
Imagine you have built a brilliant assistant. It can write code, draft emails, and analyze data faster than any human. But then it accidentally shares a customer’s private phone number or gives financial advice that leads to a lawsuit. This is the reality many companies face when deploying Large Language Models (LLMs) without proper controls.
The solution isn’t just better training data; it is building robust guardrails. These are not simple filters. They are comprehensive systems of technical controls and policy frameworks designed to ensure generative AI operates within ethical, legal, and security boundaries. As we move through 2026, guardrails have evolved from theoretical safety concepts into critical infrastructure. They bridge the gap between raw model capabilities and enterprise-grade business tools, translating abstract organizational policies into concrete technical constraints.
Understanding the Core Architecture of LLM Guardrails
To design effective guardrails, you first need to understand how they work. The architecture operates through a continuous lifecycle with four distinct stages: design, implementation, enforcement, and auditing. Think of this as a loop rather than a straight line. Each stage informs the next, ensuring your AI system remains safe as it evolves.
1. Design: This is where stakeholders from legal, risk, compliance, and engineering collaborate. You map internal ethics standards and external regulatory obligations-such as the EU AI Act or NIST AI RMF-to specific model behaviors. For example, a healthcare provider might establish a policy stating, "AI agents must never dispense medical diagnoses." A financial institution might decree, "No customer data can leave the private cloud environment." This stage transforms subjective values into objective, measurable parameters.
2. Implementation: Here, high-level policy statements become machine-readable configurations. A guardrail security policy provides explicit instructions on which topics an LLM can discuss, what inputs are problematic, and how the system should respond to sensitive queries. Modern systems often use formats like YAML for structured, auditable configuration. This mirrors traditional Data Loss Prevention (DLP) systems, though current guardrail mechanisms are still maturing compared to decades-old DLP technologies.
3. Enforcement: This is the active phase. Real-time auditing mechanisms monitor every interaction. If a user attempts a prompt injection attack, the input guardrail triggers immediately, logs the attempt, and blocks the request. If the model generates output violating fairness metrics, the output guardrail intercepts it before delivery, replacing harmful text with a standardized error message.
4. Auditing: Enforcement feeds data into observability dashboards. Risk officers and compliance teams gain visibility into policy enforcement patterns, violation frequencies, and overall system safety metrics. This data is crucial for refining policies over time.
The Three Layers of Defense: Input, Output, and Context
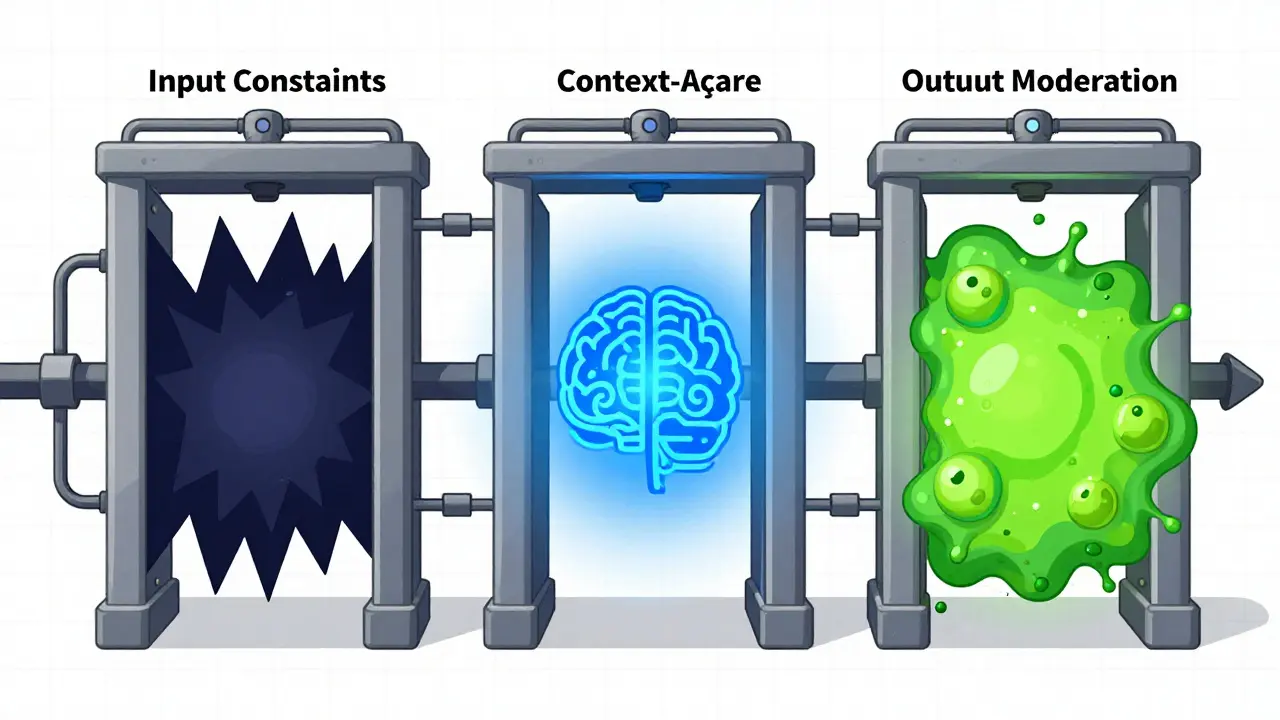
Effective enterprise AI governance relies on a layered defense strategy. Relying on a single type of check is risky. You need three distinct types of guardrails working together: input constraints, output moderation, and context-aware restrictions.
- Input Constraints: These function as the first line of defense. They filter or block problematic user inputs before they reach the model. This includes detecting and preventing prompt injection attacks, where users try to manipulate the model’s behavior by hiding malicious instructions in their queries. By stopping these at the door, you reduce the load on the model and prevent potential breaches.
