
Imagine you're using an AI assistant to write a complex legal brief. You hit enter and... nothing. For thirty seconds, the screen is blank. Then, suddenly, five paragraphs of perfectly formatted text slam onto the page at once. Now, imagine the same scenario, but the AI starts typing word-by-word in real-time. You see the thought process unfolding. Which one feels faster? Which one feels more reliable? This is the core tension between generative AI streaming is a method of delivering LLM responses token-by-token as they are generated and batch processing.
While streaming is the industry standard for chatbots, it introduces a hidden psychological and technical risk: the temptation to trust a response before it's actually finished. When an AI streams, it's making bets on the next word without knowing how the sentence ends. This can lead to a specific type of Hallucination, where the model commits to a fact in the first few tokens and then spends the rest of the response trying to justify that mistake. In a batch response, the model has the luxury of "thinking" through the entire output before the user ever sees a single character.
The Mechanics of Response Delivery
To understand the trade-offs, we have to look at how these two systems handle data. A Batch Response works like a traditional web request. The client sends a prompt, the server processes the entire sequence, and only when the full stop is reached does it send the package back. It's an all-or-nothing game. If the connection drops at 99%, you get zero words.
Streaming, on the other hand, utilizes Server-Sent Events (SSE) or WebSockets. Instead of one giant payload, the server sends a series of small chunks called tokens. This drastically reduces the perceived latency. Even if the total time to generate the full answer is the same, the user feels the system is responsive because the "Time to First Token" (TTFT) is measured in milliseconds rather than seconds.
| Feature | Streaming Response | Batch Response |
|---|---|---|
| Perceived Speed | Near-instant (Low TTFT) | Slow (High TTFT) |
| Accuracy Control | Harder to post-process | High (Allows full validation) |
| UX Feel | Conversational/Dynamic | Static/Document-like |
| Error Handling | Partial outputs possible | Atomic (Success or Failure) |
Impact on Accuracy and the Hallucination Loop
There is a common misconception that streaming changes how the model "thinks." It doesn't. The Transformer Architecture generates tokens sequentially regardless of how they are delivered. However, the delivery method fundamentally changes the accuracy guardrails you can apply.
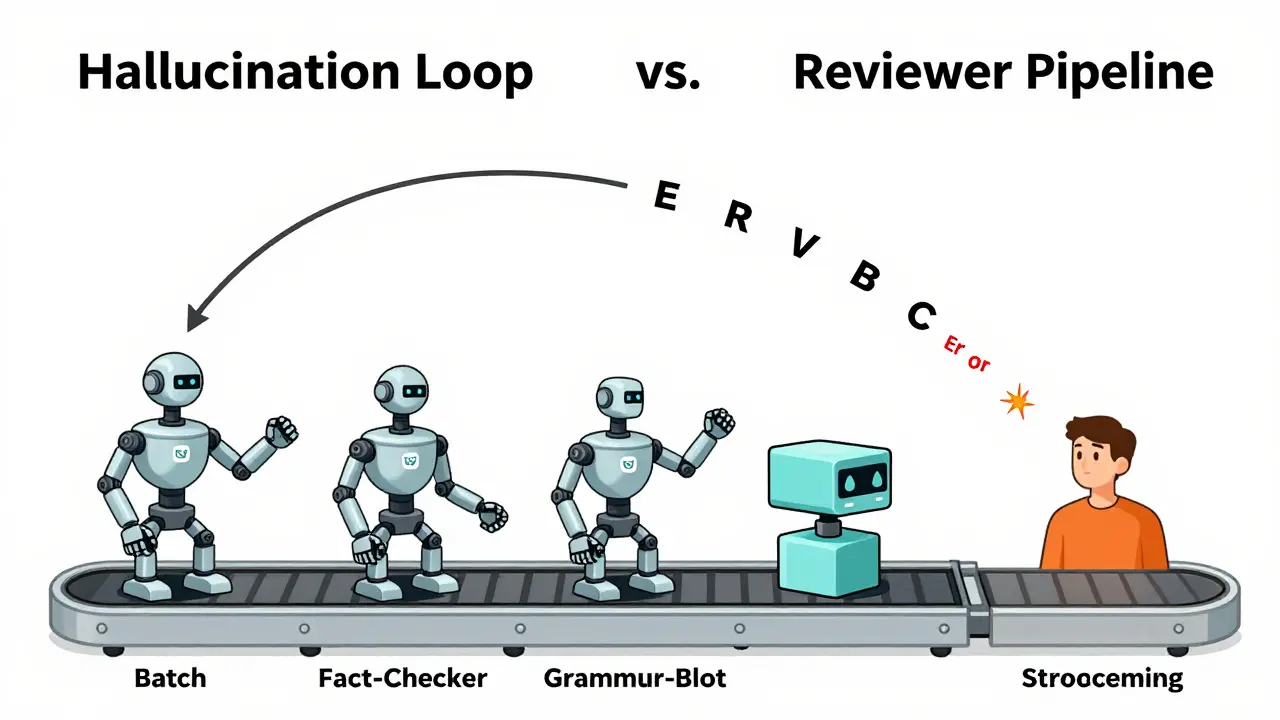
In a batch system, you can implement a "Reviewer" agent. The primary model generates the answer, a second model checks it for hallucinations, and a third model cleans up the grammar-all before the user sees anything. This creates a multi-step verification pipeline that significantly boosts reliability. You can run a full programmatic check against a database to ensure a cited date is correct. If the check fails, the system can regenerate the response silently.
