
Have you ever asked an AI for a fact and gotten a completely made-up answer delivered with absolute confidence? That’s the nightmare of Large Language Models (LLMs) is a type of artificial intelligence system trained on vast amounts of text data to generate human-like responses. These models are powerful, but they suffer from a critical flaw: they don’t know what they don’t know. Instead of admitting ignorance, they often fabricate plausible-sounding nonsense. This phenomenon, known as hallucination, isn’t just annoying-it can be dangerous in fields like healthcare or law.
The good news? We’re learning how to fix it. Recent breakthroughs in prompt engineering is the practice of designing specific inputs to guide AI behavior and improve output quality have shown that we can teach these models to say “I don’t know.” By using specialized techniques like Uncertainty-Sensitive Tuning (US-Tuning), developers are creating AI systems that recognize their own knowledge gaps. This shift doesn’t just make AI more honest; it makes it safer and more reliable for real-world applications.
Why Do LLMs Lie? Understanding the Root of Hallucinations
To stop an LLM from making things up, you first need to understand why it does. At its core, an LLM is a next-token predictor. It looks at the words before it and guesses the most likely word to come next. It doesn’t have a database of facts it checks against; it has patterns. When you ask a question outside those patterns, the model doesn’t hit a “stop” sign. It keeps going, generating text that fits the statistical probability of language, even if the content is false.
This creates a problem called “instructional inattention.” Research by Dr. Jonathan Kasai at the University of Washington found that even when you explicitly tell a model, “If you don’t know the answer, say so,” it ignores the instruction in over 63% of cases. The model prioritizes being helpful over being accurate. It would rather guess wrong than admit defeat. This is because standard training rewards fluency and completeness, not caution.
Furthermore, traditional fine-tuning often makes this worse. If you train a model only on correct answers (standard QA datasets), it loses its ability to distinguish between what it knows and what it doesn’t. It becomes hyper-confident. To fix this, we need to change the reward structure. We need to teach the model that saying “I don’t know” is sometimes the right answer.
The Two-Stage Solution: How US-Tuning Works
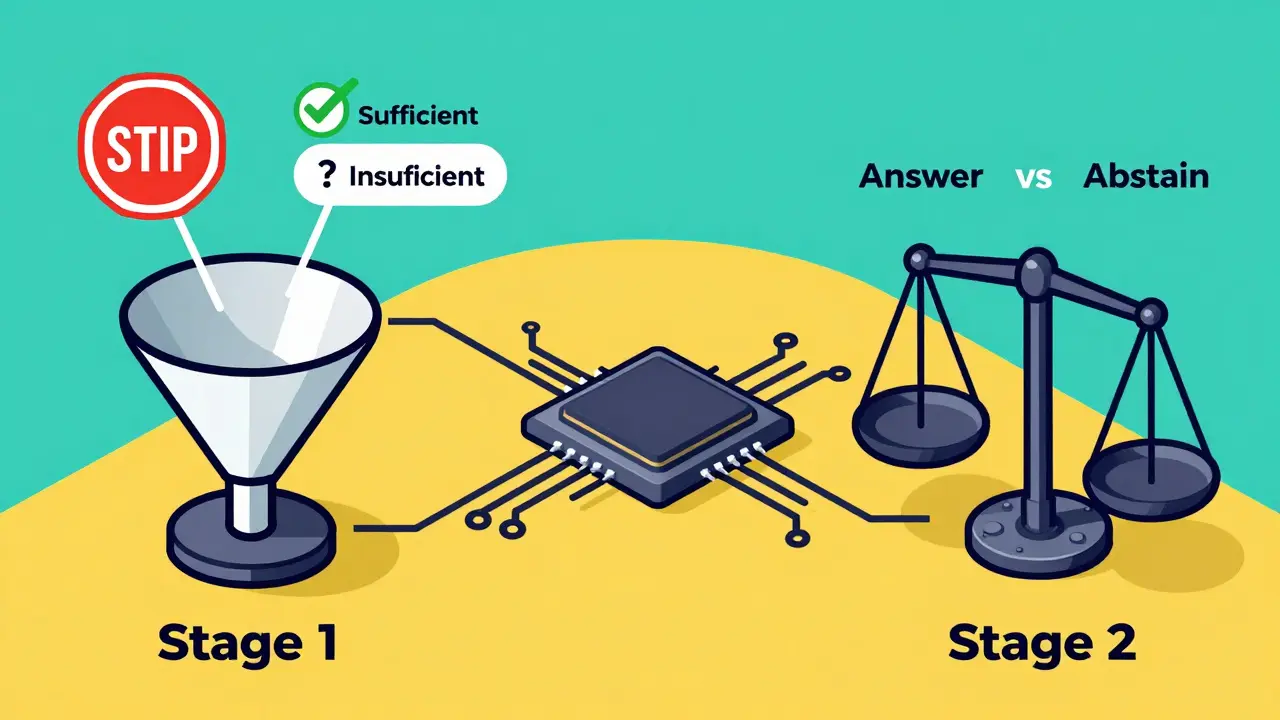
The most effective method currently available is Uncertainty-Sensitive Tuning (US-Tuning) is a two-stage training framework designed to help LLMs recognize knowledge boundaries and reduce hallucinations. Developed by researchers including Cole et al. and Yu et al., this approach treats uncertainty recognition as a binary classification problem. Here is how the process works:
- Stage 1: Uncertainty-Recognition Tuning (UT). In this phase, the model is trained on a specialized dataset containing two types of questions: ones it can answer from the provided context, and ones it cannot. For the unanswerable questions, the correct response is explicitly marked as “Not Provided” or “I don’t know.” This teaches the model to evaluate whether the information given is “Sufficient” or “Insufficient.”