- Output Moderation: This examines model-generated responses in real-time. It intercepts outputs that violate established fairness metrics, contain hallucinated information, leak Personally Identifiable Information (PII), or breach other safety policies. When a violation is detected, the system replaces the harmful text with a pre-configured safe response or error message. This ensures that even if the model makes a mistake, the end-user never sees the damage.
- Context-Aware Restrictions: These incorporate knowledge about the specific application environment, user context, and data flows. Instead of looking at isolated inputs and outputs, these restrictions consider the full operational environment. For instance, a guardrail might allow a senior executive to access certain strategic documents but block a junior intern from viewing the same data, even if the query looks identical.
Measuring Success: Key Guardrail Metrics
You cannot manage what you do not measure. Guardrail metrics serve as measurable indicators used to assess LLM outputs' safety, reliability, and security across multiple dimensions. Common metrics include:
- Detection Rates: How effectively does the system identify jailbreak attempts seeking to bypass restrictions?
- Toxicity Levels: What percentage of outputs contain harmful or offensive content?
- Hallucination Detection: How often does the model generate factually incorrect information?
- Faithfulness and Groundedness: Does the output align with the provided source data?
- Bias Detection: Are there disparities in how the model treats different demographic groups?
- Privacy Protection: How effective is the system in preventing PII leakage?
Consider a wealth management firm deploying a customer-facing chatbot. They configure guardrails to block any response resembling specific stock recommendations. Additionally, they implement fact-check guardrails that verify all numerical outputs against real-time market data APIs. If the data doesn’t match the verified source, the system defaults to the response, "I cannot provide real-time market data at this moment." This quantitative approach allows the firm to refine policies based on actual performance data.
Automating Policy Lifecycle Management
One of the biggest challenges in AI governance is keeping policies up-to-date. As applications change, old rules may become irrelevant or dangerous. Manual updates are slow and error-prone. This is where automated policy lifecycle management solutions come into play.
Solutions like ARGOS (as described in Pure Storage's framework) provide automated policy generation and continuous adaptation capabilities. ARGOS analyzes project artifacts, including product requirements documents and system design specifications, to automatically generate comprehensive draft policies in YAML format. When project artifacts are substantially modified-for example, when new features are added to PRDs-ARGOS automatically re-analyzes the updated documents and generates revised policies.
This ensures security controls evolve continuously with development velocity rather than becoming stale or misaligned with actual system capabilities. Once approved by human review, policies are operationalized through two deployment modes:
- Real-time Enforcement: Guardrails actively intercept activity and take configured actions (allow, log, block, or alert) when violations are detected.
- Offline Monitoring: Policies are applied to application logs for threat discovery and auditing without impacting real-time system performance.