With streaming, you are essentially "flying blind." Once the first token is sent to the user's screen, you cannot take it back. If the model starts a sentence with "The capital of France is Berlin," and you realize it's wrong three tokens later, the damage to user trust is already done. You can't simply erase the text from the user's browser without creating a jarring, glitchy experience. This is why streaming is risky for high-stakes data-like medical advice or financial auditing-where a single wrong word is a critical failure.
The User Experience Paradox
Why do we keep using streaming if it's riskier? Because humans hate waiting. In UX design, there is a massive difference between a 5-second wait for a result and a 5-second window of seeing a result emerge. Streaming mimics human conversation. It creates a psychological connection and keeps the user engaged.
But there's a downside: cognitive overload. When a user reads a streaming response, they are processing information in fragments. This often leads them to skim or misinterpret the AI's point because they are reacting to the words as they appear, rather than analyzing the completed argument. If the AI changes its tone or direction halfway through a streamed paragraph, the user might feel a sense of inconsistency that wouldn't be as apparent in a polished batch delivery.
Consider a coding assistant. If the AI streams a block of code, the developer might start reading and mentally debugging the first three lines before the remaining twenty lines-which might contain a much simpler solution-even appear. This creates a "race condition" in the human brain, where we attempt to solve a problem with incomplete information.
Choosing the Right Approach for Your Use Case
Deciding between these two isn't about which is "better," but about what the user is actually trying to do. You have to map the delivery method to the Job-to-be-Done.
- Conversational Interaction: If the goal is brainstorming, chatting, or creative writing, streaming is non-negotiable. The fluidity of the interaction is more important than a 2% increase in factual precision.
- Data Extraction & Analysis: If you are asking an AI to summarize a 50-page PDF or extract specific entities from a contract, use batch. The user needs a final, verified document, not a live-typed stream of a summary that might contradict itself.
- Code Generation: A hybrid approach often works best here. Stream the explanation of the code to keep the user engaged, but deliver the actual code block as a batch once it has been passed through a basic syntax validator.
- Automated Workflows: For API-to-API communication, batch is the only logical choice. A downstream system cannot "read" a stream; it needs a complete JSON object to trigger the next action in the pipeline.
The Middle Ground: Buffered Streaming
Some sophisticated systems use a technique called "buffered streaming." Instead of sending every single token immediately, the server collects a small group of tokens (perhaps a full sentence or a logical phrase) and sends them in small bursts. This gives the system a tiny window to perform basic sanity checks or formatting fixes without making the user wait for the entire response.
Another approach is the "Optimistic UI" pattern. The system shows a loading state that simulates progress, then delivers the response in larger, logically grouped chunks. This balances the need for immediate feedback with the requirement for higher structural integrity. By grouping tokens, you reduce the number of HTTP requests and provide a more stable reading experience.
Does streaming actually make the AI hallucinate more?
No. The model's internal logic for generating tokens is identical whether the response is streamed or batched. However, streaming prevents you from using "post-generation" filters or verification agents that can catch and correct hallucinations before the user sees them.
Which method is more expensive to implement?
Streaming is generally more complex to implement. It requires managing persistent connections (like WebSockets or SSE) and handling potential interruptions in the stream. Batch responses use standard REST API patterns, which are simpler and more widely supported by basic infrastructure.
How does streaming affect Time to First Token (TTFT)?
Streaming drastically improves TTFT. In a batch system, TTFT is equal to the total generation time. In a streaming system, TTFT is the time it takes for the model to produce the very first token, usually meaning the user sees activity within milliseconds.
Can I use streaming for high-accuracy financial data?
It is not recommended. For high-stakes data, the risk of a "committed error" (where the AI starts with a wrong number and cannot correct it mid-stream) is too high. Batch processing allows you to run the output through a verification layer to ensure 100% accuracy against a source of truth.
What happens if a stream is interrupted?
If a stream is cut off, the user is left with a partial, often fragmented response. The application must have logic to either retry the request from the beginning or, in more advanced cases, resume from the last successfully received token.
