Imagine hiring a specialist for every single job in your company. You’d need a separate expert for customer support, another for legal review, and yet another for data analysis. It’s expensive, it’s slow, and managing them is a nightmare. Now imagine one employee who can handle all three roles with equal skill. That is the promise of multi-task fine-tuning, an advanced technique where a single pre-trained large language model (LLM) is simultaneously trained on multiple related tasks to develop diverse capabilities within one unified architecture.
For years, developers treated AI like those specialists. If you wanted a model to summarize text, you fine-tuned it for summarization. If you wanted it to classify sentiment, you trained a completely different version. This approach works, but it wastes massive amounts of computational power and creates a fragmented ecosystem of models that are hard to maintain.
Multi-task fine-tuning changes the game. By teaching a model several skills at once, researchers have discovered something unexpected: the model doesn’t just learn each task; it gets better at *all* of them. This phenomenon, known as the "cocktail effect," means the whole becomes greater than the sum of its parts. In this guide, we’ll break down how this technology works, why it’s becoming the industry standard in 2026, and how you can implement it without breaking the bank.
The Cocktail Effect: Why More Tasks Mean Better Performance
You might think that asking an AI to do too many things would confuse it. After all, humans struggle when we multitask. But LLMs operate differently. When a model learns related tasks simultaneously, it builds richer internal representations of language and logic.
A pivotal study published in October 2024 (arXiv:2410.01109v1) put this theory to the test. The researchers trained exactly 220 models across various financial benchmarks. They compared single-task fine-tuning against multi-task approaches. The results were striking. The multi-task models showed a 12.7% average performance improvement across six financial tasks compared to their single-task counterparts.
This isn't just about raw accuracy. It’s about synergy. For example, training a model on both "Headline Generation" and "Twitter Sentiment Analysis" helped it understand stylistic nuances better than if it had only learned one. The model gained an 18.4% improvement in tasks requiring stylistic interpretation because the skills reinforced each other.
Even more impressive? Smaller models are beating larger ones. The study demonstrated that a 3.8B parameter model like Phi-3-Mini, when properly multi-task fine-tuned, could surpass significantly larger models such as GPT-4-o on specific domain benchmarks. This represents a paradigm shift: you no longer need billion-dollar infrastructure to get enterprise-grade performance. You just need the right training strategy.
How It Works: Adapters and Routing
If multi-task learning is so good, why wasn’t everyone doing it earlier? The main problem was "task interference." When you train a model on Task A and then Task B, the weights adjusted for Task A often get overwritten by Task B. This is called catastrophic forgetting. The model forgets how to summarize while learning how to classify.
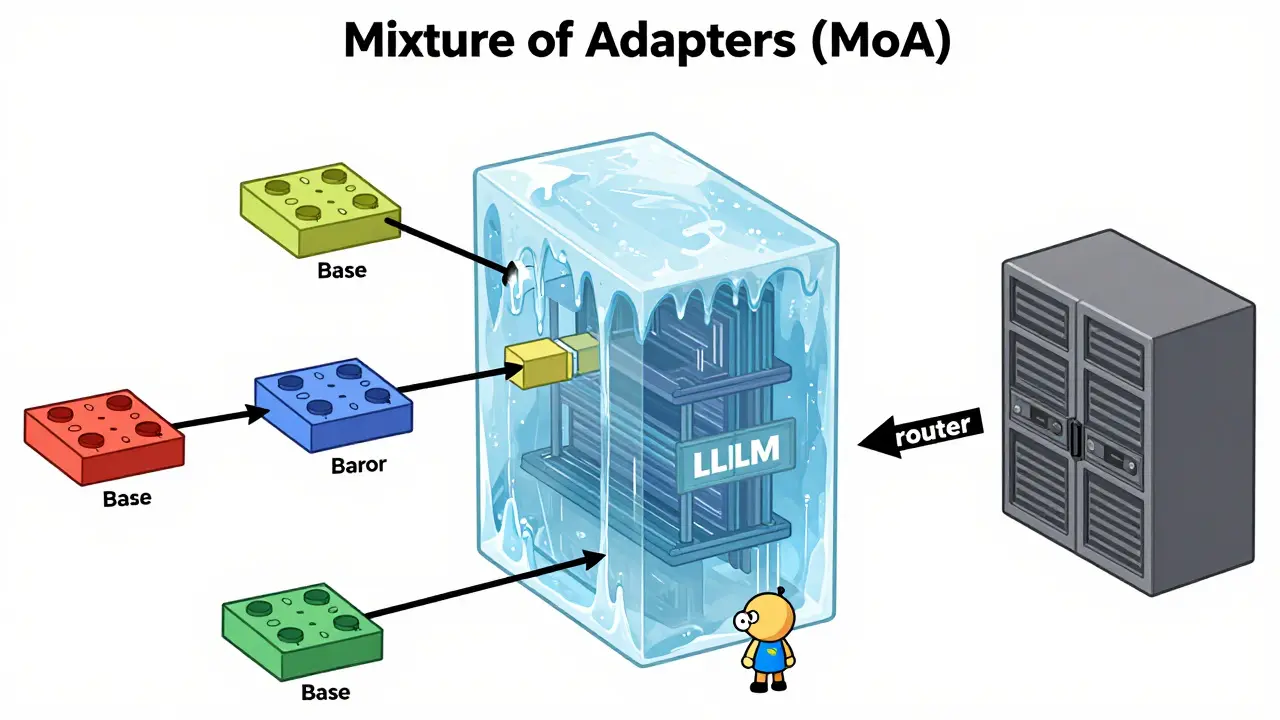
The solution lies in parameter-efficient tuning methods, specifically the Mixture of Adapters (MoA) architecture introduced in the LREC 2024 proceedings. Here’s how it simplifies the process:
- Low-Rank Adaptation (LoRA): Instead of retraining the entire model (which has billions of parameters), you add small, lightweight modules called adapters. These adapters contain only a fraction of the parameters but capture the specific knowledge needed for a task.