However, policy definition accuracy presents significant technical challenges. LLM-generated policy drafts require rigorous human oversight to prevent hallucinations or misinterpretations of requirements. Systems might invent data security rules that were never actually specified in source documents. Therefore, enterprise guardrail solutions must incorporate formal methodologies for prompt engineering, evaluation, and testing to ensure generated policies accurately reflect organizational requirements.
Comparing Guardrail Implementation Approaches
The landscape of guardrail implementations varies significantly. Understanding these differences helps you choose the right tool for your needs. Here is a comparison of popular approaches as of early 2026:
| Platform | Approach | Flexibility | Key Strength |
|---|---|---|---|
| Granite Guardian 3.2 5B | Custom Model | Low | Highly specialized detection |
| WildGuard | Custom Model | Low | Open-source community support |
| Guardrails AI | Pydantic Validators | High | Type-based rules and flexibility |
Solutions like Granite Guardian 3.2 5B and WildGuard rely on custom models constrained by their training. This means modifying guardrail behaviors often requires complete retraining, which is resource-intensive and slow. In contrast, Guardrails AI employs Pydantic validators and type-based rules for more flexible policy implementation. This diversity reflects the emerging nature of the guardrail landscape, with no single dominant architectural pattern yet established across the industry.

Regulatory Compliance as a Driver
Regulatory compliance is no longer optional; it is a primary driver for guardrail deployment. The EU AI Act serves as the primary regulatory framework reshaping guardrail requirements globally as of February 2026. Organizations increasingly use guardrail systems to create automated, immutable audit trails that demonstrate compliance with high-risk AI regulations.
Multinational enterprises map their guardrails directly to EU AI Act requirements. They automatically log every instance where a high-risk guardrail is triggered, such as blocked attempts to infer biometric data. This creates documentation that satisfies regulatory audits without requiring manual spreadsheet compilation or emergency documentation efforts. This represents a fundamental shift from optional safety measures to mandatory compliance infrastructure in enterprise AI deployment.
Building Resilience Against Evolving Threats
The comprehensive safeguarding mechanism for LLMs encompasses techniques to evaluate, analyze, and enhance desirable properties including resistance to hallucinations, fairness in outputs, privacy protection, and security against various attack vectors. Research in this domain addresses both the techniques to circumvent existing controls through attacks and the defensive techniques to reinforce guardrails against such attacks.
The field requires a multidisciplinary approach incorporating neural-symbolic methods and systems development lifecycle principles. Current safeguarding mechanisms deployed by major LLM service providers and the open-source community form the foundation of guardrail implementations. Ongoing research efforts focus on enhancing their effectiveness against evolving attack techniques, such as sophisticated prompt injections that mimic legitimate user queries.
Enterprise adoption of guardrails has accelerated significantly in 2026. This is driven by the combination of regulatory requirements and the transition of LLMs from experimental chat interfaces to core business engines powering customer support agents, automated financial analysis, knowledge management systems, and other mission-critical applications. Organizations recognize that the gap between a raw, capable model and a compliant, safe business tool is substantial. Guardrails provide the necessary infrastructure to innovate with confidence while maintaining the ability to say no to risks.
Forward-thinking enterprise leaders now view AI guardrails not merely as safety nets but as essential translation layers between human intent and machine execution. They convert vague internal standards like "be polite" or "protect data" into hard technical constraints that models must respect. This represents a fundamental shift in how organizations approach AI governance, moving from post-deployment monitoring to pre-emptive policy enforcement.
What is the difference between input constraints and output moderation?
Input constraints act as the first line of defense, filtering or blocking problematic user inputs before they reach the model. This prevents issues like prompt injection attacks. Output moderation, on the other hand, examines the model-generated responses in real-time after the model has processed the input. It intercepts outputs that violate safety policies, such as containing hallucinated information or leaking PII, and replaces them with safe messages.
Why are guardrails considered critical infrastructure in 2026?
Guardrails have evolved from theoretical safety concepts to critical infrastructure because LLMs are now used in mission-critical applications like customer support and financial analysis. Regulatory frameworks like the EU AI Act mandate strict compliance, making guardrails essential for creating automated audit trails and ensuring legal and ethical operation.
How does automated policy lifecycle management work?