Next Steps for Implementation
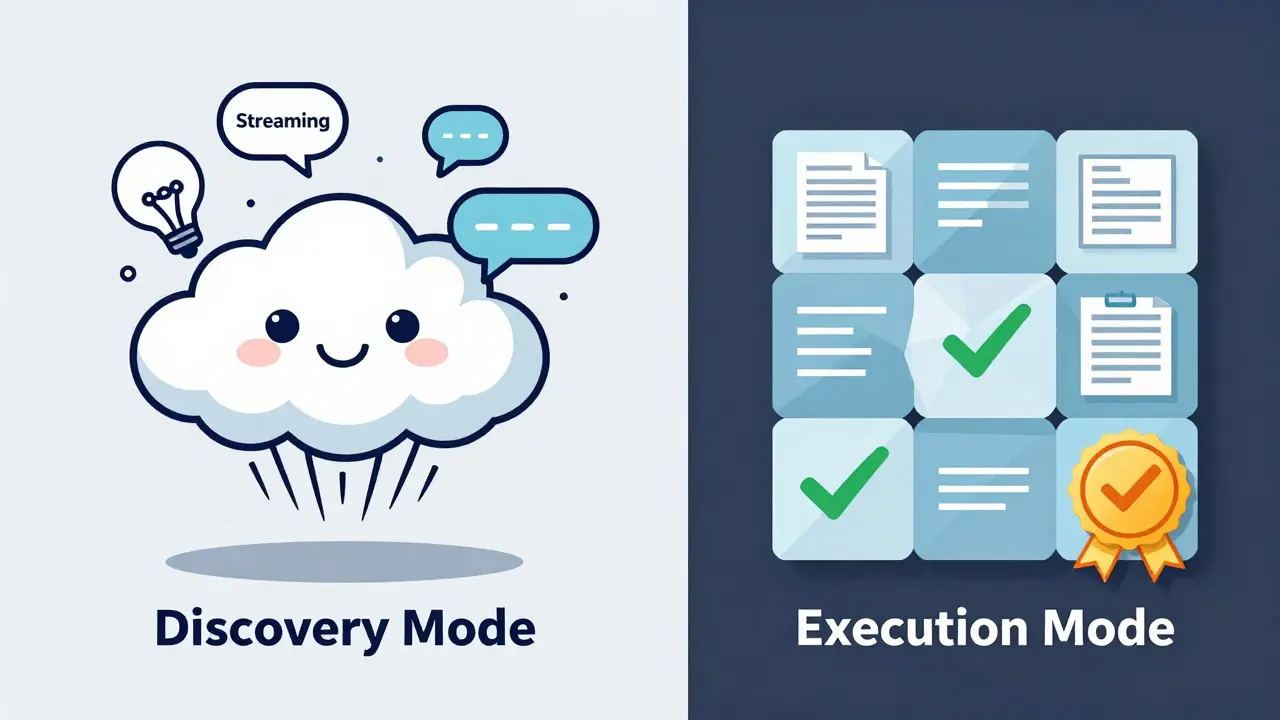
If you are building an AI-powered product today, don't default to streaming just because ChatGPT does it. Start by auditing your users' intent. If they are in "discovery mode" (exploring, chatting, brainstorming), lean into streaming to maintain the flow. If they are in "execution mode" (extracting data, generating reports, auditing code), switch to batch processing.
For those who need both, consider a toggle in your settings. Power users often prefer a fast, raw stream, while enterprise users paying for accuracy may prefer a "Verified Response" mode that uses batch processing and a secondary validation agent to ensure the output is hallucination-free.
Scott Perlman
April 15, 2026 AT 04:39this is a great way to think about it
Buddy Faith
April 15, 2026 AT 13:28streaming is just a trick to make us think the ai is actually thinking in real time but it is probably just a script feeding us pre written bits to keep us docile while they harvest our data in the background the whole thing is a psyop to hide how slow these models actually are
Sandi Johnson
April 16, 2026 AT 11:21oh wow truly a revolutionary discovery that people hate waiting for things’ someone give this person a gold medal for figuring out basic human psychology
Eva Monhaut
April 17, 2026 AT 01:02The way this breaks down the duality of perception versus precision is absolutely luminous. It is such a vibrant reminder that the architecture of our interfaces fundamentally shapes the tapestry of our trust in these digital minds. I love how this encourages a more mindful approach to tool selection
Ian Maggs
April 18, 2026 AT 21:23One must wonder,,, if the "perceived latency" is actually a mirror,,, of our own fragmented attention spans??? Are we sacrificing the ontological truth of a complete thought,,, for the dopamine hit of a flickering cursor??? Truly... a tragedy of the modern era!!!
Ronnie Kaye
April 19, 2026 AT 19:14Yeah because nothing says "high quality professional work" like a piece of software that stutters like a broken record while it tries to remember what it was saying mid-sentence. Absolutely peak efficiency right there
Tony Smith
April 20, 2026 AT 03:58It is profoundly heartwarming to see such an enthusiastic embrace of mediocrity in the current industry standards. I am simply breathless with admiration for the sheer audacity of deploying unverified streams to unsuspecting users while pretending it is a "feature." Truly, a masterclass in corporate optimism
Rakesh Kumar
April 20, 2026 AT 14:40Wait this is absolutely wild! I never even considered that the AI might be "committing" to a lie just because it already typed the first word! That is honestly terrifying and brilliant at the same time! I need to rethink every single prompt I have ever written in my life!
Priyank Panchal
April 20, 2026 AT 17:13Stop wasting time with this fluff. Either the model is accurate or it is not. The delivery method is a UI distraction and discussing it as a "tension" is a complete waste of intellectual energy. Get to the point or stop posting
Bill Castanier
April 22, 2026 AT 09:56Very clear breakdown. The hybrid approach for code is a smart move. Keep it up