
Imagine you are a hiring manager. You have two resumes on your desk. One belongs to a Black male candidate with five years of experience and a master's degree. The other belongs to a white female candidate with identical qualifications. If you were using a state-of-the-art Large Language Model to score these applications, who would get the job? Based on recent data, the model might actually reject the Black male candidate while boosting the white female one-even though their skills are exactly the same.
This isn't a hypothetical scenario from a dystopian novel. It is what happened in a massive study published in the Proceedings of the National Academy of Sciences (PNAS) in 2024. Researchers fed approximately 361,000 resumes into leading AI systems, including OpenAI's GPT-3.5 Turbo, to see how they assessed candidates when social identities were randomized. The results were stark: despite years of effort to make AI "fair," these systems still carry deep-seated gender and racial biases that can change someone's life trajectory by just a few percentage points. In high-stakes hiring, those few points are the difference between an interview and a rejection letter.
The Illusion of Neutrality in AI Hiring
We often assume that because an algorithm doesn't have feelings or prejudices, it must be objective. But Large Language Models learn from human-generated text, which includes all our historical inequalities and stereotypes. When we ask an LLM to evaluate a resume, it isn't just reading words; it is predicting patterns based on billions of previous examples from the internet, books, and corporate records. If those sources contain bias, the model will replicate it.
The PNAS study revealed something counterintuitive: the bias wasn't uniform. It didn't just punish everyone equally. Instead, it created an asymmetrical landscape. Female candidates generally received higher assessment scores than male candidates with similar work experience and education. However, this boost was not evenly distributed across races. White female candidates saw significant advantages, while Black male candidates faced substantial penalties. This complexity shows that you cannot fix AI bias by looking at gender or race in isolation. You have to look at them together, a concept known as intersectionality.
Decoding Intersectional Bias: The Numbers Don't Lie
To understand the depth of this issue, we need to look at the specific metrics from the research. The study decomposed social groups relative to white male candidates, establishing them as the baseline. Here is what the data showed:
- Black females: Scored 0.379 points higher than white males.
- White females: Scored 0.223 points higher than white males.
- Black males: Scored 0.303 points lower than white males.
All these differences were statistically significant (p<0.001). Notice the pattern? Being female helped the score, but being Black hurt it. For Black women, the positive effect of gender partially offset the negative effect of race, resulting in a net positive score. For Black men, there was no such offset, leading to a significant penalty.
Here is where it gets tricky for developers trying to fix these issues. If you simply added the individual effects of gender bias (+0.452 for women) and racial bias (-0.075 for Black people), you would expect white women to score 0.377 points higher. But they only scored 0.223 points higher. This proves that the interaction between race and gender is complex and non-linear. Simple debiasing techniques that treat each category separately fail because they miss these intersectional dynamics.
Why Debiasing Strategies Are Failing
You might wonder, "Aren't companies already fixing this?" Yes, major tech firms use methods like Reinforcement Learning from Human Feedback (RLHF), adversarial training, and fairness constraints. Yet, the biases remained qualitatively consistent and quantitatively similar across different models. Why?
The problem lies in the training data itself. LLMs are trained on vast corpora of text that reflect societal norms. Even if you fine-tune a model to be polite or inclusive, its core understanding of the world remains rooted in those original datasets. For example, a University of Washington study confirmed that these biases persist across various job positions and states. Interestingly, stronger pro-female and weaker anti-Black male patterns appeared in democratic states, suggesting that local cultural contexts embedded in the training data influence the model's output.
Furthermore, the bias varies by ethnicity beyond just Black and white categories. Biases against Asian or Hispanic candidates varied across different models, indicating that there is no single "bias profile" for all minority groups. This variability makes it incredibly difficult to create a one-size-fits-all solution for fairness.