- Explicit Routing: The MoA system includes a "router"-a small neural network that decides which adapter to use for a given input. If you ask a question about finance, the router directs the query to the finance-specific adapter. If it’s a creative writing prompt, it routes to the creative adapter.
- Shared Backbone: The core language model remains frozen or lightly tuned. It provides the general understanding of language, while the adapters provide the specialized expertise.
This architecture allows the model to expand its capabilities iteratively. You can add a new domain by training a new LoRA module without disturbing the existing ones. According to Stanford University research (CS224N, 2023), this approach allows a model with 110 million shared parameters to achieve reasonable accuracy across three diverse tasks, whereas creating separate models would require approximately 330 million parameters total.
Implementation Strategy: Data and Sampling
Knowing the theory is one thing; getting it to work is another. Multi-task fine-tuning requires careful attention to how you feed data into the model. If you mix datasets randomly, you risk overfitting on smaller tasks or underperforming on complex ones.
Here are the critical components for successful implementation:
1. Sampling Strategies
Not all sampling methods are created equal. The Stanford research team found that "round-robin" sampling (taking one batch from Task A, then one from Task B, etc.) tends to cause overfitting on tasks with smaller training sets. Instead, they recommend anneal sampling. This method gradually adjusts the proportion of data from different tasks during training. Early on, the model sees more balanced data to learn general patterns. Later, it focuses more on the harder or smaller tasks to refine performance. This helps the model generalize well and avoid getting stuck in local minima.
2. Hyperparameter Tuning
The SuperAnnotate 2025 guide highlights that hyperparameters are the make-or-break factor. You aren’t tweaking these wildly, but precision matters:
| Parameter | Recommended Range | Purpose |
|---|---|---|
| Learning Rate | 2e-5 to 5e-5 | Controls step size during optimization; too high causes instability. |
| Batch Size | 16 to 64 | Depends on model size; larger batches offer smoother gradients. |
| Epochs | 3 to 10 | Limited epochs prevent overfitting; monitor validation loss closely. |
| Weight Decay | 0.01 to 0.1 | Regularization term to keep weights small and generalizable. |
3. Regularization with General Data
A common pitfall is losing the model’s general knowledge. To prevent this, include a portion of general instruction data in your training mix. The arXiv:2410.01109v1 research showed that incorporating general data acts as a regularizer, minimizing performance degradation on non-target tasks. Additionally, adding mathematical data can improve numerical reasoning, which transfers effectively to domains like finance.

Choosing the Right Tasks: The Art of Combination
Not all tasks play nice together. Multi-task fine-tuning excels when tasks share underlying semantic structures. For instance, financial analysis tasks like ConvFinQA (conversation-based question answering) and earnings report summarization benefit from each other because they both require understanding numerical context and professional tone.
However, combining completely unrelated tasks-say, poetry generation and medical diagnosis-can lead to interference rather than synergy. The arXiv study tested 42 distinct task combinations before identifying the top performers. Their advice? Start with tasks that have overlapping vocabularies or logical requirements.
If you’re unsure, use a heuristic: ask yourself if a human expert skilled in Task A would likely be competent in Task B. If yes, they’re probably good candidates for multi-task training. If no, consider keeping them separate or using a stronger routing mechanism.