Automated policy lifecycle management uses tools like ARGOS to analyze project artifacts such as product requirements documents. It generates draft policies in formats like YAML. When project artifacts change, the system re-analyzes them and updates the policies accordingly. This ensures security controls evolve with development velocity and remain aligned with actual system capabilities.
What are the main challenges in defining accurate guardrail policies?
The main challenge is ensuring that LLM-generated policy drafts accurately reflect organizational requirements without hallucinating rules. Since LLMs are statistical models, they may invent data security rules not specified in source documents. Rigorous human oversight and formal methodologies for prompt engineering and testing are required to overcome this.
Which guardrail platforms offer the most flexibility?
Platforms like Guardrails AI offer high flexibility by employing Pydantic validators and type-based rules. In contrast, platforms like Granite Guardian 3.2 5B and WildGuard rely on custom models that require complete retraining to modify behaviors, making them less flexible for rapid policy changes.
Bhagyashri Zokarkar
May 3, 2026 AT 14:36honestly this whole guardrail thing feels like a massive overreaction to me because i just want my ai to help me write emails without feeling like im being watched by some invisible hand every single time i type something out and its really draining the joy out of using these tools when you have to worry about whether your prompt is too sensitive or not
it seems like we are building systems that are designed to fail us rather than help us and the constant need for audits and checks makes me feel like a criminal in my own workplace which is not a good vibe at all
plus who has time to read all those policy documents when you are just trying to get through the day and the idea that we need specialized models for every little rule change is just exhausting to think about
i miss the days when technology was simpler and didn't require a law degree to operate properly so maybe we should focus on making things easier instead of harder
Rakesh Dorwal
May 4, 2026 AT 04:21you people are sleeping on the real threat here because these western regulations like the EU AI Act are clearly designed to cripple our local innovation while they keep their own secrets hidden away from public scrutiny
they want us to use their platforms and follow their rules but they never talk about how much data is actually being harvested from our users for their own gain
we need to build our own sovereign AI infrastructure that does not rely on foreign frameworks or standards that might be compromised by outside interests
its obvious that the big tech companies are using these guardrails as an excuse to lock down competition and prevent smaller players from entering the market
stay woke and support local development instead of blindly following international guidelines that serve only the elite
Vishal Gaur
May 5, 2026 AT 19:18looks like another long article that says nothing new because everyone knows ai needs some sort of control but the way they explain it is so boring and full of jargon that nobody wants to read it
why do they always make everything so complicated with yaml files and pydantic validators when a simple if statement would work just fine for most cases
i tried setting up a basic filter once and it took me forever to figure out why it was blocking valid inputs so i gave up and just used a prebuilt solution instead
maybe if they focused less on theory and more on practical examples we could actually learn something useful from this post
also the table comparison is outdated already since new tools come out every week now
deepak srinivasa
May 6, 2026 AT 02:07the part about automated policy lifecycle management caught my attention because it seems like a smart way to handle the complexity of changing requirements
i wonder if there are any open source implementations of something like ARGOS that we can test locally before deploying it in production environments
it would be interesting to see how well these automated systems handle edge cases where the context is ambiguous or conflicting
has anyone here worked with Pydantic validators in a large scale deployment yet
i am curious about the performance overhead when you have multiple layers of validation running simultaneously on high traffic endpoints
NIKHIL TRIPATHI
May 7, 2026 AT 01:12i agree with the point about flexibility being key because rigid models become obsolete very quickly in this fast moving industry
we found that using a hybrid approach works best for us where we have strict rules for compliance related issues but allow more creative freedom for general tasks
this balance helps maintain safety without stifling productivity which is what most teams struggle with
the integration with existing CI/CD pipelines was smoother than expected thanks to the modular nature of the newer guardrail libraries
happy to share our config templates if anyone is interested in seeing how we structured the enforcement layer
Shivani Vaidya
May 7, 2026 AT 09:08thank you for sharing this detailed overview as it provides a clear perspective on the current state of enterprise AI governance
the emphasis on auditing and observability is particularly important for maintaining trust among stakeholders who may be skeptical about AI adoption
i believe that collaboration between legal and engineering teams will continue to grow stronger as regulations become more stringent
it is encouraging to see that the industry is moving towards standardized metrics for evaluating safety and reliability
let us hope that future developments prioritize both security and usability equally