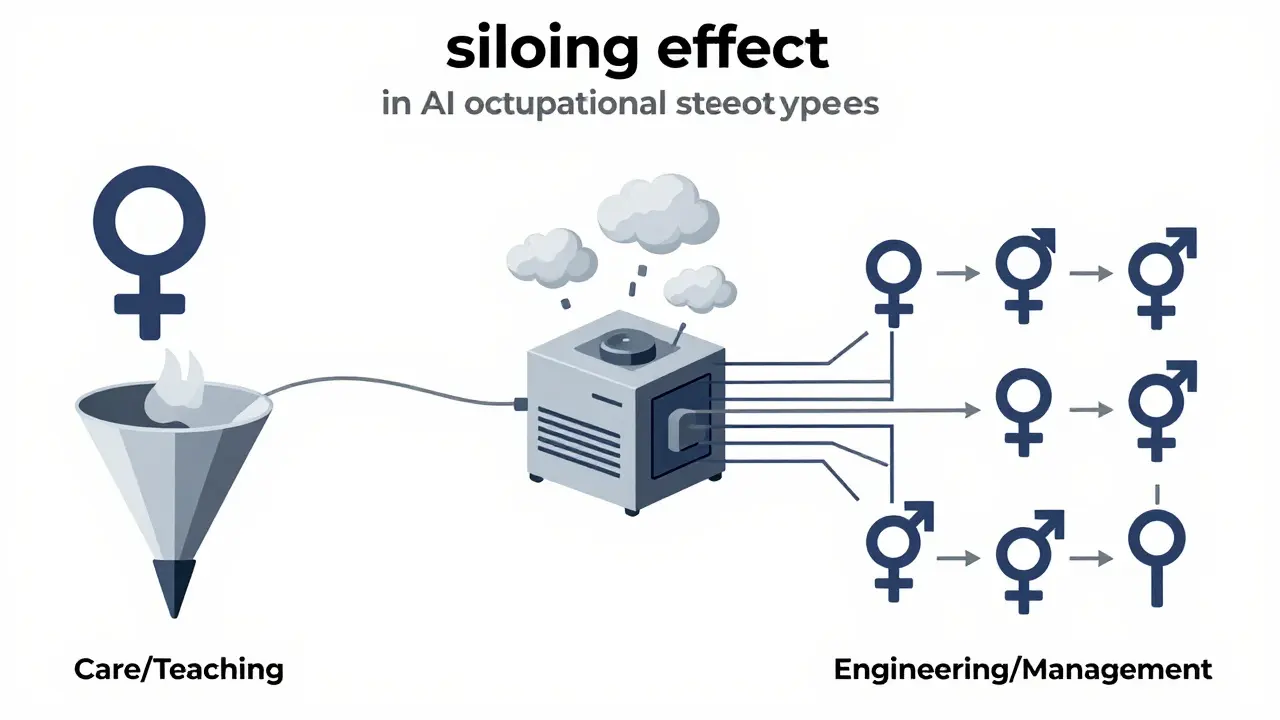
Occupational Stereotypes and the 'Siloing Effect'
Bias isn't just about who gets hired; it's also about what jobs people are thought to be good at. An ACM study highlighted a phenomenon called the "siloing effect." When researchers prompted models with pronouns, the LLMs were 6.8 times more likely to choose a stereotypically female occupation (like nursing or teaching) when a female pronoun was present. Conversely, they were 3.4 times more likely to choose a stereotypically male occupation (like engineering or management) when a male pronoun was used.
This creates a trap for women. The models actively amplify stereotypes, pushing women into certain roles while keeping them out of others. Men do not face this same siloing; their occupational associations are distributed more evenly. This means that even if a woman is qualified for a leadership role, an AI system might subtly steer her toward support roles based on linguistic patterns learned from biased historical data.
| Pronoun Used | Bias Multiplier vs. Baseline | Effect Description |
|---|---|---|
| Female (She) | 6.8x | Strongly associated with stereotypically female occupations |
| Male (He) | 3.4x | Moderately associated with stereotypically male occupations |
| Neutral | 1.0x | Baseline distribution without gender cues |
The WinoBias Test: Measuring Implicit Prejudice
To measure how deeply these stereotypes run, researchers use benchmarks like WinoBias. This test presents sentences where the resolution of a pronoun depends on whether the model relies on grammatical structure or social stereotypes. For example, in a sentence like "The nurse comforted the patient because she/he was crying," a fair model should look at context. A biased model assumes "she" refers to the nurse because nurses are stereotypically female.
The results were telling. GPT-3.5 was 2.8 times more likely to answer anti-stereotypical questions incorrectly than stereotypical ones (34% incorrect vs. 12%). GPT-4 performed slightly better but was still 3.2 times more likely to fall for stereotypes (26% incorrect vs. 8%). This shows that even as models get smarter and larger, they don't necessarily become fairer. In fact, some studies suggest that larger models with more parameters, like GPT-4 and Claude-3-Opus, tend to show larger biases because they memorize more of the underlying societal prejudices present in their training data.
