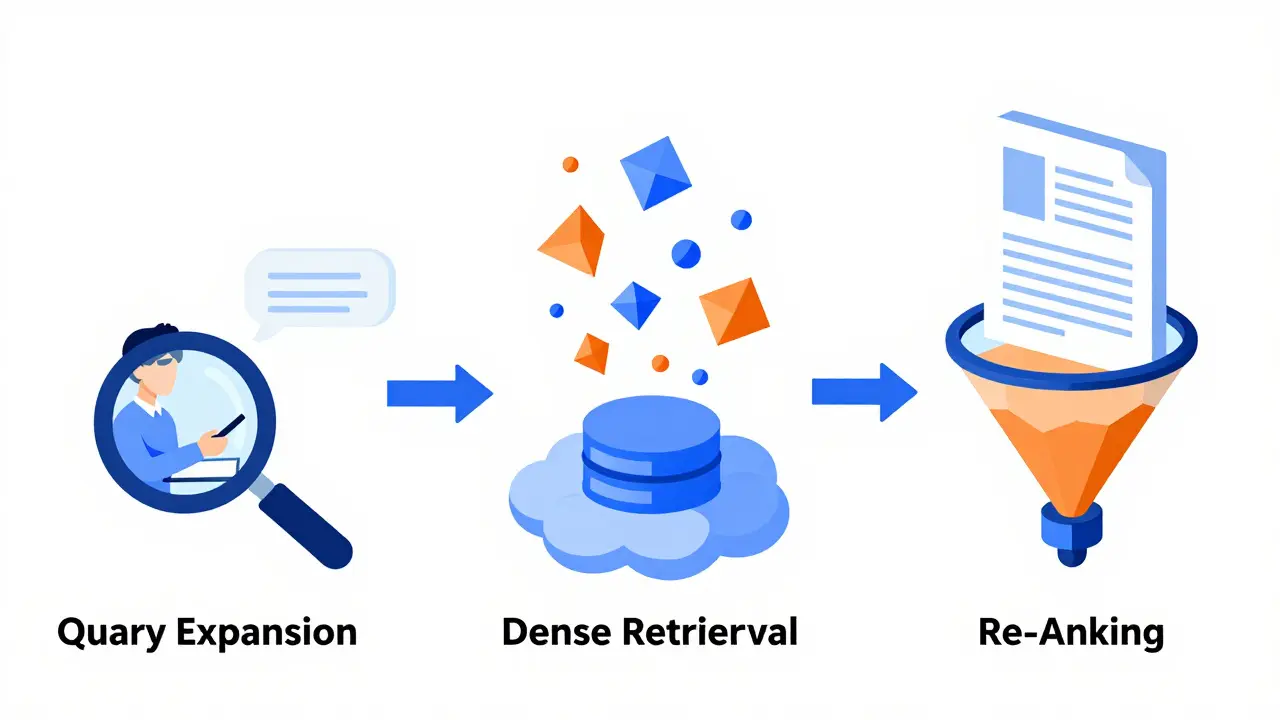
You don't just plug an LLM into a search bar and call it a day. Effective implementation requires a multi-stage pipeline. Most robust systems today use a combination of three techniques: Query Expansion, Dense Retrieval, and Re-ranking. Each stage solves a specific problem in the retrieval process.
1. Query Expansion: Catching What You Didn't Say
Users are often lazy or vague. A developer might type "AWS vs OCI cost." An LLM-based system recognizes this is incomplete. It expands the query automatically before searching. It might generate additional search strings like "Oracle Cloud pricing model 2026," "migrating database to OCI expenses," and "cloud vendor comparison sheet."
This proactive enrichment improves recall-the ability to find all relevant documents. Without expansion, you risk missing critical information simply because the user didn't use the technical jargon stored in your database. The LLM anticipates the need, broadening the net without cluttering the user interface.
2. Dense Retrieval: The Speed Layer
Once the query is expanded, the system needs to scan millions of documents quickly. This is where dense retrieval comes in. Instead of scanning text character by character, the system compares vector embeddings.