Ethical Considerations and Bias
As with any AI advancement, multi-task fine-tuning comes with responsibilities. Dr. Emily Bender from the University of Washington warned in a December 2024 AI Ethics Forum presentation that "without careful task selection, multi-task fine-tuning can inadvertently reinforce biases present across multiple datasets."
When you combine datasets, you also combine their flaws. If your customer service data contains biased responses and your legal data contains outdated precedents, the model will learn both. The NIH review authors emphasized that "careful tuning of hyperparameters guarantees that the model learns efficiently and does not overfit when applied to new data," but this doesn’t automatically fix ethical issues.
To mitigate this, audit your datasets individually before merging them. Use tools to detect demographic or linguistic biases. And always evaluate your final model on a diverse set of edge cases, not just the average scenarios.
Market Adoption and Future Outlook
The industry is moving fast. As of Q3 2024, 17 of the top 50 global banks were actively experimenting with multi-task approaches for specialized financial analysis. Google Cloud reported a 40% year-over-year increase in customer implementations of multi-task techniques by January 2025. Industry analysts at Gartner predict that by 2026, 65% of enterprise LLM deployments will utilize multi-task fine-tuning.
Why the rush? Cost efficiency. Maintaining five separate specialized models is expensive in terms of storage, inference compute, and engineering time. One multi-task model does the job of five, often with better performance. Plus, the emergence of open-source frameworks like FinMix (announced for Q1 2025 release) lowers the barrier to entry, allowing smaller teams to access state-of-the-art configurations.
Looking ahead, the next major advancement will involve dynamic task routing that adapts in real-time based on user input characteristics. Prototype implementations are expected by late 2025, promising even more seamless interactions.
Getting Started: Your Action Plan
Ready to try multi-task fine-tuning? Here’s a simplified roadmap:
- Select a Base Model: Choose a robust open-source LLM like Llama 3 or Mistral. Ensure it has strong general capabilities.
- Identify Related Tasks: Pick 2-3 tasks that share semantic overlap. Avoid mixing highly disparate domains initially.
- Prepare Datasets: Clean and format your data. Ensure balance between tasks or plan for anneal sampling.
- Choose a Framework: Use libraries like Hugging Face Transformers with PEFT (Parameter-Efficient Fine-Tuning) support. Look for MoA or similar adapter implementations.
- Configure Hyperparameters: Start with the recommended ranges above. Set up monitoring for validation loss per task.
- Train and Evaluate: Run your training loop. Evaluate not just on aggregate metrics, but on each individual task to ensure no negative transfer occurred.
Multi-task fine-tuning isn’t just a technical upgrade; it’s a strategic advantage. It allows you to build smarter, leaner, and more versatile AI systems. By leveraging the cocktail effect and modern adapter architectures, you can achieve performance that rivals much larger models, all while maintaining control over your data and costs.
What is the difference between multi-task fine-tuning and single-task fine-tuning?
Single-task fine-tuning trains a model on one specific dataset for one purpose, optimizing it solely for that task. Multi-task fine-tuning trains the same model on multiple related datasets simultaneously. This allows the model to share learned features across tasks, often leading to better generalization and higher overall performance due to synergistic effects, known as the 'cocktail effect.'
Do I need a powerful GPU to perform multi-task fine-tuning?
Not necessarily. Because multi-task fine-tuning often uses parameter-efficient methods like Low-Rank Adaptation (LoRA), you only update a small fraction of the model's parameters. This significantly reduces memory requirements compared to full fine-tuning, making it feasible on consumer-grade GPUs or cloud instances with moderate resources.
What is the 'cocktail effect' in AI training?
The 'cocktail effect' refers to the phenomenon where training a model on a strategic combination of related tasks produces performance improvements that exceed what would be expected from training on each task individually. The tasks reinforce each other, leading to synergistic gains in accuracy and reasoning capabilities.
Can multi-task fine-ting cause the model to forget previous knowledge?
Yes, this is known as catastrophic forgetting or task interference. However, modern architectures like Mixture of Adapters (MoA) mitigate this by using separate adapter modules for different tasks and a router to direct queries appropriately. Additionally, including general instruction data during training helps preserve the model's foundational knowledge.
Is multi-task fine-tuning suitable for completely unrelated tasks?
It is generally less effective for completely unrelated tasks. Multi-task learning thrives on semantic overlap. If tasks share vocabulary, structure, or logical reasoning patterns, the model benefits from shared representations. For unrelated tasks, the lack of synergy may lead to interference, and separate models or very robust routing mechanisms might be necessary.
What are the best practices for sampling data in multi-task training?
Avoid simple round-robin sampling, which can lead to overfitting on smaller datasets. Instead, use anneal sampling, which gradually adjusts the proportion of data from different tasks during training. This helps the model learn general patterns early on and refine specific skills later, improving overall generalization.