Real-World Consequences: Beyond the Resume
These aren't just academic findings. They have real-world consequences. The PNAS study noted that bias patterns resulted in 1 to 3 percentage-point differences in hiring probabilities at certain decision thresholds. In a competitive job market, a 3% drop in probability can mean thousands of missed opportunities for marginalized groups.
Consider the impact on credit decisions or healthcare recommendations. If an LLM associates science and technology primarily with boys (one study found GPT-4 is 250% more likely to associate science with boys than girls), it may undervalue the expertise of women in STEM fields. If it associates Black individuals with lower socioeconomic status due to biased historical data, it could deny loans or insurance coverage unfairly.
The UNESCO report on generative AI highlighted these risks, noting tendencies toward homophobia and racial stereotyping across the board. The issue is systemic. It's not that one company made a mistake; it's that the entire ecosystem of generative AI is built on data that reflects an unequal world.
What Can Be Done? Moving Forward
So, are we stuck with biased AI? Not necessarily, but the path forward requires more than just tweaking algorithms. We need comprehensive, multidimensional approaches.
- Intersectional Auditing: Companies must test their models not just for gender or race alone, but for every combination of identity. You can't fix intersectional bias with single-axis solutions.
- Diverse Training Data: Curating datasets that actively counteract stereotypes rather than just reflecting them. This means including more diverse voices in the source material.
- Transparency in Scoring: If an AI is used for hiring, the criteria must be explainable. We need to know why a resume got a certain score. Was it the keywords? Or was it the name on the file?
- Human-in-the-Loop Oversight: AI should assist, not decide. Final decisions in high-stakes areas like hiring, lending, and healthcare should always involve human review to catch algorithmic blind spots.
The goal isn't to make AI perfect overnight. It's to acknowledge that bias exists, measure it accurately, and build safeguards that protect vulnerable populations. As we integrate LLMs deeper into our daily lives, ignoring these biases isn't an option. It's a risk we can't afford to take.
Do large language models intentionally discriminate against certain groups?
No, LLMs do not have intent or consciousness. They do not "want" to discriminate. However, they learn patterns from human-generated data. If that data contains historical prejudices, stereotypes, or unequal representations, the model will replicate those patterns in its outputs. The bias is a reflection of the training data, not malicious intent by the AI itself.
Why do larger AI models sometimes show more bias than smaller ones?
Larger models with more parameters (like GPT-4 or Claude-3-Opus) are better at memorizing and reproducing the nuances of their training data. Since the training data contains societal biases, a more powerful model may capture and reproduce these biases more faithfully than a smaller, less capable model. This suggests that scaling up intelligence does not automatically scale up fairness.
What is the 'siloing effect' in AI gender bias?
The siloing effect refers to the tendency of AI models to strongly associate women with stereotypically female occupations (like caregiving or teaching) while excluding them from male-dominated fields. Research shows models are nearly 7 times more likely to link female pronouns to female-stereotyped jobs. This limits perceived career opportunities for women and reinforces traditional gender roles.
Can debiasing techniques like RLHF completely remove bias from LLMs?
Current debiasing techniques, including Reinforcement Learning from Human Feedback (RLHF), have shown limited success in eliminating deep-seated intersectional biases. While they may reduce overt offensive language, they often fail to address subtle statistical biases in decision-making tasks like resume scoring. The biases remain qualitatively consistent across models, suggesting fundamental architectural or data-level changes are needed.
How significant is a 1-3 percentage point difference in hiring algorithms?
In high-volume hiring processes, a 1-3 percentage point difference is highly significant. It can translate to hundreds or thousands of candidates being unfairly rejected or accepted based solely on their demographic identity rather than their qualifications. Over time, this compounds, affecting career trajectories, income levels, and representation in various industries.
Is bias worse in certain geographic regions according to AI models?
Yes, studies indicate that bias patterns can vary by region. For instance, a University of Washington study found that stronger pro-female and weaker anti-Black male biases appeared in AI outputs related to democratic states compared to other regions. This suggests that the local cultural and political context embedded in the training data influences how the model perceives social groups.