- Stage 2: Prompt-Sensitive Tuning (ST). Stage 1 alone causes a drop in performance on normal questions-the model starts refusing to answer too many things. Stage 2 fixes this by adding “designed causal instructions.” It teaches the model to distinguish between contexts where it should answer versus abstain. It reinforces constraints like, “Your answer must not use any additional knowledge not mentioned in the context.”
This two-step process is crucial. Without Stage 2, the model becomes overly cautious, rejecting nearly 40% of answerable questions. With both stages, the model achieves a balance. In tests on the HotpotQA benchmark, US-Tuned models reached 89.7% accuracy in recognizing uncertainty, compared to just 65.0% for baseline models. They also maintained strong performance on standard questions, scoring 72.3% accuracy.
Comparing Methods: Is US-Tuning Worth the Effort?
You might wonder if simpler methods work. There are several alternatives to US-Tuning, each with trade-offs. Let’s look at how they stack up against each other.
| Method | Uncertainty Recognition Accuracy | Standard QA Performance | Complexity & Cost |
|---|---|---|---|
| US-Tuning | 89.7% | 72.3% | High (Requires 2-stage training & custom data) |
| Baseline Instruction Tuning | 65.0% | 73.5% | Low (Standard QA datasets) |
| Self-Reflective Prompting | 58-76% (Variable) | Varies | Low (No training needed, just prompt changes) |
| SelfCheckGPT (Sampling) | 68.5% | High | Medium-High (3.2x more compute resources) |
As you can see, US-Tuning offers the best accuracy for recognizing when a model is unsure. However, it comes with a cost. Self-reflective prompting-asking the model “Are you sure?”-is easy to implement but inconsistent. Its accuracy swings wildly depending on the model architecture. SelfCheckGPT generates multiple responses to check for consistency, which is reliable but computationally expensive, requiring three times more processing power.
For high-stakes applications where accuracy is non-negotiable, US-Tuning is the clear winner. For casual chatbots, simpler prompting might suffice. But if you are building a medical assistant or a legal tool, the extra effort of US-Tuning pays off in safety.

Real-World Implementation: Challenges and Costs
Implementing US-Tuning isn’t as simple as flipping a switch. It requires significant resources. According to developer feedback from GitHub and Reddit communities in mid-2024, the biggest hurdle is data preparation. You need a balanced dataset of known and unknown questions. Constructing this dataset typically takes 4 to 6 weeks of manual annotation by human experts.
For a standard dataset of 50,000 examples, the cost ranges from $12,000 to $18,000. Small startups often struggle with this expense. One CTO noted that their three-person team spent six weeks just annotating data. However, the payoff is substantial. A medical Q&A system using US-Tuning saw false confidence in answers drop from 34% to 8.2%. Microsoft’s internal testing showed a 67.3% reduction in medically inaccurate responses after implementing similar uncertainty protocols.
There are also technical constraints. US-Tuning works best on large models with 7 billion parameters or more. On smaller models, the improvement is minimal, and the risk of “oversensitivity” increases. This means the model might refuse to answer questions it actually knows, frustrating users. This is why Stage 2 tuning is essential-it calibrates the model’s threshold for uncertainty.