LLMs generate these embeddings with far more nuance than older models. Older embedding models might treat "bank" (river) and "bank" (finance) as similar if they appear in similar syntactic positions. Modern LLMs, trained on billions of parameters using masked language modeling, understand context deeply. They know which "bank" you mean based on the surrounding words. This ensures that the initial pool of retrieved documents is highly relevant, not just topically adjacent.
3. Re-Ranking: The Precision Layer
Dense retrieval is fast, but it can be slightly imprecise. It gets you to the right neighborhood, but not necessarily the right house. This is where re-ranking models step in. After the initial search returns, say, 50 documents, a specialized cross-encoder model analyzes each document against the original query in detail.
A document mentioning "cloud migration" once might score similarly to one detailing "cloud migration strategies" in the vector search. The re-ranker reads the full context. It sees the detailed strategy guide is more useful for someone asking about costs and moves it to the top. This two-stage approach-fast vector search followed by precise re-ranking-balances speed and accuracy perfectly.
Why Embeddings Matter More Than Ever
The quality of your semantic search depends entirely on the quality of your embeddings. An embedding is a numerical representation of text that captures its semantic meaning. Early models were small and missed subtle linguistic cues. Today’s models, such as MPNet or those derived from large transformer architectures, capture intricate patterns.
These models are pre-trained on massive corpora. During training, they undergo masked language modeling: random words are hidden, and the model must predict them based on context. This forces the model to build a deep, two-way understanding of relationships between words. When you fine-tune these models for specific domains-like legal contracts or medical records-they retain that broad world knowledge while adapting to specialized terminology.
The result? Higher precision and recall. You get fewer irrelevant results (precision) and more of the correct answers (recall). For enterprise applications, this directly correlates to time saved. Employees spend less time sifting through noise and more time acting on insights.
Implementing Semantic Search: Practical Steps
If you're looking to enhance your existing search infrastructure, you don't need to rebuild everything from scratch. Here is a practical roadmap for integrating LLM capabilities:
- Audit Your Current Failures: Identify queries that currently return poor results. Are they failing due to synonyms? Ambiguity? Long-tail complexity? This tells you which part of the pipeline needs help.
- Start with Re-Ranking: This is often the fastest way to inject intelligence. Keep your existing keyword search for speed, but add an LLM-powered re-ranker to the top 50 results. It requires minimal infrastructure change but yields immediate quality improvements.
- Adopt Vector Databases: To support dense retrieval, you need a database that stores and indexes vectors efficiently. Solutions like Pinecone, Weaviate, or Milvus are designed for this. Ensure your schema supports hybrid search (combining keyword and vector).
- Fine-Tune Embeddings: Generic embeddings work okay, but domain-specific ones work better. If you’re in healthcare, fine-tune your embedding model on medical literature. This ensures that "myocardial infarction" and "heart attack" are recognized as identical concepts within your specific context.
- Enable Direct Answer Generation: Once retrieval is solid, use an LLM to synthesize the top results into a direct answer. This transforms your search tool into an "answer engine." Users no longer click through links; they get the summary upfront.
Challenges and Pitfalls to Avoid
While powerful, LLM-enhanced search isn't magic. It introduces new complexities.
Latency: Running heavy LLM inference for every search query can slow down response times. This is why the two-stage approach (vector search + re-ranking) is critical. Never run a full LLM generation step on raw retrieval; only use it for final synthesis or precise re-ranking of a small subset.
Data Freshness: LLMs are static after training. If your knowledge base updates daily, your embeddings must update too. Implement incremental indexing pipelines to ensure new documents are vectorized and searchable immediately. Stale embeddings lead to stale answers.
Hallucination Risks: When generating direct answers, LLMs can sometimes invent facts. Always ground the generation in the retrieved documents. Use techniques like RAG (Retrieval-Augmented Generation) where the LLM is strictly instructed to answer only based on the provided context snippets. If the answer isn't in the snippets, it should say so, rather than guessing.
The Future: Symbiotic Intelligence
We are seeing a symbiotic relationship emerge between search algorithms and LLMs. Google and other major players are already integrating neural components into their ranking pipelines. This creates a feedback loop: better search provides higher-quality data for training LLMs, and better LLMs provide deeper understanding for search algorithms.