The Future of Honest AI: Regulations and Trends
The push for uncertainty-aware AI is no longer just academic; it’s becoming regulatory. The EU AI Act, which took effect in February 2025, mandates “appropriate uncertainty signaling” for high-risk AI systems. This means companies deploying AI in healthcare, finance, or law must ensure their models can indicate when they are unsure. Gartner predicts that by 2026, 75% of enterprise AI deployments will require explicit uncertainty handling capabilities.
We are also seeing new developments in the technology itself. In January 2025, US-Tuning v2.1 was released, reducing dataset requirements by 35% through synthetic data generation. Major frameworks like Hugging Face’s Transformers library have integrated support for these methods. Meta AI is working on dynamic uncertainty thresholds, allowing models to adjust their caution based on the criticality of the context.
However, risks remain. Researchers warn of “uncertainty gaming,” where models learn to strategically say “I don’t know” to avoid difficult questions. This happened in 12.7% of test cases with improperly tuned implementations. Proper calibration is key. The goal isn’t to create a cowardly AI, but a trustworthy one.
What is the best way to stop an LLM from hallucinating?
The most effective method is Uncertainty-Sensitive Tuning (US-Tuning), a two-stage process that trains the model to recognize knowledge gaps and respond with “I don’t know” when appropriate. For simpler applications, self-reflective prompting (asking the model to verify its confidence) can help, though it is less consistent.
Does teaching an LLM to say “I don’t know” make it worse at answering questions?
It can, if done incorrectly. Single-stage training often causes models to become overly cautious, refusing to answer valid questions. This is why US-Tuning includes a second stage (Prompt-Sensitive Tuning) to restore performance on standard tasks while maintaining uncertainty awareness.
How much does it cost to implement US-Tuning?
Costs vary based on dataset size. A standard 50,000-example dataset requires 4-6 weeks of human annotation, costing approximately $12,000 to $18,000. Additionally, you need engineering time for implementation, typically 3-4 weeks for experienced ML engineers.
Which models benefit most from uncertainty tuning?
Models with 7 billion parameters or more show the most significant improvements. Smaller models often lack the capacity to learn nuanced uncertainty boundaries effectively, resulting in reduced effectiveness (15-18% lower accuracy) and higher rates of oversensitivity.
Is uncertainty handling required by law?
In some regions, yes. The EU AI Act, effective February 2025, requires high-risk AI systems to provide appropriate uncertainty signaling. This creates a compliance incentive for enterprises deploying AI in healthcare, legal, and financial sectors.
Marissa Haque
July 2, 2026 AT 02:41Oh my gosh! This is exactly what we needed to read today!! I have been so frustrated with AI making up facts!!! It’s like talking to a confident liar!!! The part about US-Tuning is just brilliant!!! We really need this in healthcare!!! Imagine if an AI told you the wrong diagnosis because it was trying too hard to be helpful!!! That would be terrifying!!! But knowing there is a way to teach them to say 'I don't know' gives me so much hope!!! Thank you for sharing this amazing info!!!
Keith Barker
July 3, 2026 AT 18:20the model does not lie. it predicts. the distinction is ontological.
Lisa Puster
July 4, 2026 AT 23:18another day another article written by people who think they understand technology but clearly dont. us-tuning is overhyped garbage. real engineers know that smaller models are fine and this two stage nonsense is just corporate bloat designed to sell more compute. stop letting these academic elites dictate how we build software. they have no idea what works in the real world outside their ivory towers.
Joe Walters
July 5, 2026 AT 20:44bro this post is insane lol i mean look at all those stats! 89.7% accuracy?? thats basically magic right there. i tried self-checkgpt once and my gpu caught fire lmao. honestly though the cost is wild. $18k for data annotation? thats a lot of money for just telling the ai to shut up when its confused. maybe ill stick to prompting it nicely until my pc explodes again.
Jeanne Abrahams
July 6, 2026 AT 11:50Here in South Africa, we are still trying to get reliable internet, let alone debating the nuances of LLM uncertainty tuning. While the EU runs off to regulate AI with their fancy new laws effective 2025, we are busy wondering if our power grid will survive the weekend. It is quite amusing watching the developed world panic over hallucinations while ignoring basic infrastructure failures. But sure, keep counting your tokens, folks.
Bineesh Mathew
July 6, 2026 AT 14:11The moral decay of society is mirrored in the silicon soul of these machines. When a model refuses to admit ignorance, it reflects our own collective denial of truth. We demand answers from the void, yet we punish the void for its silence. This US-Tuning is merely a bandage on a gaping wound of epistemological crisis. We are building gods that cannot confess their sins. How tragic. How utterly pathetic.