For developers and businesses, the takeaway is clear. Keyword search is becoming a legacy technology. The future belongs to systems that understand intent. By leveraging query expansion, dense retrieval, and smart re-ranking, you can build search experiences that feel less like digging through a filing cabinet and more like consulting an expert who knows exactly what you need.
What is the difference between semantic search and keyword search?
Keyword search matches exact words or characters, ignoring context and meaning. Semantic search uses AI to understand the intent behind the query, matching concepts and ideas even if the exact words differ. For example, semantic search understands that "laptop" and "notebook computer" are the same thing, while keyword search does not.
How do LLMs improve search accuracy?
LLMs improve accuracy by generating nuanced vector embeddings that capture context, handling synonyms automatically, and expanding vague queries into comprehensive searches. They also re-rank results based on deep contextual analysis, ensuring the most relevant documents appear at the top.
Is semantic search faster than traditional search?
Pure semantic search can be slower due to computational overhead. However, modern architectures use hybrid approaches. Fast vector retrieval finds candidates quickly, and lightweight re-ranking models refine the order. This balances speed with precision, often delivering better results in acceptable timeframes compared to manual filtering in keyword search.
Do I need to rebuild my entire search engine to use LLMs?
No. You can start by adding a re-ranking layer to your existing search results. This requires minimal changes to your infrastructure but significantly boosts relevance. Later, you can integrate vector databases for dense retrieval and expand to full RAG pipelines for answer generation.
What is query expansion in the context of LLMs?
Query expansion is a technique where an LLM takes a user's short or vague query and generates multiple related, more specific search queries. For example, "cloud cost" might expand to "AWS pricing calculator," "Azure reserved instances savings," and "cloud budgeting best practices." This increases the likelihood of finding all relevant documents.
How do embeddings work in semantic search?
Embeddings convert text into lists of numbers (vectors) that represent meaning. Texts with similar meanings have similar vectors. Search systems compare the vector of your query to vectors of documents in the database. The closer the vectors are in mathematical space, the more semantically similar the content is.
Stephanie Frank
June 28, 2026 AT 19:55honestly this whole semantic search hype is just corporate buzzword bingo designed to sell more cloud storage.
you think vectors are magic? theyre just expensive math that still fails when you ask it something stupid. i spent three weeks trying to get a 'smart' search to understand basic internal jargon and it kept returning me the cafeteria menu because someone used the word 'sandwich' in a technical doc.
the problem isnt the tech, its that people think AI fixes bad data governance. it doesnt. it just makes your garbage look prettier. also why does every article have to be 2000 words to explain what google already does?
Patrick Dorion
June 30, 2026 AT 15:00i feel like we often overlook the philosophical implication of moving from explicit intent to inferred intent.
when we type keywords, we are asserting control over our own information needs. we define the boundaries of our search. but with semantic understanding, we are surrendering that agency to an algorithm that decides what we *might* mean based on statistical probability rather than conscious declaration.
its helpful, sure. but it creates a subtle dependency where the machine knows us better than we know ourselves. have you considered how this shifts the power dynamic between user and tool? it turns search into a conversation where you dont hold all the cards anymore.
Marissa Haque
June 30, 2026 AT 23:50Oh my gosh!! This is literally the best thing I have read all week!!!
I was struggling so much with our old legacy system and now I finally understand why it felt so broken!!! The part about re-ranking being the precision layer is such a game changer for me personally!!
I am going to show this to my team immediately because they need to see this right now!! Thank you so much for writing this clearly!!! It really helps clarify the difference between dense retrieval and just regular keyword matching!!!
Keith Barker
July 2, 2026 AT 14:01vectors are just numbers pretending to be meaning
we project human nuance onto high dimensional space because we lack the humility to admit language is arbitrary
the model does not understand cost
it understands correlation
there is no consciousness in the embedding
only geometry
Lisa Puster
July 4, 2026 AT 13:14typical american tech bro optimism ignoring the fact that real engineering happens elsewhere. you guys sit there talking about 'semantic understanding' while your infrastructure crumbles under latency issues caused by cheap hardware choices.
i built similar systems in germany five years ago using far less compute and better logic. you rely on brute force scaling because you lack architectural discipline.
also stop acting like LLMs are new. we knew embeddings were necessary decades ago. you just needed bigger servers to make up for your lazy coding practices. pathetic really.